Google-cloud-java: Duplicate/combined word (lists) when using the response 'SpeechRecognitionResult' from longRunningRecognizeAsync
When looping trough the 'SpeechRecognitionResult' objects, I noticed that the transcript attribute and the 'words_' list do not match for (at least) the last result. In our app, we always use the first and only alternative. I noticed that the word lists do match the transcript from the first few results, but for the last result, all words including the last one will be returned in words. I would expect that the last result only contains the words which are related to that specific transcript.
I assume this is a bug. If not; please advice.
Environment details
- OS: Windows 10
- Java version: 1.8.0_102
- google-cloud-java version(s): google-cloud-speech-0.67.0-beta
Code snippet
In order to clarify this, I added a simplified code snippet below.
List<SpeechRecognitionResult> results = response.getResultsList();
for (SpeechRecognitionResult result : results) {
SpeechRecognitionAlternative alternative = result.getAlternativesList().get(0);
String transcript = alternative.getTranscript();
for (WordInfo wordInfo : alternative.getWordsList()) {
String word = wordInfo.getWord();
}
}
In my current example, we have 3 results. The number of words are correct for the first two, but the third (last) is incorrect and includes all words from the whole text.
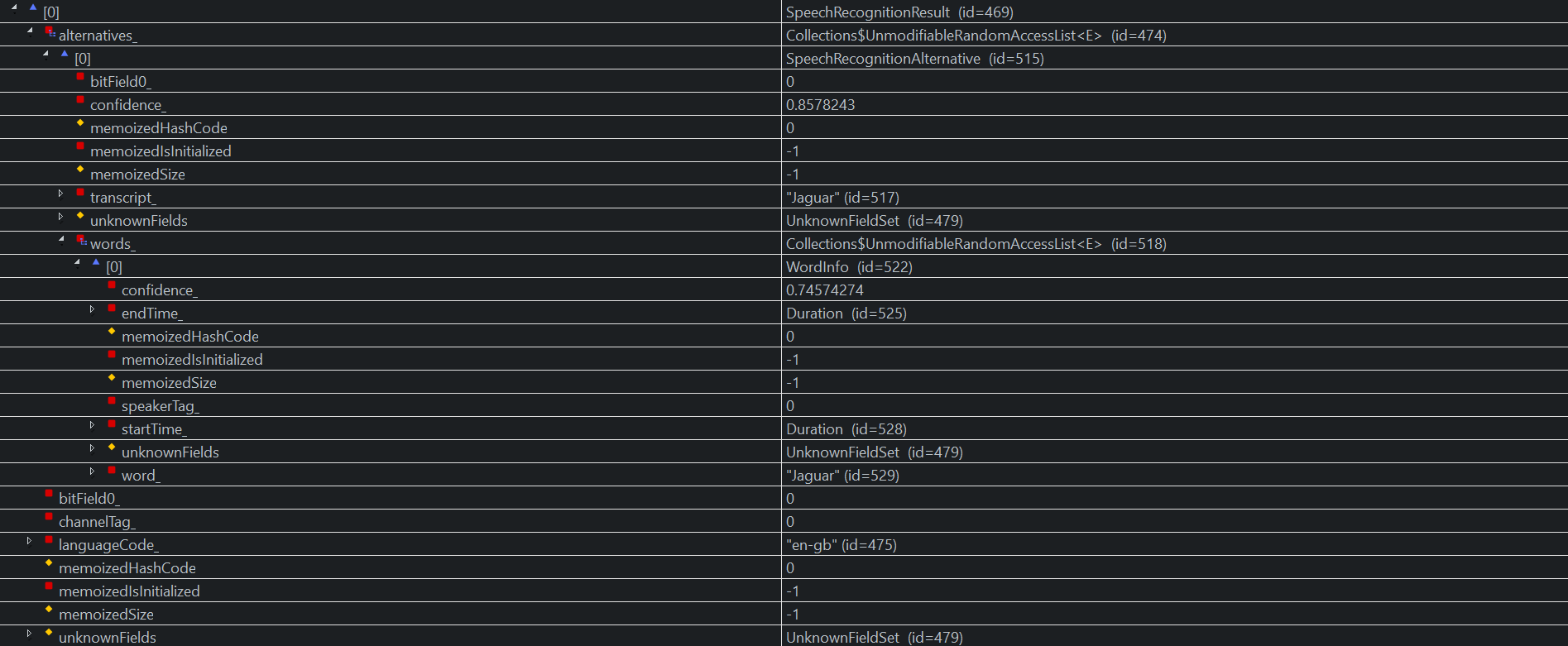
Result 0: Only the word Jaguar (both the transcript and the only word)
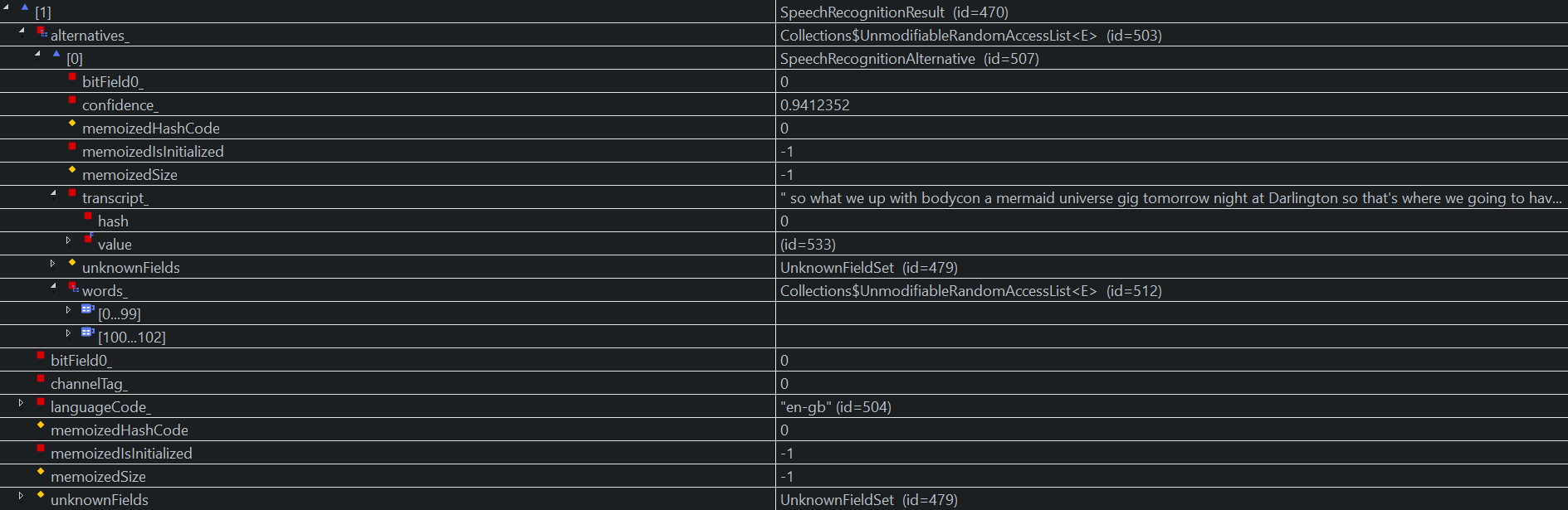
Result 1: A longer transcript, with 102 (correct) words in total
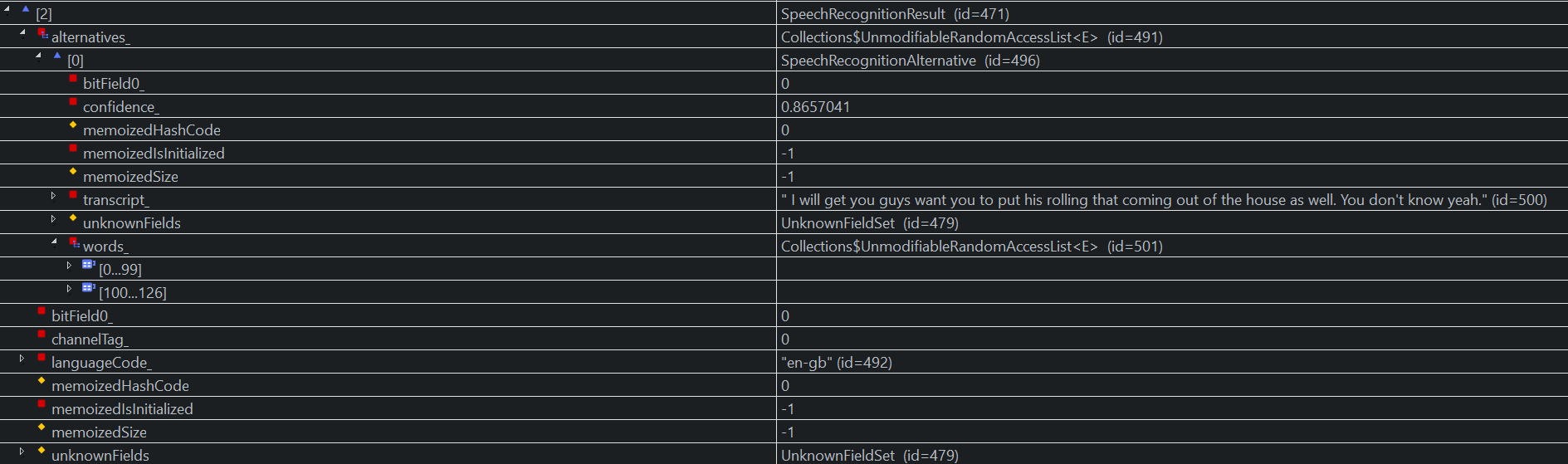
Result 2: A short transcript with only 23 words. As you can see, the list with words includes all 126 words (1+102+23).
 JeroenAppel
JeroenAppel
All 9 comments
Could some one from Google please have a look at this? The behavior is not consistent. The results were good for a few days, but now the duplicate list is back.
JeroenAppel
on 19 Nov 2018
Can you share your RecognitionConfig setup code?
 JesseLovelace
on 5 Dec 2018
JesseLovelace
on 5 Dec 2018
I'm wondering if it's related to the fact that when EnableSpeakerDiarization is true, the words list is expected to contain all words from the beginning of the audio, even though the transcript does not.
Related documentation: https://github.com/googleapis/google-cloud-java/blob/master/google-api-grpc/proto-google-cloud-speech-v1p1beta1/src/main/java/com/google/cloud/speech/v1p1beta1/SpeechRecognitionAlternative.java#L187
If EnableSpeakerDiarization is set to true, can you set it to false and see if you experience the same problem?
JesseLovelace
on 5 Dec 2018
Some additional documentation: https://github.com/googleapis/google-cloud-java/blob/master/google-api-grpc/proto-google-cloud-speech-v1p1beta1/src/main/java/com/google/cloud/speech/v1p1beta1/RecognitionConfig.java#L965
JesseLovelace
on 5 Dec 2018
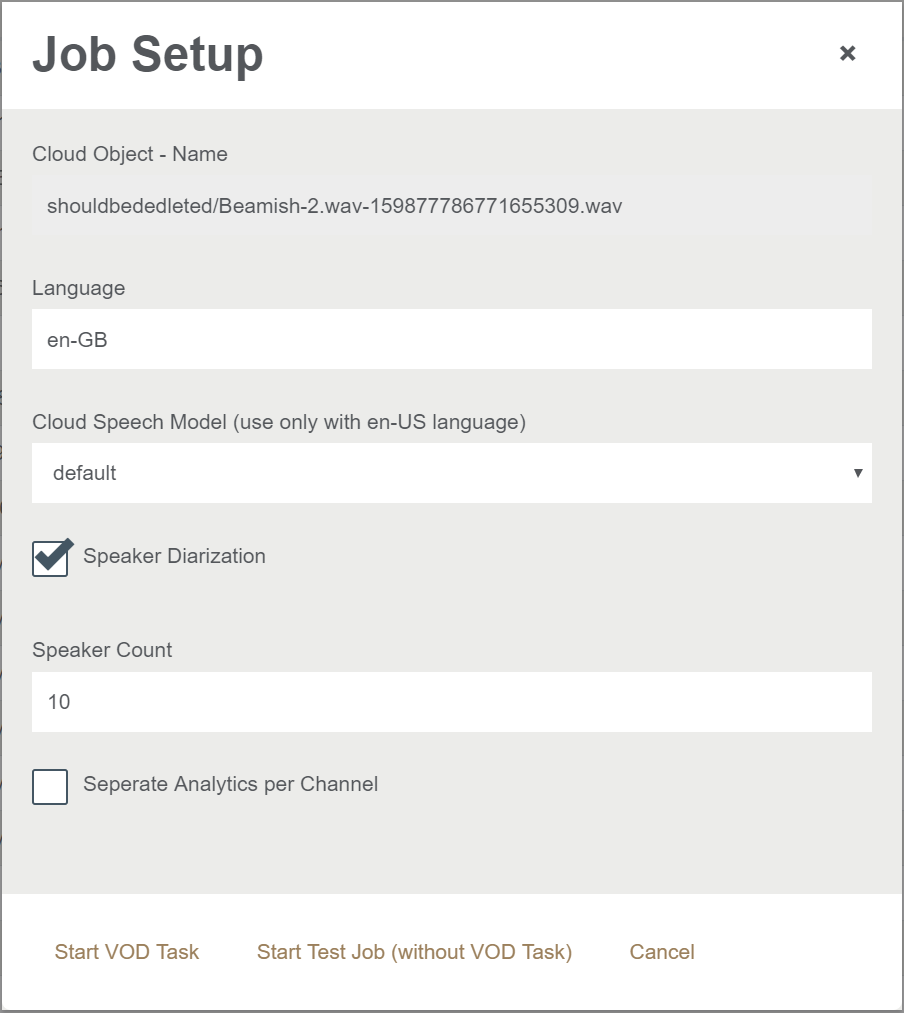
Thanks for the update Jesse. While experimenting with your suggestions and reading the additional documentation, I can verify that the behavior is now explainable and consistent. The RecognitionConfig will be set by the end user (see the screenshot for an impression).
When the Speaker Diarization has been set to false, the results are fine. However the behavior is now explainable when set to true, I still think that this is not a preferable way of working with the response. We use the first and the last word in order to determine the start and end of a sentence, because there are no such fields on the 'alternative' level. In addition to that, we store the sentences and associated words altogether in our database. This is required in order to our front-end application. If we want to achieve this now, it feels like we need to build some custom logic to determine which words underneath the alternative are really part of that sentence.
Hopefully this explains our setup. Thanks for your clarification so far. We are happy to hear your thoughts on this.
JeroenAppel
on 6 Dec 2018
I agree that the behavior is a little strange and unintuitive, I can start a discussion with the Speech team to see if it can be re-thought, or if there's a workaround in place that I'm not aware of.
In the meantime, maybe a workaround could be to keep track of the word counts given in previous iterations, and on the last one get the relevant portion using List.subList()?
You may have tried this, but the code you provided in the original question could be replaced by something like this.
List<SpeechRecognitionResult> results = response.getResultsList();
Iterator<SpeechRecognitionResult> i = results.iterator();
int wordsCounted = 0;
while(i.hasNext()) {
SpeechRecognitionResult result = i.next();
SpeechRecognitionAlternative alternative = result.getAlternativesList().get(0);
String transcript = alternative.getTranscript();
List<WordInfo> words;
if (i.hasNext() || !config.getEnableSpeakerDiarization()) {
wordsCounted += alternative.getWordsCount();
words = alternative.getWordsList();
} else {
words = alternative.getWordsList().subList(wordsCounted, alternative.getWordsCount());
}
for (WordInfo wordInfo : words) {
String word = wordInfo.getWord();
}
}
Thanks for the update and workaround @JesseLovelace For now, it looks like this is working for our implementation. I am now able to set the correct start- and end time.
If there are any updates on a final 'solution' or a more intuitive way of working with the responses, I will be happy to hear about that in the future. For now, thanks for your support.
JeroenAppel
on 10 Dec 2018
@beccasaurus FYI
JesseLovelace
on 15 Jan 2019
Closing issue as it seem the original question has been answered. If you would like a feature request for the service itself I would suggest opening up a ticket with the GCP Public Issue Tracker.
 codyoss
on 3 Dec 2019
codyoss
on 3 Dec 2019
Related issues
 ChengyuanZhao
·
3Comments
ChengyuanZhao
·
3Comments
 Electricks94
·
4Comments
Electricks94
·
4Comments
 raintears
·
3Comments
raintears
·
3Comments
 lucmult
·
5Comments
lucmult
·
5Comments
 Mistic92
·
5Comments
Mistic92
·
5Comments