Google-cloud-go: PubSub: streaming pull operation stops for 20mins and resumes without error
I experienced an issue that receiving throughput drops to 0, causing queue increase and resume later in about 30mins. Below are stackdriver metrics

Here you can see streaming operation drops around 5:03pm, and all the way to 0. Then close to 5:24pm it went back to normal (it went really high because we discard stale messages).

Undelivered messages shows no one is consuming the topic

On publishing side traffic is slowly ramping up but nothing unusual. I shut down the publisher after seeing the issue and that's why undelivered message remains flat.
The fleet is running on GAE Flex with a fix number of instances. MaxOustandingMessages is set to 100 and the blocking is very unlikely resides in business logic code given that we see no errors and all instance metrics were normal.
I'm trying to get repro but just wanna throw what I have right now here to see if anyone seeing similar issues.
 Bankq
Bankq
All 25 comments
So you have multiple instances all in the middle of a Receive, and they all blocked at the same time?
 jba
on 19 Dec 2017
jba
on 19 Dec 2017
@jba yes. that makes it very unlikely to be a client bug. I'm trying to find what causes this and why Receive is not failing but hanging there.
Bankq
on 19 Dec 2017
@jba I just checked my quota it seems I'm way over cap. It shows all streamingpull api calls end with response code 503. How does Receive suppose to work if none of the streamingpull call fails?
Bankq
on 19 Dec 2017
we have the similar issue. The job stops pulling suddenly, and then resumes pulling after several hours. Multiple jobs are showing the same behavior.
 junghoahnsc
on 19 Dec 2017
junghoahnsc
on 19 Dec 2017
OK, here's a theory. We retry when we see ResourceExhausted, which is what happens when you run out of quota. Unfortunately, there is no way to set a deadline on that retry. So we will retry forever, until you have quota again.
Usually I think this works out OK: if you're a little over quota, you can just wait a bit. I guess if you go way over, the waiting can take a while.
We're open to suggestions of how to improve this behavior. @pongad Can you Go's behavior with Java's?
jba
on 19 Dec 2017
@jba thanks! That was what I thought too. I confirmed with my customer support last night that per PubSub's team, response code 503 is expected when close a connection that has been idle for 30 minutes. From my perspective, it was working before throughput suddenly drops, despite being over quota for quite some time (wasn't even aware of quota issue before the incident!). Also noticed later I have a streamingpull number of open connections quota limit set to 200 but I'm not sure what that means and where am I since I can't find any graph/metrics from console.
I'm waiting for PubSub's team's further investigation on this particular case meanwhile trying to pick you brain to see if you ever experienced a similar behavior.
FWIW during the incident I have a another fleet in AWS that experienced no issue at all (although they subscribe to a different topic). So far I've only been experiencing issues with GAE Flex.
Bankq
on 19 Dec 2017
This issue doesn't seem to be same as ours since we don't hit the quota at all.
junghoahnsc
on 19 Dec 2017
@junghoahnsc that's what I was saying: it's not quota related per PubSub team. Is your application running on GAE Flex? I only see message delay issue on Flex.
Bankq
on 19 Dec 2017
@Bankq oh I see. Yes, it's on GAE Flex.
junghoahnsc
on 19 Dec 2017
@jba is sub.Receive suppose to be a daemon? Does it need to be reinvoked regularly? I'm asking cuz I'm seeing hanging issue usually lasts around 30mins and suspect it might relate to idle connections?
Bankq
on 19 Dec 2017
@Bankq You should call sub.Receive once and let it run as long as you need to (maybe for the life of your application). You don't have to reinvoke it. I'm not sure what you mean by "daemon," but sub.Receive will block, so if you want to do other things in your program you should call it in a goroutine.
jba
on 28 Dec 2017
@jba The 30 minutes is a little suspicious. It's the amount of time that the pubsub server will close the stream. Receive should realize this and open a new one. Perhaps the re-connect logic is broken somehow?
 pongad
on 3 Jan 2018
pongad
on 3 Jan 2018
@pongad on this note I do observe that occasionally I'll see delayed messages (receiveTime - publishTime > 120secs). Every time it happens it lasts around 30min.
We acknowledge the messages when we finish processing it and set MaxExtension to 60seconds. Also if a node takes longer than 60 seconds to process a job it alerts.
Thus my conclusion is occasionally I'm receiving some messages that are published more than 120seconds ago. What would be recommended way to better debug this?
cc: @jba
Bankq
on 4 Jan 2018
@pongad another observation is during the issue, Oldest Unacknowledged Message goes up to 10minutes, meanwhile I have a default AckDeadline with 10 seconds and MaxExtension with 60 seconds. Not sure how to explain this (the only "10 minutes" I know is the maximum allowed ack deadline).
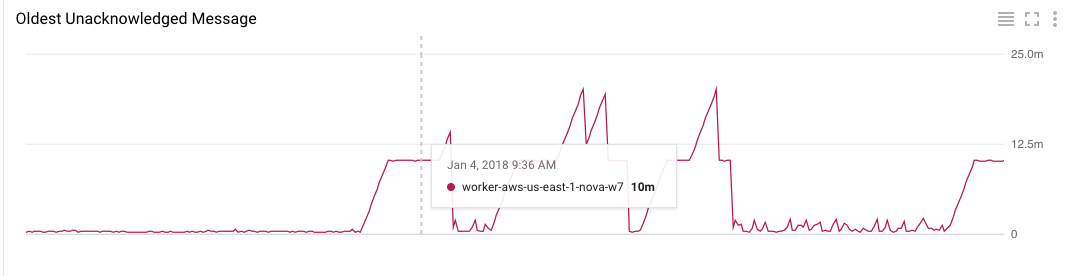
Bankq
on 4 Jan 2018
@pongad, I tried to reproduce a problem with Receive when the server closes the stream. I couldn't.
@Bankq, I'm not sure we'll be able to make progress without a way to repro or gather more data. Do you think you could add some logging or metrics around here so we could see for sure if retries play a role? In other words, it would be interesting to know if Receive is hung waiting to read from the stream, or if it is hung trying to re-connect to a broken stream.
jba
on 4 Jan 2018
@jba thanks for looking into this!
I'll report back with either a repro or more metrics/logging.
Btw does https://github.com/GoogleCloudPlatform/google-cloud-go/issues/830#issuecomment-355399763 ring any bells on your end?
Bankq
on 4 Jan 2018
@jba I thought about this a little more. In both Go and Java (and probably other langs), the reconnection logic is quite complex. While I don't see anything wrong in the implementations, I can't really prove they work in my head.
I created a bit of a toy program here. The setting is simplified and I don't have a formal proof of correctness, but I think it's a step in the right direction. Adopting a simplification like this could be a lot of work however. It plays badly with the internal iterator abstraction, and I don't see an easy way to rip the iterator out.
I'm quite low on free cycles at the moment, but I'll try to make myself useful :)
pongad
on 5 Jan 2018
@pongad Yes, something like having another goroutine that just handles stream connectedness would probably simplify the Go logic.
jba
on 5 Jan 2018
Just wanted to chime in and say that we believe that we are encountering the same issue.
We have 8 threads with their own receive functions that pull from 8 different subscriptions. What we've noticed is that periodically one of the 8 types will stop getting data, but because Receive doesn't return we are unable to catch this edge case and we start falling behind. After a manual restart we start pulling from all 8 subscriptions again.
We've confirmed we aren't hitting any quotas, and the issue seems to be isolated to a subscription as multiple instances will stop receiving data from the same subscription. We are also running in GCE and not GAE.
We are more than willing to help capture any debug information if you have any advice on where to focus our efforts, we will continue digging on our own as well.
 jrbury
on 10 Jan 2018
jrbury
on 10 Jan 2018
@jrbury Thank you for the info. This does look like the same bug. This CL should fix this.
pongad
on 11 Jan 2018
That CL was submitted on January 12, and we just tagged v0.18.0, which includes it. Are you still experiencing the problem?
jba
on 22 Jan 2018
@jba I will update to 0.18.0 and report back if we're still experiencing the issue
jrbury
on 22 Jan 2018
@jba I haven't seen the issue for 48 hours since updating sdk. We usually see it every couple of hours before. Looks very promising that v0.18.0 fixed the issue. However, I still haven't been able to either reproduce the issue or found the underlying cause.
Bankq
on 31 Jan 2018
spoke too soon. It just happened again. Looking into details
Bankq
on 31 Jan 2018
I got confirmation from GCP Pub/Sub team that it's due to a issue of stream handling on server side. Close this issue now. Thanks again for the help Jonathan @jba and Michael @pongad !
Bankq
on 12 Feb 2018
Related issues
 philippgille
·
3Comments
philippgille
·
3Comments
 rileykarson
·
4Comments
junghoahnsc
·
4Comments
rileykarson
·
4Comments
junghoahnsc
·
4Comments
 3cham
·
3Comments
3cham
·
3Comments
 GlennAmmons
·
3Comments
GlennAmmons
·
3Comments
Most helpful comment
@jrbury Thank you for the info. This does look like the same bug. This CL should fix this.