Go: runtime: test timeouts / deadlocks on OpenBSD after CL 232298
There appears to be an uptick in test timeouts (perhaps deadlocks?) in the OpenBSD and NetBSD builders on or around CL 232298. Since that CL affects runtime timers, we should investigate the failures to see whether it introduced a regression that could account for these timeouts.
2020-10-27T18:38:48-f0c9ae5/netbsd-amd64-9_0
2020-10-27T18:23:46-e3bb53a/openbsd-amd64-62
2020-10-27T18:13:59-3f6b1a0/netbsd-386-9_0
2020-10-27T18:13:59-3f6b1a0/netbsd-amd64-9_0
2020-10-27T18:13:59-3f6b1a0/openbsd-amd64-62
2020-10-27T17:24:42-8fdc79e/openbsd-amd64-62
CC @ALTree @ChrisHines @ianlancetaylor @aclements
 bcmills
bcmills
All 53 comments
Looks like it may also affect Windows: TestTicker failed there once too.
2020-10-27T22:57:36-b4b0144/windows-amd64-longtest
2020-10-27T20:03:25-d68c01f/netbsd-386-9_0
2020-10-27T19:52:40-c515852/netbsd-386-9_0
bcmills
on 28 Oct 2020
Given that it's happening significantly on OpenBSD 6.2 and not at all on OpenBSD 6.4, it may be a problem with the old OpenBSD version or the amount of resources it has.
An important difference between those two builders, beyond the OpenBSD version, is that the 6.4 builder was configured to significantly improve performance at the cost of disabling Spectre/Meltdown mitigations (see https://github.com/golang/build/commit/31ed75f74635bc739ba5a817b37317579192d506 and https://github.com/golang/build/commit/d3ddf67ac5c858c99152a37bce5bcf8bce820d06).
CC @golang/release.
 dmitshur
on 29 Oct 2020
dmitshur
on 29 Oct 2020
Looks like x/sync/semaphore may trigger the same issue:
2020-10-20T16:03:32-67f06af/openbsd-386-62
2020-10-20T16:03:32-67f06af/openbsd-amd64-62
bcmills
on 29 Oct 2020
Just a thought: it may be worth stress testing this under the lock rank checker on these OSes. The dashboard only runs lock rank checking on Linux.
 aclements
on 29 Oct 2020
aclements
on 29 Oct 2020
Looping in @mknyszek , since he's pretty familiar with the timer code.
aclements
on 29 Oct 2020
Looping in @mknyszek , since he's pretty familiar with the timer code.
Thanks. I have looked at most of the failures linked above and first impressions are that it's clearly not breaking the same way every time. The panic dumps look like a collection of blocked goroutines that are not consistent across failures. My first guess would be a missed thread wakeup somewhere leaving the runtime's P's under serviced. I haven't been able to do an in depth analysis or testing yet.
I also wonder if I missed something when rebasing to resolve conflicts with https://go-review.googlesource.com/c/go/+/259578/, so any help @prattmic could give double checking that would be appreciated.
 ChrisHines
on 29 Oct 2020
ChrisHines
on 29 Oct 2020
I also wonder if I missed something when rebasing to resolve conflicts with https://go-review.googlesource.com/c/go/+/259578/, so any help @prattmic could give double checking that would be appreciated.
I took a look at that rebase when I had to rebase http://golang.org/cl/264477 around your change, and it seems OK to me, but I'll take another look.
 prattmic
on 29 Oct 2020
prattmic
on 29 Oct 2020
I'm stress testing lock ranking on openbsd-amd64-62 now:
gopool create -setup 'gomote push $VM && gomote run $VM go/src/make.bash' openbsd-amd64-62
stress2 -p 8 -timeout 30m gopool run gomote run -e GOEXPERIMENT=staticlockranking \$VM go/bin/go test -short runtime
No luck so far, though. I'm not even getting the failures that are showing up at ~100% on the dashboard.
aclements
on 29 Oct 2020
I'm able to get occasional timeouts by running all.bash on openbsd-amd64-62, but haven't had any luck getting any useful extra information yet.
prattmic
on 30 Oct 2020
It's slow going, but I've at least confirmed that we do indeed seem to be missing timer expirations. From one timeout:
##### GOMAXPROCS=2 runtime -cpu=1,2,4 -quick
SIGQUIT dump:
now 14797966987748
p 0 status 0 timer0When 14737961925384
p 1 status 0 timer0When 0
p 2 status 0 timer0When 14719523766726
p 3 status 0 timer0When 14719549356203
SIGQUIT: quit
PC=0x47ab5f m=18 sigcode=0
...
All 3 of these timers should have expired 60-80s before this test failed, but didn't (unless I've missed a place where we leave expired timers in timer0When).
prattmic
on 30 Oct 2020
Hi, the issue can be reproduced by the following command on linux/amd64:
../../bin/go test -count 4 -bench BenchmarkWithTimeout
 erifan
on 2 Nov 2020
erifan
on 2 Nov 2020
Thanks for that tip @erifan. Using that I was able to reproduce a deadlock pretty reliably. Setting some debug env vars (GODEBUG=schedtrace=1000 GOTRACEBACK=system) I was able to get a pretty rich picture of the issue. Here is a full console log of a trial built from commit 8fdc79e18a9704185bd6471b592db1e8004bd993.
Note that although I set the -test.timeout=30s that doesn't seem to work since the runtime gets deadlocked and timers aren't serviced. So on the run linked above I aborted the program after about 13s with ctrl-\.
When I look at the stack traces I am seeing a deadlock related to memory allocation. Most of the Ps have status _Pgcstop, except P1 is _Pgidle. Meanwhile most of the Ms are blocked without an associated P. Three Ms are interesting:
M5: p=0 curg=1672 mallocing=0 throwing=0 preemptoff= locks=0 dying=0 spinning=false blocked=true lockedg=-1
M1: p=-1 curg=-1 mallocing=0 throwing=0 preemptoff= locks=0 dying=0 spinning=false blocked=false lockedg=-1
M0: p=-1 curg=-1 mallocing=1 throwing=1 preemptoff= locks=2 dying=1 spinning=false blocked=true lockedg=-1
The stack trace for G1672 is disappointing:
goroutine 1672 [running]:
goroutine running on other thread; stack unavailable
created by testing.(*B).RunParallel
/Users/chines209/gotip/go/src/testing/benchmark.go:768 +0x19e
Most all other stack traces show goroutines in a runnable state blocked on something trying to allocate or a function entry point, which I am guessing means they are blocked waiting for the GC, which isn't making progress for some reason.
Maybe someone else can tease more information out of the report I've provided. Next step for me when I have some time is to revive some of the runtime debuglog code I preserved from when I was working on the timer changes in CL 232298. I've rebased that code and posted it at https://github.com/ChrisHines/go/tree/dlog-backup if anyone else wants to give that a try. proc.go on that branch has a lot of useful dlog() calls that are all commented out. Uncommenting a useful subset of them and increasing const debugLogBytes = 16 << 10 in debuglog.go to a higher value proved useful to me to trace the scheduler in the past.
ChrisHines
on 2 Nov 2020
Trying the same test on the prior commit I did not observe any deadlocks after several attempts.
ChrisHines
on 2 Nov 2020
Now that we have a local reproducer, would it make sense to roll back CL 232298 until it can be diagnosed and fixed?
bcmills
on 2 Nov 2020
FWIW, we got a couple hits on the vanilla linux-*-longtest builders too:
2020-11-02T15:23:43-d5388e2/linux-amd64-longtest
2020-10-30T15:25:49-e1faebe/linux-386-longtest
bcmills
on 2 Nov 2020
I've got a case in gdb (thanks for the repro @erifan!) with similar symptoms to @ChrisHines.
One there is in STW, waiting for running Ps to voluntarily stop:
(gdb) bt
#0 runtime.futex () at /usr/local/google/home/mpratt/src/go/src/runtime/sys_linux_amd64.s:580
#1 0x0000000000433c97 in runtime.futexsleep (addr=0x653308 <runtime.sched+264>, val=0, ns=100000) at /usr/local/google/home/mpratt/src/go/src/runtime/os_linux.go:50
#2 0x000000000040d239 in runtime.notetsleep_internal (n=0x653308 <runtime.sched+264>, ns=100000, ~r2=<optimized out>) at /usr/local/google/home/mpratt/src/go/src/runtime/lock_futex.go:201
#3 0x000000000040d311 in runtime.notetsleep (n=0x653308 <runtime.sched+264>, ns=100000, ~r2=<optimized out>) at /usr/local/google/home/mpratt/src/go/src/runtime/lock_futex.go:224
#4 0x000000000043cede in runtime.stopTheWorldWithSema () at /usr/local/google/home/mpratt/src/go/src/runtime/proc.go:1077
#5 0x000000000046d4c6 in runtime.systemstack () at /usr/local/google/home/mpratt/src/go/src/runtime/asm_amd64.s:375
#6 0x000000000043d180 in ?? () at /usr/local/google/home/mpratt/src/go/src/runtime/signal_unix.go:1031
#7 0x00007f3a70000020 in ?? ()
#8 0x0000000000800000 in ?? ()
#9 0x0000000000000000 in ?? ()
sched.stopwait is 1 (we are waiting for one P to stop).
Meanwhile:
(gdb) p (*'runtime.allp'.array[0]).status
$4 = 3
(gdb) p (*'runtime.allp'.array[1]).status
$5 = 0
(gdb) p (*'runtime.allp'.array[2]).status
$6 = 3
(gdb) p (*'runtime.allp'.array[3]).status
$7 = 3
(gdb) p (*'runtime.allp'.array[4]).status
$8 = 3
(gdb) p (*'runtime.allp'.array[5]).status
$9 = 3
(gdb) p (*'runtime.allp'.array[6]).status
$10 = 3
(gdb) p (*'runtime.allp'.array[7]).status
$11 = 3
(gdb) p (*'runtime.allp'.array[8]).status
$12 = 3
(gdb) p (*'runtime.allp'.array[9]).status
$13 = 3
(gdb) p (*'runtime.allp'.array[10]).status
$14 = 3
(gdb) p (*'runtime.allp'.array[11]).status
$15 = 3
P1 is in _Pidle. This indicates some kind of race. This P either should have been put in _Pgcstop directly by stopTheWorldWithSema, or it should have placed itself into _Pgcstop before sleeping.
prattmic
on 2 Nov 2020
@bcmills The rollback will be a bit messy due to conflicting changes that have gone in since, but I'll prepare a CL.
prattmic
on 2 Nov 2020
Change https://golang.org/cl/267198 mentions this issue: Revert "runtime: reduce timer latency"
 gopherbot
on 2 Nov 2020
gopherbot
on 2 Nov 2020
I am not getting any deadlocks if I run with GOGC=off either. Further indicating a bad interaction with GC.
ChrisHines
on 2 Nov 2020
Capturing a debuglog trace as I described above it looks like the stuck P is blocked in gcstopm probably on the call to lock(&sched.lock) since _p_.status = _Pgcstop has not happened yet. In my trace gcstop was called from schedule after a call to gopreempt_m.
So it looks like a deadlock on sched.lock may be the culprit, but not sure where the other lock holder is yet.
ChrisHines
on 2 Nov 2020
I'm getting close: the immediate cause is the new wakep in wakeNetPoller.
Here, P 9 is acquired by that wakep and then never put into GC stop. I don't immediately see a problem with this path, so I'll take a look to see if the new/woken M is ever running at all.
[7.668090062 P 0] pidleget: P 9
0x449fdb [runtime.pidleget+0x1db /usr/local/google/home/mpratt/src/go/src/runtime/proc.go:5654]
0x440f84 [runtime.startm+0x184 /usr/local/google/home/mpratt/src/go/src/runtime/proc.go:2229]
0x441465 [runtime.wakep+0x65 /usr/local/google/home/mpratt/src/go/src/runtime/proc.go:2363]
0x442eb1 [runtime.wakeNetPoller+0x51 /usr/local/google/home/mpratt/src/go/src/runtime/proc.go:2893]
0x45a76a [runtime.addtimer+0xca /usr/local/google/home/mpratt/src/go/src/runtime/time.go:263]
0x46ed8a [time.startTimer+0x2a /usr/local/google/home/mpratt/src/go/src/runtime/time.go:207]
0x483890 [time.AfterFunc+0x90 /usr/local/google/home/mpratt/src/go/src/time/sleep.go:162]
0x4cafef [context.WithDeadline+0x2cf /usr/local/google/home/mpratt/src/go/src/context/context.go:451]
0x4cb62a [context.WithTimeout+0x6a /usr/local/google/home/mpratt/src/go/src/context/context.go:503]
0x526086 [context_test.benchmarkWithTimeout.func2+0xa6 /usr/local/google/home/mpratt/src/go/src/context/benchmark_test.go:75]
0x4e5398 [testing.(*B).RunParallel.func1+0x98 /usr/local/google/home/mpratt/src/go/src/testing/benchmark.go:775]
0x471ba0 [runtime.goexit+0x0 /usr/local/google/home/mpratt/src/go/src/runtime/asm_amd64.s:1367]
[7.668097089 P 6] STW: start
[7.668114454 P 6] STW: Waiting for 11 Ps
[7.668117434 P -1] releasep: idle P 11
[7.668117852 P -1] gcstopm: gcstop P 11
[7.668118156 P -1] releasep: idle P 7
[7.668118280 P -1] releasep: idle P 10
[7.668118684 P -1] releasep: idle P 8
[7.668118700 P -1] gcstopm: gcstop P 10
[7.668119072 P -1] gcstopm: gcstop P 8
[7.668119912 P -1] gcstopm: gcstop P 7
[7.668122248 P -1] releasep: idle P 0
[7.668122595 P -1] gcstopm: gcstop P 0
[7.668123196 P -1] releasep: idle P 1
[7.668123212 P -1] releasep: idle P 2
[7.668123652 P -1] gcstopm: gcstop P 2
[7.668123967 P -1] gcstopm: gcstop P 1
[7.668125721 P -1] releasep: idle P 4
[7.668126063 P -1] gcstopm: gcstop P 4
[7.668126517 P -1] releasep: idle P 5
[7.668127019 P -1] gcstopm: gcstop P 5
[7.668221635 P -1] releasep: idle P 3
[7.668222008 P -1] gcstopm: gcstop P 3
[P 9 never stops...]
@ChrisHines interesting, can you actually see the M owning the P in gcstopm?
As a continuation of above, what I'm seeing is that the stuck idle P is sitting an m.nextp in the M it is supposed to be running on:
(gdb) p (*'runtime.allp'.array[4]).status
$5 = 0
(gdb) p ('runtime.allp'.array[4])
$7 = (runtime.p *) 0xc000038000
(gdb) p ('runtime.p'*)(*(('runtime.m'*)(*'runtime.allm').schedlink)).nextp
$15 = (runtime.p *) 0xc000038000
This M is still sitting in mPark:
Thread 3 (Thread 0x7f8116bb2700 (LWP 4192516)):
#0 runtime.futex () at /usr/local/google/home/mpratt/src/go/src/runtime/sys_linux_amd64.s:580
#1 0x0000000000435d46 in runtime.futexsleep (addr=0xc000054950, val=0, ns=-1) at /usr/local/google/home/mpratt/src/go/src/runtime/os_linux.go:44
#2 0x000000000040f1bf in runtime.notesleep (n=0xc000054950) at /usr/local/google/home/mpratt/src/go/src/runtime/lock_futex.go:159
#3 0x000000000043f699 in runtime.mPark () at /usr/local/google/home/mpratt/src/go/src/runtime/proc.go:1297
#4 0x0000000000440d32 in runtime.stopm () at /usr/local/google/home/mpratt/src/go/src/runtime/proc.go:2210
#5 0x000000000044230e in runtime.findrunnable (gp=0xc000038000, inheritTime=false) at /usr/local/google/home/mpratt/src/go/src/runtime/proc.go:2858
#6 0x0000000000443657 in runtime.schedule () at /usr/local/google/home/mpratt/src/go/src/runtime/proc.go:3065
#7 0x0000000000443bdd in runtime.park_m (gp=0xc00060e480) at /usr/local/google/home/mpratt/src/go/src/runtime/proc.go:3214
#8 0x000000000046fdbb in runtime.mcall () at /usr/local/google/home/mpratt/src/go/src/runtime/asm_amd64.s:323
#9 0x00007f8108000020 in ?? ()
#10 0x0000000000800000 in ?? ()
#11 0x0000000000000000 in ?? ()
AFAICT, this is a general problem with M wakeup: it would seem that the notewakeup in startm simply didn't wake the M. However, that would be very surprising to me since the CL didn't really change anything around that.
One thought is that the CL did remove a startm from sysmon on timer expiration. It's possible that this wakeup bug existed before, but sysmon was kicking another M awake eventually. However, that still doesn't explain how the stuck M would get unstuck (it needs to put the P in gcstop before execution can continue).
prattmic
on 2 Nov 2020
Ah, I think I figured it out: startm takes ownership of the P from pidleget, puts it in mp.nextp, and then is preempted on call to notewakeup for its gcstop [1]. The ownership of the idle P is now in limbo, as there is nothing to put it into gcstop.
Sure enough, adding acquirem/releasem to startm to disable preemption makes the hangs go away (at least so far).
That said, I don't know what this bug really has to do with the original CL.
[1] This could also happen on any other call after pidleget.
prattmic
on 2 Nov 2020
Change https://golang.org/cl/267257 mentions this issue: runtime: always call startm on the system stack
gopherbot
on 2 Nov 2020
Thanks to @aclements and @mknyszek: the reason this CL trips up on this issue is that it introduces the first preemptible call to startm. Before this CL, all calls were already on the system stack and thus not preemptible.
prattmic
on 2 Nov 2020
@prattmic I am finding the same behavior here. For example, in this case P 17 was the stuck P:
[0.109546131 P 15] startm claim P 17 for M 17
[0.109546873 P 15] gopreempt_m G 1096 M 11
[0.109564601 P 11] stopTheWorldWithSema gcing
[0.109565223 P 11] signaling preemption for G 1079 on P 0 on M 16
[0.109565811 P 0] gopreempt_m G 1079 M 16
[0.109569695 P 11] signaling preemption for G 1097 on P 1 on M 29
[0.109570060 P 1] gopreempt_m G 1097 M 29
[0.109573633 P 11] signaling preemption for G 1108 on P 2 on M 21
[0.109573887 P 2] gopreempt_m G 1108 M 21
[0.109577135 P 11] signaling preemption for G 1089 on P 3 on M 7
[0.109577479 P 3] gopreempt_m G 1089 M 7
[0.109580959 P 11] signaling preemption for G 1078 on P 4 on M 15
[0.109581553 P 4] gopreempt_m G 1078 M 15
[0.109585512 P 11] signaling preemption for G 1102 on P 5 on M 12
[0.109586052 P 5] gopreempt_m G 1102 M 12
[0.109589976 P 11] signaling preemption for G 1116 on P 6 on M 35
[0.109590632 P 6] gopreempt_m G 1116 M 35
[0.109594136 P 11] signaling preemption for G 1122 on P 7 on M 3
[0.109594435 P 7] gopreempt_m G 1122 M 3
[0.109598334 P 11] signaling preemption for G 1081 on P 8 on M 25
[0.109598934 P 8] gopreempt_m G 1081 M 25
[0.109602854 P 11] signaling preemption for G 1117 on P 9 on M 31
[0.109603316 P 9] gopreempt_m G 1117 M 31
[0.109607104 P 11] signaling preemption for G 1076 on P 10 on M 13
[0.109607362 P 10] gopreempt_m G 1076 M 13
[0.109610936 P 11] signaling preemption for G 1083 on P 12 on M 24
[0.109612396 P 12] gopreempt_m G 1083 M 24
[0.109615062 P 11] signaling preemption for G 1124 on P 13 on M 20
[0.109616059 P 13] gopreempt_m G 1124 M 20
[0.109619478 P 11] signaling preemption for G 1113 on P 14 on M 19
[0.109619796 P 14] gopreempt_m G 1113 M 19
[0.109623780 P 11] signaling preemption for G 1093 on P 15 on M 11
[0.109625658 P 15] gopreempt_m G 1093 M 11
[0.109627348 P 11] signaling preemption for G 1115 on P 16 on M 0
[0.109629183 P 16] gopreempt_m G 1115 M 0
[0.109631242 P 11] signaling preemption for G 1082 on P 25 on M 22
[0.109631990 P 25] gopreempt_m G 1082 M 22
[0.109651735 P 0] schedule stopping for GC M 16
[0.109658744 P 1] schedule stopping for GC M 29
[0.109664307 P 2] schedule stopping for GC M 21
[0.109669077 P 3] schedule stopping for GC M 7
[0.109674709 P 5] schedule stopping for GC M 12
[0.109679822 P 4] schedule stopping for GC M 15
[0.109684558 P 7] schedule stopping for GC M 3
[0.109691593 P 8] schedule stopping for GC M 25
[0.109698169 P 6] schedule stopping for GC M 35
[0.109704428 P 10] schedule stopping for GC M 13
[0.109711273 P 9] schedule stopping for GC M 31
[0.109716885 P 12] schedule stopping for GC M 24
[0.109723725 P 13] schedule stopping for GC M 20
[0.109732296 P 14] schedule stopping for GC M 19
[0.109737186 P 15] schedule stopping for GC M 11
[0.109741955 P 16] schedule stopping for GC M 0
[0.109745648 P 25] schedule stopping for GC M 22
Thanks for the bug fix. 🥇
ChrisHines
on 2 Nov 2020
I ran into issues with openbsd-amd64-62 still failing on https://golang.org/cl/267257 after switching from systemstack() to acquirem(), leading me to believe I may have misunderstood the issue. After more testing, it appears that the systemstack() approach can also fail on openbsd-amd64-62.
https://golang.org/cl/267257 is definitely fixing a real issue, so I'll go ahead with it, but unfortunately I don't think that is the only bug here.
prattmic
on 4 Nov 2020
I've been slowly debugging further openbsd issues on trybots (no luck on gomote :(). Sample failure: https://storage.googleapis.com/go-build-log/a89e0973/openbsd-amd64-62_559bc97d.log
I don't have much in terms of details yet, but I can say that these aren't stuck waiting for STW like the previous failures.
prattmic
on 4 Nov 2020
I was investigating #42379 and I believe I found a way to reproduce this issue via gomote quite reliably. Please see https://github.com/golang/go/issues/42379#issuecomment-722054437 for details.
dmitshur
on 5 Nov 2020
Thanks @dmitshur, that is extremely helpful. I can now test much faster and collect runtime traces (which I was trying to hack into trybot output last night 🙈).
The trace is quite telling (2 bad traces I've collected so far look the same):
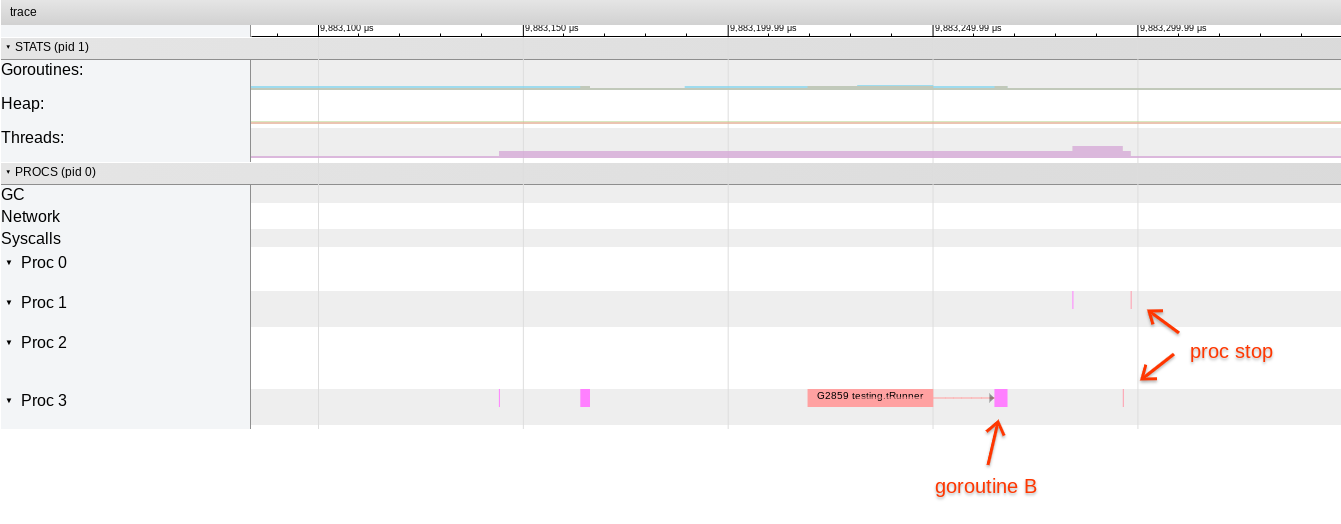
On the left side, we can see TestSelectDuplicateChannel running. It starts goroutine B, then enters this 1ms sleep, and the entire runtime goes to sleep (should wake in 1ms).
Two minutes later sysmon wakes forcegchelper. This gets a P running, which (presumably) notices the expired 1ms timer and continues execution of the test.

From this it is pretty clear we are missing timer expirations. It seems like the obvious immediate cause of this is that sysmon no longer calls startm for expired timers. It is not yet clear to me if this is a problem due to an error in http://golang.org/cl/232298, or a pre-existing issue catching timers that sysmon wakeups were masking (this would not at all surprise me).
prattmic
on 5 Nov 2020
That is interesting. Questions I have:
- Is there a spinning M or one in the netpoller when P3 entered the 1ms sleep?
- If so, did it get woken to observe the new timer?
- If not, did P3's M calculate an appropriate
pollUntilvalue and enter the netpoller itself?
The brief start/stop cycle of P1 in the second screen shot above implies wakep->startm was called by P3. One of those two M's should have found the timer and entered the netpoller with the associated pollUntil value. Did they not notice the timer, or did the netpoller fail to wake on time?
ChrisHines
on 5 Nov 2020
The windows-amd64-longtest failure is also not fixed by CL 267257.
2020-11-05T19:22:02-370682a/windows-amd64-longtest
Silver lining: at least that gives us pretty good confidence that the remaining bug is also not specific to OpenBSD‽
bcmills
on 5 Nov 2020
I think I've figured it out.
Here's the log:
# Non-blocking netpoll
[4.329701056 P 1] netpoll: M 10 delay 0 ts.tv_sec 0 ts.tv_nsec 0
# kqueue(2) returns
[4.329728713 P 1] netpoll: M 10 kqueue = 0
# M 7 enters netpoll with 781ns timeout
[4.330284929 P -1] findrunnable: M 7 netpoll pollUntil 2969255628548 delta 781 now 2969255627767
[4.330375444 P -1] netpoll: M 7 delay 781 ts.tv_sec 0 ts.tv_nsec 781
# kqueue(2) never returns!!!!
...
# modtimer for test 1ms sleep
[129.063108051 P 0] modtimer: M 4 t 0xc0003b80a0 when 3093989454242
...
# Found next timer (the one above).
[129.063198566 P 0] findrunnable: M 4 checkTimers now 3093988547829 pollUntil 3093989454242
# Don't enter netpoll: another M is in netpoll
# Don't netpollBreak: other M's netpoll pollUntil expires sooner than ours.
[129.063238236 P -1] findrunnable: M 4 don't netpoll break: pollerPollUntil 2969255628548 <= pollUntil 3093989454242
[129.063253601 P -1] findrunnable: M 4 stopm
[129.063266172 P -1] mPark: park M 4
... Nothing until force gc wakeup ...
When performing the sleep, we don't enter netpoll because we see another M is in netpoll with an earlier expiration. But look closer at that pollerPollUntil expiration: it was minutes ago and should have already expired!
Back at the beginning of the log, that netpoll entered kqueue(2) with a 781ns timeout and simply never returned. Uh oh.
Every case I've seen stuck in kqueue(2) is with a very short timeout (e.g., <1000ns). This sounds an awful lot like a kernel bug that might have been fixed by https://github.com/openbsd/src/commit/a36f8271cbe1fe2c9def06c66e3a077f13a6f19c (which was committed between OpenBSD 6.2 and 6.4 (6.4 is passing)). That commit claims that timeout <1us should have been a poll rather than blocking, but perhaps that's not quite accurate?
I suspect the fix here is going to be to force short delays either to 0ns or 1000ns, which I'll try now.
prattmic
on 5 Nov 2020
Aha, the fix was actually in https://github.com/openbsd/src/commit/c9604848bb4e9be45966dba9590f2331e15e0b53.
Prior to this commit, they checked timespec.tv_nsec == 0 for "no timeout" rather than timeval.tv_usec == 0. i.e., they were checking before timespec -> timeval truncation instead of after.
Before (code), tv_nsec < 1000 would result in atv.tv_usec = 0, timeout = 0, the same values as tsp == NULL (blocking call).
Thus far, pinning delay < 1000ns to no timeout has fixed the hangs.
prattmic
on 5 Nov 2020
Change https://golang.org/cl/267885 mentions this issue: runtime: non-blocking netpoll for delay <1us on openbsd
gopherbot
on 5 Nov 2020
https://golang.org/cl/267885 is a workaround to avoid this kernel issue. It is very simple, but will probably be a very slight perf regression for newer versions of OpenBSD, as they will spin in netpoll for <1us timers rather than blocking in the kernel.
Another option would be to do nothing and drop support for OpenBSD <6.4, as that is more than two releases old per https://github.com/golang/go/wiki/OpenBSD#longterm-support. I don't know if this is a big enough issue to warrant that though, or if we'd need to give a cycle or two of announcement.
cc @golang/release
prattmic
on 5 Nov 2020
@bcmills looks like this issue is quite specific to OpenBSD. :) We'll have to take a look at Windows separately.
prattmic
on 5 Nov 2020
@prattmic, in that case I've filed #42424 separately to track the remaining issue, on the theory that each issue should track only one root cause. (That way, we can mark this issue as closed once the BSD builders are sorted out.)
bcmills
on 6 Nov 2020
@prattmic, any idea whether the NetBSD kernel has the same bug as OpenBSD? (https://build.golang.org/log/28fcb871ec9f9d01d787eec2c5f32f38450d5774 on netbsd-arm64-bsiegert was after your CL landed.)
CC @bsiegert
bcmills
on 6 Nov 2020
https://golang.org/cl/267885 is a workaround to avoid this kernel issue. It is very simple, but will probably be a very slight perf regression for newer versions of OpenBSD, as they will spin in netpoll for <1us timers rather than blocking in the kernel.
Another option would be to do nothing and drop support for OpenBSD <6.4, as that is more than two releases old per https://github.com/golang/go/wiki/OpenBSD#longterm-support. I don't know if this is a big enough issue to warrant that though, or if we'd need to give a cycle or two of announcement.
OpenBSD only supports the last two releases - that is currently 6.8 (released last month) and 6.7 (released May 2020). Anything older (6.6 and earlier) are unsupported and no longer receive reliability or security fixes. Based on previous discussions, Go should target the same - there is little gained by intentionally supporting OpenBSD 6.6 or earlier, or running builders with EOL releases (in fact the opposite is true - Go risks running into problems by not running builders for supported releases).
 4a6f656c
on 6 Nov 2020
4a6f656c
on 6 Nov 2020
@prattmic @4a6f656c I came here to suggest/ask something similar.
If we've determined here that the Go code is correct and this issue is due to a kernel bug in OpenBSD 6.2 which has been fixed in OpenBSD 6.4, then I think we should drop the builders.
The primary reason we still have OpenBSD 6.4 and 6.2 builders is because we didn't have enough bandwidth to get them updated more frequently (the last update was in 2018, see CL 139857 and CL 143458). If the builder health were at 100%, we would have OpenBSD 6.8 and 6.7 builders for the supported versions of OpenBSD. (Issue #35712 is about adding a OpenBSD 6.8 builder.)
If all this sounds right, I think we should add to Go 1.16 release notes that Go 1.16 requires at least OpenBSD 6.4, and disable the builder for Go 1.16 and newer. Opened #42426 for that.
dmitshur
on 6 Nov 2020
@bcmills From a quick glance at the NetBSD source, it looks fine. I can try testing there and see what I can find.
prattmic
on 6 Nov 2020
The primary reason we still have OpenBSD 6.4 and 6.2 builders is because we didn't have enough bandwidth to get them updated more frequently (the last update was in 2018, see CL 139857 and CL 143458). If the builder health were at 100%, we would have OpenBSD 6.8 and 6.7 builders for the supported versions of OpenBSD. (Issue #35712 is about adding a OpenBSD 6.8 builder.)
@dmitshur - please let me know if you need assistance - while I can readily update the script that produces the OpenBSD images, I would not have the ability (at least as far as I know) to actually deploy the new builders, so would need someone from the Go team to push it over the line.
If all this sounds right, I think we should add to Go 1.16 release notes that Go 1.16 requires at least OpenBSD 6.4, and disable the builder for Go 1.16 and newer. Opened #42426 for that.
Sounds good to me.
4a6f656c
on 6 Nov 2020
For easier testing, I created this simple test case. tl;dr, all the systems I tested seem fine expect for OpenBSD 6.2.
#include <errno.h>
#include <inttypes.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/event.h>
#include <sys/time.h>
int64_t nanoseconds(const struct timespec* ts) {
return ts->tv_sec * 1000 * 1000 * 1000 + ts->tv_nsec;
}
int64_t nanotime(void) {
struct timespec ts;
int ret = clock_gettime(CLOCK_MONOTONIC, &ts);
if (ret < 0) {
perror("clock_gettime");
exit(1);
}
return nanoseconds(&ts);
}
void do_kevent(int kq, const struct timespec* timeout) {
int64_t start = nanotime();
if (timeout != NULL) {
printf("%" PRId64 ": %" PRId64 "ns timeout...\n", start, nanoseconds(timeout));
} else {
printf("%" PRId64 ": NULL timeout...\n", start);
}
fflush(stdout);
struct kevent event;
errno = 0;
int ret = kevent(kq, NULL, 0, &event, 1, timeout);
int64_t end = nanotime();
printf("%" PRId64 ": kevent = %d, %d (took %" PRId64 "ns)\n", end, ret, errno, end-start);
fflush(stdout);
}
int main(int argc, char** argv) {
// Die if we hang.
alarm(5);
int kq = kqueue();
if (kq < 0) {
perror("kqueue");
exit(1);
}
struct timespec ts;
ts.tv_sec = 0;
ts.tv_nsec = 0;
do_kevent(kq, &ts);
ts.tv_sec = 0;
ts.tv_nsec = 500;
do_kevent(kq, &ts);
ts.tv_sec = 0;
ts.tv_nsec = 1000;
do_kevent(kq, &ts);
ts.tv_sec = 1;
ts.tv_nsec = 0;
do_kevent(kq, &ts);
// Expect to hang.
do_kevent(kq, NULL);
return 0;
}
Results:
openbsd-amd64-62 (buggy!):
$ MOTE=user-mpratt-openbsd-amd64-62-0 bash -c 'gomote put ${MOTE} ~/Downloads/kqueue.c && gomote run ${MOTE} /usr/bin/clang -o kqueue kqueue.c && gomote run ${MOTE} ./kqueue'
1627543870910: 0ns timeout...
1627544323482: kevent = 0, 0 (took 452572ns)
1627544343037: 500ns timeout...
Error running run: signal: alarm clock
openbsd-amd64-64:
$ MOTE=user-mpratt-openbsd-amd64-64-0 bash -c 'gomote put ${MOTE} ~/Downloads/kqueue.c && gomote run ${MOTE} /usr/bin/clang -o kqueue kqueue.c && gomote run ${MOTE} ./kqueue'
237994200170: 0ns timeout...
237994807203: kevent = 0, 0 (took 607033ns)
237994812267: 500ns timeout...
238006095872: kevent = 0, 0 (took 11283605ns)
238006132626: 1000ns timeout...
238026102134: kevent = 0, 0 (took 19969508ns)
238026124456: 1000000000ns timeout...
239036098928: kevent = 0, 0 (took 1009974472ns)
239036123229: NULL timeout...
Error running run: signal: alarm clock
(N.B. alarm expected here; NULL should hang forever)
netbsd-amd64-9_0:
$ MOTE=user-mpratt-netbsd-amd64-9_0-0 bash -c 'gomote put ${MOTE} ~/Downloads/kqueue.c && gomote run ${MOTE} /usr/bin/gcc -o kqueue kqueue.c && gomote run ${MOTE} ./kqueue'
229687432330: 0ns timeout...
229687493302: kevent = 0, 0 (took 60972ns)
229687496804: 500ns timeout...
229703566876: kevent = 0, 0 (took 16070072ns)
229703584739: 1000ns timeout...
229723596147: kevent = 0, 0 (took 20011408ns)
229723613393: 1000000000ns timeout...
230734957755: kevent = 0, 0 (took 1011344362ns)
230735056352: NULL timeout...
Error running run: signal: alarm clock
freebsd-amd64-12_0:
$ MOTE=user-mpratt-freebsd-amd64-12_0-0 bash -c 'gomote put ${MOTE} ~/Downloads/kqueue.c && gomote run ${MOTE} /usr/bin/clang -o kqueue kqueue.c && gomote run ${MOTE} ./kqueue'
188217590805: 0ns timeout...
188217636051: kevent = 0, 0 (took 45246ns)
188217637761: 500ns timeout...
188217655127: kevent = 0, 0 (took 17366ns)
188217657050: 1000ns timeout...
188217670601: kevent = 0, 0 (took 13551ns)
188217672169: 1000000000ns timeout...
189228987829: kevent = 0, 0 (took 1011315660ns)
189229006286: NULL timeout...
Error running run: signal: alarm clock
darwin-amd64-10_15:
$ MOTE=user-mpratt-darwin-amd64-10_15-0 bash -c 'gomote put ${MOTE} ~/Downloads/kqueue.c && gomote run ${MOTE} /usr/bin/clang -o kqueue kqueue.c && gomote run ${MOTE} ./kqueue'
3819989126000: 0ns timeout...
3819989197000: kevent = 0, 0 (took 71000ns)
3819989202000: 500ns timeout...
3819989218000: kevent = 0, 0 (took 16000ns)
3819989223000: 1000ns timeout...
3819989239000: kevent = 0, 0 (took 16000ns)
3819989241000: 1000000000ns timeout...
3820999322000: kevent = 0, 0 (took 1010081000ns)
3820999375000: NULL timeout...
Error running run: signal: alarm clock
dragonfly-amd64-5_8:
$ MOTE=user-mpratt-dragonfly-amd64-5_8-0 bash -c 'gomote put ${MOTE} ~/Downloads/kqueue.c && gomote run ${MOTE} /usr/bin/gcc -o kqueue kqueue.c && gomote run ${MOTE} ./kqueue'
2574121283184035: 0ns timeout...
2574121283245496: kevent = 0, 0 (took 61461ns)
2574121283276226: 500ns timeout...
2574121294009713: kevent = 0, 0 (took 10733487ns)
2574121294199402: 1000ns timeout...
2574121314043824: kevent = 0, 0 (took 19844422ns)
2574121314370960: 1000000000ns timeout...
2574122324036714: kevent = 0, 0 (took 1009665754ns)
2574122324235063: NULL timeout...
Error running run: signal: alarm clock
@prattmic, the observed builder failures on NetBSD have been on the arm64 (not amd64) builder — did you check that configuration?
bcmills
on 6 Nov 2020
Hmm, actually, there's one on netbsd-386-9_0 now too:
https://build.golang.org/log/8f6922ad5c468e77a32e18757775ddf709219705
bcmills
on 6 Nov 2020
(So... do we need a separate issue to track the NetBSD deadlock?)
bcmills
on 6 Nov 2020
I shall leave no stone unturned, so I just ran the test of every builder matching (bsd|dragon|darwin). The only failures were openbsd-amd64-62, openbsd-386-62, darwin-amd64-10_11 (didn't compile, missing clock_gettime?).
So, yes, we'll need a new issue for NetBSD.
prattmic
on 7 Nov 2020
darwin-amd64-10_11(didn't compile, missingclock_gettime?)
That builder runs macOS 10.11 El Capitan, and Go 1.14 is the last release that supports it, so it's normal for Go 1.16 to not work on it.
dmitshur
on 7 Nov 2020
https://github.com/golang/go/issues/42402 was closed as a duplicate of this issue.
I recently started seeing hangs when running some benchmarks on ppc64le.
 laboger
on 11 Nov 2020
laboger
on 11 Nov 2020
@laboger , @prattmic , I think we're trying to keep this issue focused on the OpenBSD failure, which is now understood to be specific to an OpenBSD kernel bug. But there are clearly other issues on other platforms. Since @laboger reproduced timer hangs on linux/ppc64le and linux/amd64 in #42402, is #42424 really the right issue to merge that into?
aclements
on 11 Nov 2020
@aclements I agree that #42402 shouldn't be closed as duplicate of this; I've reopened it so it can be investigated.
Given @prattmic's analysis above, that #42426 is in NeedsFix state now and we have other issues for non-OpenBSD issues, I think there's nothing more to do here for OpenBSD in Go 1.16 specifically and this can be closed. Is my understanding right?
dmitshur
on 11 Nov 2020
@dmitshur Correct. There is nothing more than needs to be done here for OpenBSD. #42426 covers it.
prattmic
on 11 Nov 2020
Related issues
 bbodenmiller
·
3Comments
bbodenmiller
·
3Comments
 myitcv
·
3Comments
myitcv
·
3Comments
 rsc
·
3Comments
rsc
·
3Comments
 Miserlou
·
3Comments
Miserlou
·
3Comments
 enoodle
·
3Comments
enoodle
·
3Comments
Most helpful comment
@laboger , @prattmic , I think we're trying to keep this issue focused on the OpenBSD failure, which is now understood to be specific to an OpenBSD kernel bug. But there are clearly other issues on other platforms. Since @laboger reproduced timer hangs on linux/ppc64le and linux/amd64 in #42402, is #42424 really the right issue to merge that into?