Graal: Mitigation of Jump Conditional Code (JCC) Erratum wanted to avoid performance loss on Intel CPUs
While largely overlooked due to the new TAA vulnerability and other security related issues, the new microcode from Intel includes a fix for the Jump Conditional Code (JCC) Erratum which carries a significant performance penalty:
https://www.intel.com/content/dam/support/us/en/documents/processors/mitigations-jump-conditional-code-erratum.pdf
https://www.intel.com/content/dam/www/public/us/en/documents/corporate-information/SA00270-microcode-update-guidance.pdf
On the latest version of microcode slow and inefficient code is almost not affected, while for highly optimized with a lot of branching in hot loops throughput slowdown is up to 50% compared to results on the previous version of microcode.
Previous:
model : 158
model name : Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz
stepping : 9
microcode : 0xb4
Current:
model : 158
model name : Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz
stepping : 9
microcode : 0xc6
Microcode updates for Linux (binaries and release notes):
https://github.com/intel/Intel-Linux-Processor-Microcode-Data-Files
Bellow are comparisons of results for the same benchmarks when running on different versions of microcode:
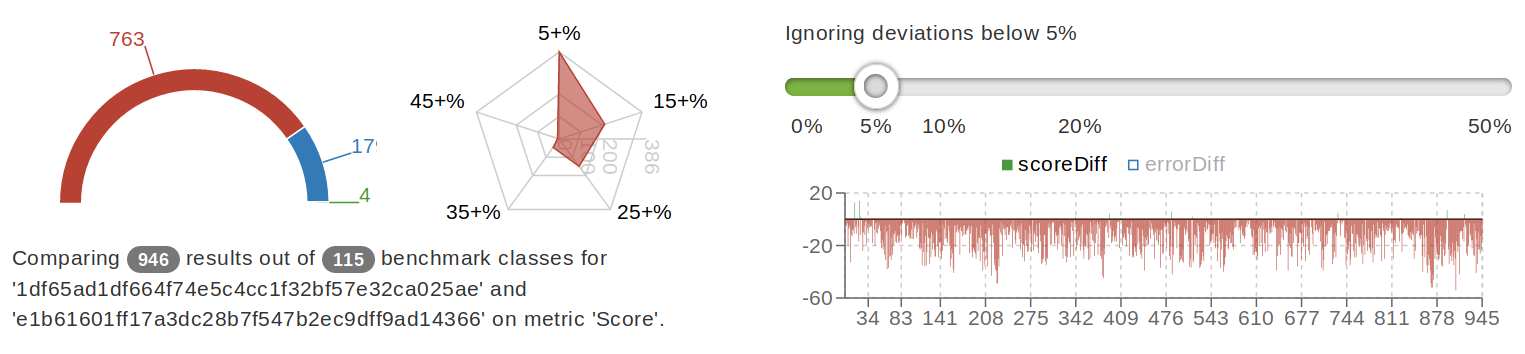
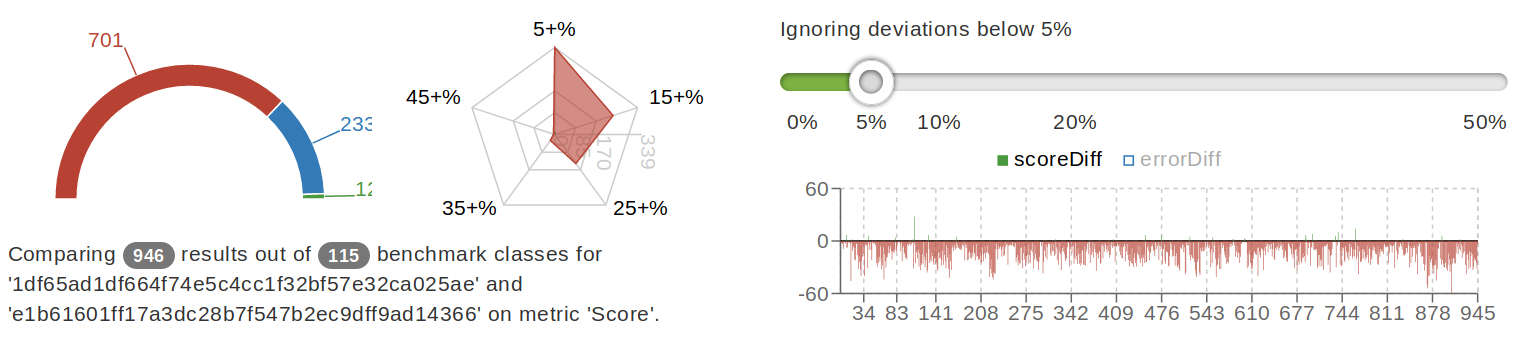
 plokhotnyuk
plokhotnyuk
All 18 comments
Thanks for the report @plokhotnyuk . We will look into this but the window for 19.3 is pretty much closed for a change this size. That said, we will look into implementing something like the -mbranches-within-32B-boundaries option in the gnu assembler as soon as possible.
 dougxc
on 14 Nov 2019
dougxc
on 14 Nov 2019
@dougxc @mur47x111 In the issue description I've added links to Intel CPU microcode updates (for Linux) and links for benchmarks comparison on different versions of microcode.
I'm waiting 19.3 release with impatience and going to update comparison if I will find how to rollback to the previous version of microcode.
BTW, new versions of microcode were released after 12/11/2019.
ICYMI: A series of patches with code for a new -mbranches-within-32B-boundaries compiler option which "aligns conditional jump, fused conditional jump and unconditional jump within 32-byte boundary" has been proposed on the binutils mailing list.
The problem introduced by JCC Erratum is hard to fix clearly and forcing everyone to pay a price in terms of runtime performance and codesize.
In any case, please, also consider reordering of floating nodes, using of branch-less tricks with sete and seta instructions, more aggressive inlining, loop unrolling, and vectorization in tight and hot loops to minimize number of branches, calls, jumps, etc..
plokhotnyuk
on 17 Nov 2019
Given the short window for 19.3, we won't be able to include such fix in the 19.3 release. I have a nop-based prototype, and will convert it into a prefix-based solution and push into the next update release.
 mur47x111
on 18 Nov 2019
mur47x111
on 18 Nov 2019
@mur47x111 great work!
Could you please share a branch with your prototype?
Can it be built by standard steps?
I would like to build and test it locally...
plokhotnyuk
on 18 Nov 2019
Let me polish it first. Still many //TODO ;)
It will land in the master (before the next update release), and then you can use the standard steps to build it.
mur47x111
on 19 Nov 2019
IFYK: The initial patch landing in LLVM 10 https://github.com/llvm/llvm-project/commit/14fc20ca62821b5f85582bf76a467d412248c248
plokhotnyuk
on 22 Dec 2019
This is more complicated than I thought initially.. anyway, with https://github.com/oracle/graal/commit/07ae939513d1eb2f40402eb9304938c20f8bb611 and https://github.com/oracle/graal/commit/de73dbb3bc031756061426391920fc52f2b7a815 we are now able to enable the jcc paddings. You only need to pass -Dgraal.UseBranchesWithin32ByteBoundary=true while running the application. When http://cr.openjdk.java.net/~eosterlund/8234160/webrev.01/ is merged, I will then set this option accordingly.
@plokhotnyuk would you please give it a try and report if the patch helps addressing the regression?
mur47x111
on 17 Jan 2020
@mur47x111 Great work, Yudi!
Just tried a couple of benchmarks on my laptop with Intel Core i7 and the latest version of microcode.
graalvm-libgraal-java8-20.0.0 with -Dgraal.UseBranchesWithin32ByteBoundary=false
[info] REMEMBER: The numbers below are just data. To gain reusable insights, you need to follow up on
[info] why the numbers are the way they are. Use profilers (see -prof, -lprof), design factorial
[info] experiments, perform baseline and negative tests that provide experimental control, make sure
[info] the benchmarking environment is safe on JVM/OS/HW level, ask for reviews from the domain experts.
[info] Do not assume the numbers tell you what you want them to tell.
[info] Benchmark (size) Mode Cnt Score Error Units
[info] StringOfAsciiCharsWriting.jsoniterScalaPrealloc 128 thrpt 5 2794838.945 ± 11302.004 ops/s
[info] StringOfEscapedCharsWriting.jsoniterScalaPrealloc 128 thrpt 5 1974297.307 ± 3173.319 ops/s
[info] StringOfNonAsciiCharsWriting.jsoniterScalaPrealloc 128 thrpt 5 2075002.940 ± 466.351 ops/s
graalvm-libgraal-java8-20.0.0 with -Dgraal.UseBranchesWithin32ByteBoundary=true
[info] REMEMBER: The numbers below are just data. To gain reusable insights, you need to follow up on
[info] why the numbers are the way they are. Use profilers (see -prof, -lprof), design factorial
[info] experiments, perform baseline and negative tests that provide experimental control, make sure
[info] the benchmarking environment is safe on JVM/OS/HW level, ask for reviews from the domain experts.
[info] Do not assume the numbers tell you what you want them to tell.
[info] Benchmark (size) Mode Cnt Score Error Units
[info] StringOfAsciiCharsWriting.jsoniterScalaPrealloc 128 thrpt 5 5864945.579 ± 8776.218 ops/s
[info] StringOfEscapedCharsWriting.jsoniterScalaPrealloc 128 thrpt 5 2307407.851 ± 1047.652 ops/s
[info] StringOfNonAsciiCharsWriting.jsoniterScalaPrealloc 128 thrpt 5 2924913.938 ± 6584.358 ops/s
Hmm I did not expect the effect to be so huge..
mur47x111
on 17 Jan 2020
BTW, does this flag align only branches? What about jumps, calls, and returns? Will be they aligned with this option turned on?
plokhotnyuk
on 17 Jan 2020
All of them are covered. The jumps calls returns are the easy ones
mur47x111
on 17 Jan 2020
@mur47x111 You've made Intel CPUs great again!
Here is a comparison of results for the latest version of benchmarks on GraalVM CE Java8 20.0.0-dev with the UseBranchesWithin32ByteBoundary option turned off/on:
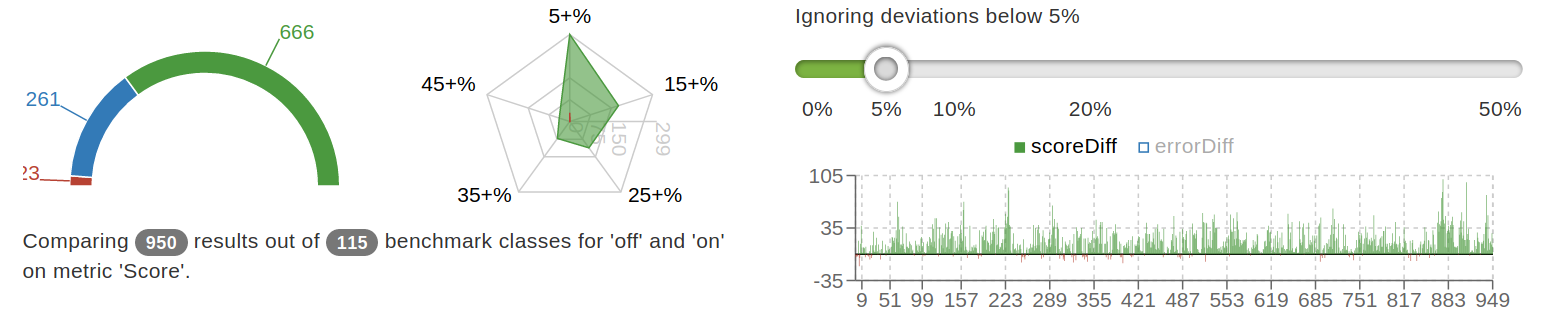
The following environment was used: Intel® Core™ i9-9880H CPU @ 2.3GHz (max 4.8GHz), RAM 16Gb DDR4-2400, macOS Mojave 10.14.6
plokhotnyuk
on 18 Jan 2020
@mur47x111 @dougxc I had built libgraal using the standard steps from the docs, but now just wondering if it is possible to turn this option on when building native images or libgraal itself?
plokhotnyuk
on 21 Jan 2020
For native images, it should just be a matter of using the -H:+UseBranchesWithin32ByteBoundary option.
dougxc
on 21 Jan 2020
@mur47x111 do you have some insight as to what the cost of building libgraal with this option enabled will cost in terms of performance of libgraal on platforms that are not subject to the JCC erratum?
dougxc
on 21 Jan 2020
@mur47x111 I see that HotSpot C2 mitigations for jcc erratum are merged to the JDK master. Will you reuse their approach of turning on a branch alignment by default for affected CPUs?
plokhotnyuk
on 25 Feb 2020
Closing as resolved... Works fine in early access builds of OpenJDK 15 too!
plokhotnyuk
on 22 Mar 2020
Sorry for not replying earlier. With the new JVMCI https://github.com/graalvm/labs-openjdk-11/releases/tag/jvmci-20.1-b01 and https://github.com/oracle/graal/commit/6fe68785c8a20ebd905e922d42e6ed22a431702b we are now able to turn on the branch alignment by default on affected CPUs. Latest JDK should contain the necessary patch as well.
mur47x111
on 31 Mar 2020
Related issues
 guaporocco
·
3Comments
guaporocco
·
3Comments
 oroppas
·
3Comments
oroppas
·
3Comments
 helloguo
·
3Comments
helloguo
·
3Comments
helloguo
·
3Comments
helloguo
·
3Comments
 schneidersteve
·
3Comments
schneidersteve
·
3Comments
Most helpful comment
@mur47x111 You've made Intel CPUs great again!
Here is a comparison of results for the latest version of benchmarks on GraalVM CE Java8 20.0.0-dev with the

UseBranchesWithin32ByteBoundaryoption turned off/on:The following environment was used: Intel® Core™ i9-9880H CPU @ 2.3GHz (max 4.8GHz), RAM 16Gb DDR4-2400, macOS Mojave 10.14.6