Gutenberg: Are gutenblocks saved as a separate fields, or is it all saved in the content?
When working on decoupled WordPress - WordPress as a content provider (model + controller), and some library on the front for the view part (Angular, React, Vue, etc.), most of the time you don't want to dangerouslySetInnerHTML to provide the content, and it seems like the only way to actually deliver the content to the frontend (via REST API).
The case I had in mind is when I am linking other pages in my content, I don't want an anchor HTML element because that triggers a full page reload.
Instead, the better way is to have a Link component from a router that will handle the routing of the front end app.
For that to happen, some kind of content parsing would be needed.
I'm not sure whether the Gutenberg saves the individual fields for every gutenblock somewhere, or is there a way to do that with Gutenberg somehow.
From what I've poked around, all it does is parse gutenblocks in html and stores that in the post_content table.
It would be useful to have the extra control of how I'm serving the content to the front end app (JSON fields would be ideal).
So the page in the admin looks like this
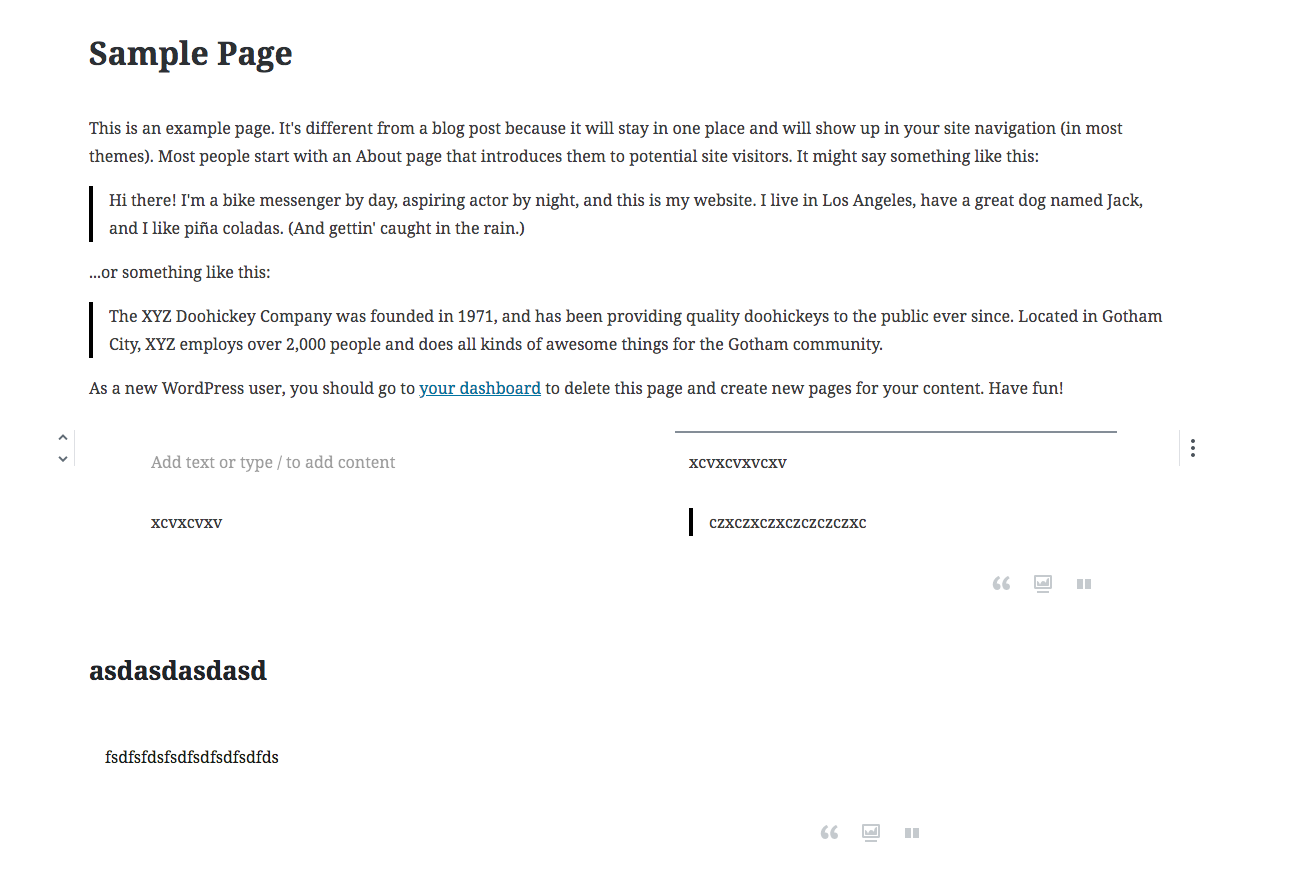
The content in the database looks like
<p>This is an example page. It's different from a blog post because it will stay in one place and will show up in your site navigation (in most themes). Most people start with an About page that introduces them to potential site visitors. It might say something like this:</p>
<blockquote>
<p>Hi there! I'm a bike messenger by day, aspiring actor by night, and this is my website. I live in Los Angeles, have a great dog named Jack, and I like piña coladas. (And gettin' caught in the rain.)</p>
</blockquote>
<p>...or something like this:</p>
<blockquote>
<p>The XYZ Doohickey Company was founded in 1971, and has been providing quality doohickeys to the public ever since. Located in Gotham City, XYZ employs over 2,000 people and does all kinds of awesome things for the Gotham community.</p>
</blockquote>
<p>As a new WordPress user, you should go to <a href="http://somelink.com/wp-admin/">your dashboard</a> to delete this page and create new pages for your content. Have fun!</p>
<!-- wp:columns -->
<div class="wp-block-columns has-2-columns">
<!-- wp:paragraph {"layout":"column-1"} -->
<p class="layout-column-1"></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"layout":"column-1"} -->
<p class="layout-column-1">xcvxcvxv</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"layout":"column-2"} -->
<p class="layout-column-2">xcvxcvxvcxv</p>
<!-- /wp:paragraph -->
<!-- wp:quote {"layout":"column-2"} -->
<blockquote class="wp-block-quote layout-column-2">
<p>czxczxczxczczczczxc</p>
</blockquote>
<!-- /wp:quote -->
</div>
<!-- /wp:columns -->
<!-- wp:heading -->
<h2>asdasdasdasd</h2>
<!-- /wp:heading -->
<!-- wp:verse -->
<pre class="wp-block-verse">fsdfsfdsfsdfsdfsdfsdfds</pre>
<!-- /wp:verse -->
And the REST shows

Can we 'intercept' in any way how the fields are created and use that to manually create a JSON or something that we can then store and use for the front end?
 dingo-d
dingo-d
All 8 comments
The database schema hasn’t changed at all. Gutenberg blocks give a false impression, they are basically pseudo structured content. The whole body field is still saved to a single text field, just bloated up by some extra html comments, separating each block. So the exact opposite to reusable structured content necessary for clean decoupled solutions.
 rpkoller
on 29 Mar 2018
rpkoller
on 29 Mar 2018
So the exact opposite to reusable structured content necessary for clean decoupled solutions.
This would be an interesting research project for someone to take on — what does it look like to break blocks in post_content back out into structured data for display.
Note though, it's unlikely that the underlying storage mechanism (blob data in post_content) will change at this point.
 danielbachhuber
on 29 Mar 2018
danielbachhuber
on 29 Mar 2018
I started working on post-parser, which basically turns HTML into JSON, but I haven't tested it through with the gutenblocks. But since they are 'separated' by the special comments, this should make it even easier to identify them and pass it through the parser. I'm still a long way from finishing it tho (need to find the time). But the general idea is to use it so that I can manipulate the post/page content for the front end app.
I also need to add a method that parses the JSON back to HTML.
But what I thought is that something that separates the blocks already exists so I could use that to simplify the process.
dingo-d
on 29 Mar 2018
If you want to parse things to JS use: https://github.com/Automattic/wp-post-grammar. This will give you the data format that is actually driving the Gutenberg editor.
Implementations:
 BE-Webdesign
on 29 Mar 2018
BE-Webdesign
on 29 Mar 2018
So the exact opposite to reusable structured content necessary for clean decoupled solutions.
This would be an interesting research project for someone to take on — what does it look like to break blocks in post_content back out into structured data for display.
This is already possible via the parser/serializer, and I have used it to do some interesting things. Not crazy about it, but it works.
More info on the post grammar: https://t.co/kHejVQSEBm
BE-Webdesign
on 29 Mar 2018
Thanks for the info, I'll look how I can integrate it with the parser :+1:
dingo-d
on 29 Mar 2018
@dingo-d,
You will then need to use HPQ, in combination with the block registry to parse out the data. The stretching of the parsing into two steps, I believe is to alleviate block authors from having to write custom parsers for their own blocks.
BE-Webdesign
on 29 Mar 2018
Going to close this out for now. The post will be the central source of truth for data in a post, but there is nothing preventing you from just having each block have an ID reference, that will point somewhere else like post meta. You can parse and serialize the wp-post-grammar back and forth to JS, so although the format may seem odd at first (it did to me), there are a lot of reasons why it could be a good solution for moving WordPress forward, outlined in Dennis's article.
BE-Webdesign
on 29 Mar 2018
Related issues
 davidsword
·
3Comments
davidsword
·
3Comments
 mhenrylucero
·
3Comments
mhenrylucero
·
3Comments
 spocke
·
3Comments
spocke
·
3Comments
 wpalchemist
·
3Comments
wpalchemist
·
3Comments
 maddisondesigns
·
3Comments
maddisondesigns
·
3Comments