Google-cloud-python: Pub/sub: amount of streaming pull operations way higher than streaming ack operations
We are using python 2.7.12 with google-cloud-pubsub==0.30.1 and grpcio==1.9.1 and have a very basic subscriber script:
import random
import time
from google.cloud import pubsub
GCLOUD_PROJECT_ID = <our_project_id>
SUBSCRIPTION_NAME = <subscription_name>
def pubsub_message_callback(message):
time.sleep(random.random())
message.ack()
def main():
sub_client = pubsub.SubscriberClient()
full_subscription_name = 'projects/{project_id}/subscriptions/{subscription}'.format(
project_id=GCLOUD_PROJECT_ID,
subscription=SUBSCRIPTION_NAME,
)
pubsub_subscription = sub_client.subscribe(
full_subscription_name,
flow_control=pubsub.types.FlowControl(max_messages=1)
)
pubsub_subscription.open(
pubsub_message_callback
)
while True:
pass
if __name__ == '__main__':
main()
When having a large backlog and running this script for 20 minutes, the amount of streaming pull operations is 100 times the amount of streaming ack operations. (see image)
As the the flow control is set to max_messages=1 I would expect that it will always wait to ack the received message, before receiving another one. And even when flow control was not set to max_messages=1 it still looks like unintended behaviour as the total amount of pull operations is still way higher than the amount of ack operations (so what happens with those received/unacked messages?). Is this a bug or is it intended behaviour?
Also asked this as a question on stackoverflow
 krelst
krelst
All 46 comments
@lukesneeringer or @dhermes can you take a look?
 theacodes
on 6 Feb 2018
theacodes
on 6 Feb 2018
To be honest, I am not really sure what constitutes a "streaming pull message operation" or an "ack operation". I agree it looks odd -- are you having a discernable issue, or is this just that your metrics look strange?
 lukesneeringer
on 8 Feb 2018
lukesneeringer
on 8 Feb 2018
Hi @lukesneeringer, sorry for the late response! This is the pubsub.googleapis.com/subscription/streaming_pull_ack_message_operation_count metric in stackdriver see image. I know the pubsub.googleapis.com/subscription/pull_ack_message_operation_count metric is the amount of messages that are ack'ed by a regular (non-streaming) api call, so I suppose that the other metric is the streaming equivalent. Same goes for the streaming pull operations. I couldn't really determine whether it was just the metrics that were incorrect or that there was indeed were way more messages pulled than ack'ed. Could you think of a way so that I could determine this?
krelst
on 14 Feb 2018
@kir-titievsky are these metrics supposed to match up in the streaming pull case?
I couldn't really determine whether it was just the metrics that were incorrect or that there was indeed were way more messages pulled than ack'ed. Could you think of a way so that I could determine this?
@krelst I would imagine your "undelivered" count in stackdriver would be fairly high and you would see a large number of duplicates in your workers.
theacodes
on 14 Feb 2018
Similar to @krelst, but the amount of streaming pull operations is 50 times the amount of streaming ack operations.
We're running google-cloud-pubsub==0.30.1 and grpcio==1.9.1 with python 3.6.3, FlowControl.max_messages at 1
Once the topic start to "grow large" (more than 0.5M undelivered) we're seeing around 25% of duplicates in our workers (using Message.message_id), and the "undelivered" count goes down
abnormally slow compared to our previous code with google-cloud-pubsub==0.27.0 and grpcio==1.4.0.
Would it be possible that the consumer pull a large number of messages, causing him to pause and thereby stop sending ack request until it resume (or modify ack deadline) ?
 TonyRoussel
on 15 Feb 2018
TonyRoussel
on 15 Feb 2018
This may be related to a server-side issue under active investigation. The
reason you might be seeing slower ack rates is that you are spending more
time processing duplicates. Could you offer any more detail on how
different you ack & pull rates are?
On Thu, Feb 15, 2018 at 6:58 AM TonyRoussel notifications@github.com
wrote:
Similar to @krelst https://github.com/krelst, but the amount of
streaming pull operations is 50 times the amount of streaming ack
operations.
We're running google-cloud-pubsub==0.30.1 and grpcio==1.9.1 with python
3.6.3, FlowControl.max_messages at 1
Once the topic start to "grow large" (more than 0.5M undelivered) we're
seeing around 25% of duplicates in our workers (using Message.message_id),
and the "undelivered" count goes down
abnormally slow compared to our previous code with
google-cloud-pubsub==0.27.0 and grpcio==1.4.0.Would it be possible that the consumer pull a large number of messages,
causing him to pause and thereby stop sending ack request until it resume
(or modify ack deadline) ?—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/GoogleCloudPlatform/google-cloud-python/issues/4841#issuecomment-365952198,
or mute the thread
https://github.com/notifications/unsubscribe-auth/ARrMFuBRm2NpSzNtEWFsP-iVgHs1gDkHks5tVEYtgaJpZM4R60pP
.
--
Kir Titievsky | Product Manager | Google Cloud Pub/Sub
https://cloud.google.com/pubsub/overview
 kir-titievsky
on 15 Feb 2018
kir-titievsky
on 15 Feb 2018
I'm not sure about what you need, so here is a graph similar to the one provided @krelst
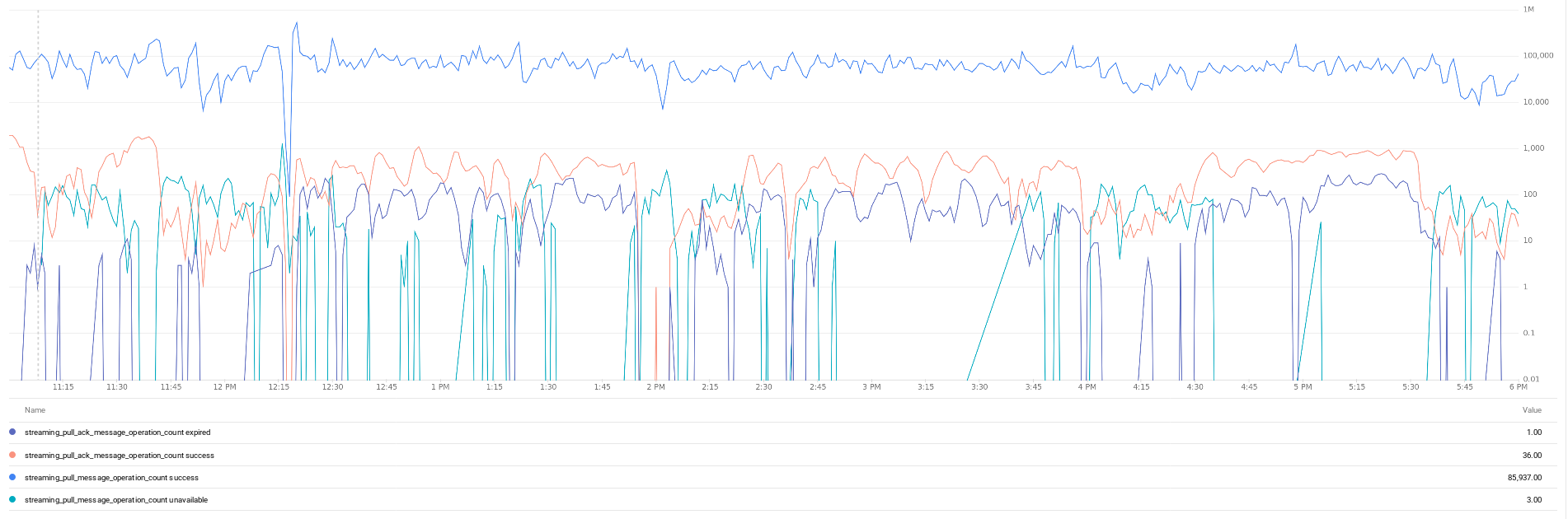
and from our logs, how many time our callback got trigger, and how many message.ack() we called (the time window is restrained to the period where we tried pubsub 0.30.1 (we had to rollback))
+----+--------+ +----+--------+
| h | callbk | | h | ack |
+----+--------+ +----+--------+
| 11 | 144471 | | 11 | 143680 |
| 12 | 126435 | | 12 | 125071 |
| 13 | 109496 | | 13 | 110254 |
| 14 | 266072 | | 14 | 266046 |
| 15 | 126582 | | 15 | 125779 |
| 16 | 100407 | | 16 | 101160 |
| 17 | 128546 | | 17 | 127810 |
+----+--------+ +----+--------+
I believe the change proposed at https://github.com/GoogleCloudPlatform/google-cloud-python/issues/4792#issuecomment-366085662 might completely solve this issue.
Do you mind trying out the version of pubsub on the pubsub-request-load branch? This version adds backpressure when there are too many outstanding requests on the stream, which should make the acks only trail behind the message count by 100+/-100.
You can install this using:
git clone -b pubsub-request-load https://github.com/GoogleCloudPlatform/google-cloud-python.git
pip install --upgrade google-cloud-python/pubsub
If this works or improves the situation at all for you, I'll get it merged and released.
theacodes
on 15 Feb 2018
Ok I'll give it a try soon
TonyRoussel
on 16 Feb 2018
I could have only 1 hour of load, but it looks better. I got around 7% of duplicates and the largest split between ack operations and pull operations is 14.5x

and from our logs, how many time our callback got trigger, and how many message.ack() we called
+----+--------+ +----+--------+
| h | callbk | | h | ack |
+----+--------+ +----+--------+
| 16 | 91613 | | 16 | 90459 |
+----+--------+ +----+--------+
Great, that seems much better. I'm going to get this merge ready.
There is another step we can take to improve this, but I think this will largely solve this particular issue.
theacodes
on 16 Feb 2018
Unfortunately, right after the topic stop receiving messages (send_message_operation_count), the split return to 100x
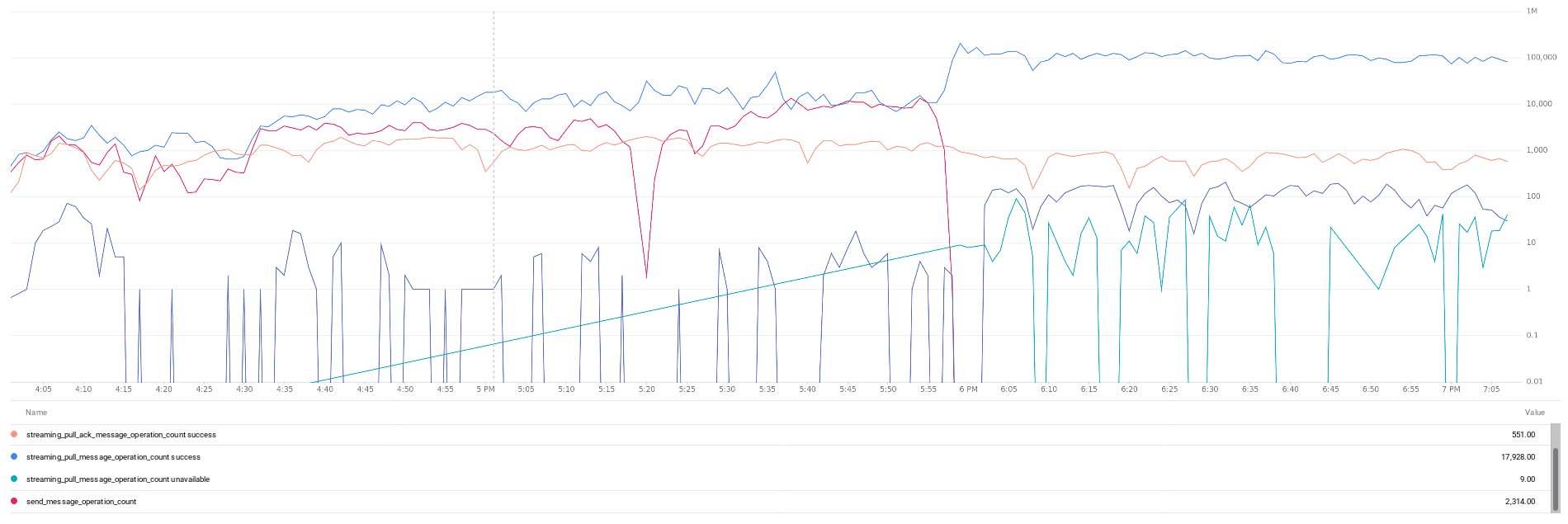
Duplication look stable at 7%
TonyRoussel
on 16 Feb 2018
@TonyRoussel that seems weird. Your workers are still receiving messsages even though you're not publishing anything?
theacodes
on 16 Feb 2018
No there's still undelivered messages in the subscription
It's just there is no new messages
Maybe it's just an odd coincidence, but I don't see any other metrics that match the sudden increase in the ack/pull split :/
TonyRoussel
on 16 Feb 2018
@kir-titievsky any ideas?
theacodes
on 16 Feb 2018
Hello any news about this ?
Do you have any recommendations regarding the new parameters in FlowControl ?
TonyRoussel
on 21 Feb 2018
@TonyRoussel I would check out the latest release, 0.31.0, and see how that works for you.
I'm still awaiting more details from the Pub/Sub team on the server-side issue that @kir-titievsky mentioned.
theacodes
on 21 Feb 2018
yes I tried it and I see the same split between ack and pull. How should I tweak the FlowControl to lower the pull ? I already set max-messages at 1
TonyRoussel
on 21 Feb 2018
That is how you lower the pull. You can also make sure your callbacks do something. If all your callback does is ack the messages your subscriber will still consume messages very quickly.
theacodes
on 21 Feb 2018
@TonyRoussel Thanks for your patience. There is a service side improvement that started rolling out a few days back and should be completely out by tomorrow. I suspect that what was happening here is that Pub/Sub was delivering the same message multiple times, causing more pulls than acknowledgements. If I'm right, what you should see:
- Today, your backlog size (number of unacked messages) would decrease at the same rate as the number of acknowledgement message operations, not the pull message operations, assuming you are not publishing.
- Starting tomorrow, and surely by Wednesday, you should see consistent acks & pulls and none of this craziness.
kir-titievsky
on 26 Feb 2018
@kir-titievsky thanks for the update. Cannot confirm about the the backlog size right now cause we split our instance group in two to handle the high-volume topic with pubsub==0.27. We'll try again to see if we have better results
Does the server-side improvements could fix issues related to "inactive" consumers ? I have some consumer that stop receiving messages even when the backlog is stuffed. My current workaround is to restart them every 1min if nothing is received. Maybe I'm going off-topic too much here..
TonyRoussel
on 26 Feb 2018
Based on @kir-titievsky's comment, I'm going to go ahead and close this. However, if it's still an issue we can continue discussing.
theacodes
on 26 Feb 2018
@TonyRoussel were you able to find the root cause of the problem? I am seeing inactive subscribers very often...
 psalaberria002
on 7 May 2018
psalaberria002
on 7 May 2018
From our experiment I would say that the root cause was forking (with
multiprocessing lib) and using multiple consumers.
The temporary solution until we use another messaging system, was to
monitor the suscribers and restart them when they're inactive for too long
:/
On Mon, May 7, 2018, 09:53 psalaberria002 notifications@github.com wrote:
@TonyRoussel https://github.com/TonyRoussel where you able to find the
root cause of the problem? I am seeing inactive subscribers very often...—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/GoogleCloudPlatform/google-cloud-python/issues/4841#issuecomment-386988007,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AGGFP3S8J9KaSGaI0iRkNXLUVIMteZdiks5tv_2RgaJpZM4R60pP
.
TonyRoussel
on 7 May 2018
@psalaberria002 @TonyRoussel If the inactivity of sub-scribers are the symptom you are observing, I'll bet on a client-side issue. The wonderful news here is that @jonparrott has completely rewritten the subscriber code to address a lot of the multithreading issues. The current release has it in SubscriberClient.subscriber_experimental, but the code should get merged into a release this week as the normal subscribe[1] method. You should not see this craziness any more with the new code. Please let us know if your results improve with the latest code.
[1]https://github.com/GoogleCloudPlatform/google-cloud-python/pull/5274/commits
kir-titievsky
on 7 May 2018
What's the recommended approach to check if the subscriber is running? I tried future._manager.is_active, and it is very often False even when I have 500K pending messages.
future._manager._closed returns False even though the subscriber is not consuming.
I am using the experimental subscriber by the way.
psalaberria002
on 7 May 2018
if future._manager.is_active is False then the consumer is not processing any messages and the future should've been resolved with an exception.
theacodes
on 7 May 2018
Also where is the 500K pending messages number coming from?
theacodes
on 7 May 2018
Does that mean it is a failure?
In my application I have two subscriptions to different topics. I want to run it indefinitely. How can I do that? I do not want the application to exit when a subscriber doesn't have more messages to process. It should keep running.
psalaberria002
on 7 May 2018
They stay open indefinitely until an unrecoverable error occurs (which will be raised by future.result()) or if you call future.cancel().
theacodes
on 7 May 2018
500K pending messages comes from Stackdriver monitoring.
Why does a subscriber return False when calling future._manager.is_active then if there are thousands of messages in the subscription? What am I missing?
psalaberria002
on 7 May 2018
500K pending messages comes from Stackdriver monitoring.
I see. Remember that the client will only pull a limited number of items from the subscription at a time.
Why does a subscriber return False when calling future._manager.is_active then if there are thousands of messages in the subscription? What am I missing?
I'm not sure, I need more details. Can you maybe enable debug-level logging and share your log with us? Can you share the code you're using for subscribing? Can you see if the future has an exception?
theacodes
on 7 May 2018
I have something like the following. Using 0.34.0.
s1=SubscriberClient()
subscription1_future = s1.subscribe_experimental(subscription1_path, callback_fn)
s2=SubscriberClient()
subscription2_future = s2.subscribe_experimental(subscription2_path, callback_fn)
try:
res = subscription1_future.result()
except Exception as e:
self.logger.error("Exception raised in subscriber thread")
self.logger.error(e.__str__, exc_info=True)
After few minutes without messages in the queue, the subscribers get inactive. Sending new messages to the queues does not trigger the subscriber. When I restart or add new instances then new messages flow as expected.
psalaberria002
on 7 May 2018
-05-07 20:25:56,311 DEBUG 161:leaser.py(1) - Snoozing lease management for 2.093734 seconds.
2018-05-07 20:25:57,377 DEBUG 448:bidi.py(1) - Thread-ConsumeBidirectionalStream caught error 503 The service was unable to fulfill your request. Please try again. [code=8a75] and will exit. Generally this is due to the RPC itself being cancelled and the error will be surfaced to the calling code.
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/google/api_core/grpc_helpers.py", line 76, in next
return six.next(self._wrapped)
File "/usr/local/lib/python3.6/site-packages/grpc/_channel.py", line 347, in __next__
return self._next()
File "/usr/local/lib/python3.6/site-packages/grpc/_channel.py", line 341, in _next
raise self
grpc._channel._Rendezvous: <_Rendezvous of RPC that terminated with (StatusCode.UNAVAILABLE, The service was unable to fulfill your request. Please try again. [code=8a75])>
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/google/cloud/pubsub_v1/subscriber/_protocol/bidi.py", line 348, in _recoverable
return method(*args, **kwargs)
File "/usr/local/lib/python3.6/site-packages/google/cloud/pubsub_v1/subscriber/_protocol/bidi.py", line 258, in recv
return next(self.call)
File "/usr/local/lib/python3.6/site-packages/google/api_core/grpc_helpers.py", line 78, in next
six.raise_from(exceptions.from_grpc_error(exc), exc)
File "<string>", line 3, in raise_from
google.api_core.exceptions.ServiceUnavailable: 503 The service was unable to fulfill your request. Please try again. [code=8a75]
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/google/api_core/grpc_helpers.py", line 76, in next
return six.next(self._wrapped)
File "/usr/local/lib/python3.6/site-packages/grpc/_channel.py", line 347, in __next__
return self._next()
File "/usr/local/lib/python3.6/site-packages/grpc/_channel.py", line 341, in _next
raise self
grpc._channel._Rendezvous: <_Rendezvous of RPC that terminated with (StatusCode.UNAVAILABLE, The service was unable to fulfill your request. Please try again. [code=8a75])>
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/google/cloud/pubsub_v1/subscriber/_protocol/bidi.py", line 439, in _thread_main
response = self._bidi_rpc.recv()
File "/usr/local/lib/python3.6/site-packages/google/cloud/pubsub_v1/subscriber/_protocol/bidi.py", line 365, in recv
super(ResumableBidiRpc, self).recv)
File "/usr/local/lib/python3.6/site-packages/google/cloud/pubsub_v1/subscriber/_protocol/bidi.py", line 357, in _recoverable
return method(*args, **kwargs)
File "/usr/local/lib/python3.6/site-packages/google/cloud/pubsub_v1/subscriber/_protocol/bidi.py", line 258, in recv
return next(self.call)
File "/usr/local/lib/python3.6/site-packages/google/api_core/grpc_helpers.py", line 78, in next
six.raise_from(exceptions.from_grpc_error(exc), exc)
File "<string>", line 3, in raise_from
google.api_core.exceptions.ServiceUnavailable: 503 The service was unable to fulfill your request. Please try again. [code=8a75]
Thanks, @psalaberria002, this is super helpful. Are you actually seeing this code get executed?:
self.logger.error("Exception raised in subscriber thread")
self.logger.error(e.__str__, exc_info=True)
If not, what do you see in the logs after that stacktrace? (It's actually really helpful you can share your entire log with us, you can use gist.github.com and link to it).
503s should generally be retried automatically, @kir-titievsky would you know what code 8a75 means? All I can find is that is it is transient.
theacodes
on 7 May 2018
Not sure precisely, but they person I would ask has already responded to this here: it's a please-retry error.
kir-titievsky
on 7 May 2018
@jonparrott you can find the gist here.
That one starts 2 subscribers. One of them dies quite early, the other one later.
The code does not get executed, so I suspect the exception is not thrown.
psalaberria002
on 7 May 2018
And the same happens when I use a single subscriber (just wanted to make sure it wasn't related to having subscribers to multiple subscriptions). I have added a comment to the gist.
psalaberria002
on 7 May 2018
What happens at the end of your log? Does it not log any more and just appears to hang indefinitely or does the program actually exit?
theacodes
on 7 May 2018
It hangs indefinitely. That's the last line of the log.
psalaberria002
on 7 May 2018
Hrm, I'm thinking this is a race condition but I am currently unable to reproduce this at all. I'll keep investigating and report back.
theacodes
on 7 May 2018
I let it running for a while, and I got the following error now:
google.api_core.exceptions.DeadlineExceeded: 504 Deadline Exceeded
Added an extra comment in the gist with the full output.
Thank you.
psalaberria002
on 7 May 2018
In case it helps while debugging, I am running it with service account credentials in Kubernetes, using Python3.
psalaberria002
on 7 May 2018
Thanks. I may not be able to debug any further this week, unfortunately, as PyCon is coming up.
theacodes
on 7 May 2018
Actually, starting a new issue for this.
theacodes
on 7 May 2018
theacodes
on 7 May 2018
Related issues
 bmenasha
·
3Comments
bmenasha
·
3Comments
 LMeinhardt
·
4Comments
LMeinhardt
·
4Comments
 tweeter0830
·
4Comments
tweeter0830
·
4Comments
 jannaspam
·
3Comments
jannaspam
·
3Comments
 andrewsmartin
·
3Comments
andrewsmartin
·
3Comments
Most helpful comment
@TonyRoussel Thanks for your patience. There is a service side improvement that started rolling out a few days back and should be completely out by tomorrow. I suspect that what was happening here is that Pub/Sub was delivering the same message multiple times, causing more pulls than acknowledgements. If I'm right, what you should see: