Go: database/sql: what would a Go 2 version of database/sql look like?
We're wondering what the story for database/sql might be for Go 2. We agree it's clearly important to be maintained (including ongoing maintenance including but definitely not limited to Google support).
Whether the package lives in std or x/foo is out of scope for this bug. (We'll wait until package management is figured out more first.)
But given what we know now, what would a fresh database/sql look like for Go 2?
Experience reports, docs, API proposals welcome.
@kardianos, could you write up your wishlist?
 bradfitz
bradfitz
All 43 comments
database/sql Go2 wishlist:
- Remove non-context methods.
- Add Context to DB.Close.
- Have a way to pass back a user error and notify the connection pool the connection is bad as well. Differentiate between a bad connection that didn't execute and a bad connection that may have executed and should pass execution back to the client and not retry. It may also be useful to note if the error was caused by a ctx cancel #25829.
- Add hooks to allow connection pool to inform clients when a connection is closed or bad and will removed from pool.
- Remove Stmt as implemented.
- Add a separate implementation of a Stmt pool that uses the above hooks.
- Retain Conn.Prepare, remove other instances of Prepare.
- Remove runtime knobs, replace with conn pool create parameters (or remove the knob altogether).
- Increase observability of connection pool (tracing / metrics).
- Remove deprecated driver interfaces.
- Have all drivers use a driver.Connector (useful for creating a dedicated connection canceler for certain systems, parse DSN only once, and other benefits). Think about making a DSN string parsing optional.
- Possibly allow the driver.Conn.Close to take a context. #38185
- Allow drivers to export a per result-set value converter that can be used by downstream ORMs in conjunction with the built-in value converter.
database/sql suggested exploration topics prior to Go2:
- [x] Determine best way to scan rows from a cursor from value or OUT param.
- Look into a more flexible way to get data out of driver rows:
- Support zero alloc "scans".
- Use a more generic interface for scanning, allows user to provide method of scan. (?)
- Standardize generic table buffer. (?)
- Investigate experiments: https://godoc.org/github.com/golang-sql/sqlexp
- Value quoter
- Return raw messages and notices
- Savepoints
- Nested transactions
- Better support for Decimal, Date, DateTime, and Time types.
Experience Reports
 kardianos
on 14 Nov 2017
kardianos
on 14 Nov 2017
Be more efficient, the interface should make
zero allocimplement possible. I found that direct use github.com/go-sql-driver/mysql (and make some modifies to make it to make itzero allocand it iszero allocindeed after the modify) without the database/sql interface stuff, is 20% faster with the localhost mysql server with small dataset. Here is what to be done to make itzero alloc:- Add A special []byte type version Db.Query/Db.Exec/Stmt.Query/Stmt.Exec/Rows.Scans method to avoid
interface alloc/slice allocon every Query/Exec method call. Thedatabase/sqlshould provide a way that the input and output data set do not need type conversion to avoid alloc instrconv.Itoaortime.Parse. Just copy that input []byte direct to database network connection and take part of the inner output []byte buffer to the output [][]byte slice should makezero allocpossible. - Add
Rows.ColumnLen() intto avoidslice allocon every Query method call. - Add struct type
sql.Resultto avoidinterface allocon every Exec method call. It should look liketype Result struct {; AffectedRows int64; InsertId int64}https://github.com/go-sql-driver/mysql/blob/master/result.go#L11 - Bind and reuse a
*sql.Rowson a*sql.driverConnto avoidalloc *sql.Rowson every Query method call.
- Add A special []byte type version Db.Query/Db.Exec/Stmt.Query/Stmt.Exec/Rows.Scans method to avoid
Make
database/sql.Rowseasier to understand and to be called. It should more likedatabase/sql/driver.Rows.database/sql.Rowscan have a callback foreach method likefunc (rows *Rows) Foreach(cb func(rowList [][]byte)error) errorto make the interface much more easier to use.The
database/sql.Openshould be deleted. How do i pass a custom net.Dialer to the driver? How do I pass a callback to the driver? How do i manually marshal dataSourceName? How do i escape some chars in the url? Should I use json in dataSourceName? How to create a db object should be managed by driver implement to make the interface more easy to use.(more struct stuff, less string/marshal/unmarshal stuff)- Add the
MaxConnectionIdleTimeOption.Db.SetConnMaxLifetimeis useless, SetConnMaxLifetime just set the max time of a connection from the startTime.I think the max time of a connection from last Idle, should be a good solution to gc the useless tcp connection after a huge traffic. - Delete
Db.SetConnMaxLifetime,Db.SetMaxIdleConns,Db.SetMaxOpenConns. they should be set at the begin of the database object created. I do not have any need to change the database object config after the object created. If you want another config of the database object, just close old one and create a new one. - Add a
*sql.StmtPool so that the caller do not need implement one again.
About sql.Stmt
- I need
*sql.Stmtto avoid sql injection attack and make the input parameter escape absolute right.If other stuff can be easier, safe, correct and fast.I will choose the easier one. - Cache
*sql.Stmtcan increase the performance of mysql. But store every queries as*sql.Stmtwill reach the max number Statments(may be 16k) of mysql server.So I only use them with point select/replace/delete and gc the*sql.StmtPool if the pool is too large. The biggest problem of*sql.StmtPool is that I do not know the real Statments usage. I can only know the*sql.Stmtnumber.
 bronze1man
on 14 Nov 2017
bronze1man
on 14 Nov 2017
"Some database servers have limits on how many prepared statements can be prepared at once."
Here is a config in mysql called max_prepared_stmt_count. it is 16382 by default. And the prepared_stmt is in connection scope.If I only prepared one statement, it may cost 200 of the max count when I use 200 connections.
https://dev.mysql.com/doc/refman/5.7/en/sql-syntax-prepared-statements.html
I need gc the *sql.Stmt Pool and prepare last query again, if mysql return an error says there is too many stmt. (Error 1461: Can't create more than max_prepared_stmt_count statements (current value: 16382))
Here is the *sql.Stmt pool code I currently use.
func IsErrorMsgTooManyPreparedStmt(errMsg string) bool{
// Error 1461: Can't create more than max_prepared_stmt_count statements (current value: 16382)
return strings.Contains(errMsg,"Error 1461: Can't create more than max_prepared_stmt_count statements")
}
type Ci struct{
Query func(query string, args ...interface{}) (*sql.Rows, error)
Exec func(query string, args ...interface{}) (sql.Result, error)
Prepare func(query string) (*sql.Stmt, error)
db *Db
IsInTransaction bool
stmtCacheMap map[string]*stmtCacheEntry
lastStmtCacheTime uint64
stmtCacheLocker sync.Mutex
}
type stmtCacheEntry struct{
stmt *sql.Stmt
key string
lastUseTime uint64
}
func (ci *Ci) cleanPrepareCache(){
ci.stmtCacheLocker.Lock()
ci.stmtCacheMap = map[string]*stmtCacheEntry{}
ci.stmtCacheLocker.Unlock()
}
func (ci *Ci) prepareWithCache(query string) (stmt *sql.Stmt, err error){
ci.stmtCacheLocker.Lock()
ci.lastStmtCacheTime++
thisStmtCacheTime:=ci.lastStmtCacheTime
if ci.stmtCacheMap==nil{
ci.stmtCacheMap = map[string]*stmtCacheEntry{}
}
entry:= ci.stmtCacheMap[query]
// 已经有缓存,直接使用。
if entry!=nil{
entry.lastUseTime = thisStmtCacheTime
ci.stmtCacheLocker.Unlock()
return entry.stmt,nil
}
ci.stmtCacheLocker.Unlock()
for i:=0;i<3;i++{
stmt,err=ci.Prepare(query)
if err!=nil{
if IsErrorMsgTooManyPreparedStmt(err.Error()){
// 可能客户端实例太多,此处遇见太多stmt的报错后,就关闭自己的一般stmt,以便后面的程序可以继续进行。
// 由于每一个连接会把用到过的 stmt 都创建一遍。所以即使把 stmt限制设置的很小。也依然会 报这个问题。
ci.stmtCacheLocker.Lock()
ci.gcNotUsePrepare__NOLOCK(len(ci.stmtCacheMap)/2)
ci.stmtCacheLocker.Unlock()
continue
}
return nil,err
}
}
if err!=nil{
return nil,err
}
ci.stmtCacheLocker.Lock()
oldEntry:=ci.stmtCacheMap[query]
if oldEntry==nil{
if len(ci.stmtCacheMap)>= ci.db.req.StmtCacheMaxQueryNum{
ci.gcNotUsePrepare__NOLOCK(ci.db.req.StmtCacheMaxQueryNum/2)
}
entry = &stmtCacheEntry{
stmt: stmt,
key: query,
lastUseTime: thisStmtCacheTime,
}
ci.stmtCacheMap[query] = entry
ci.stmtCacheLocker.Unlock()
return entry.stmt,nil
}else{
// 可能另一个线程已经初始化好了,此处直接使用。
ci.stmtCacheLocker.Unlock()
stmt.Close()
entry = oldEntry
entry.lastUseTime = thisStmtCacheTime
return entry.stmt,nil
}
}
func (ci *Ci) gcNotUsePrepare__NOLOCK(toNumber int){
currentNumber:=len(ci.stmtCacheMap)
if currentNumber==0 || currentNumber<=toNumber{
return
}
stmtCacheList:=make([]*stmtCacheEntry, len(ci.stmtCacheMap))
i:=0
for _,entry:=range ci.stmtCacheMap{
stmtCacheList[i] = entry
i++
}
// 时间越早越放在后面。
kmgSort.InterfaceCallbackSortWithIndexLess(stmtCacheList,func(i int,j int)bool{
return stmtCacheList[i].lastUseTime>stmtCacheList[j].lastUseTime
})
for _,entry:=range stmtCacheList[toNumber:]{
entry.stmt.Close()
delete(ci.stmtCacheMap,entry.key)
}
}
- The only reason I cache a
*sql.Stmtis performance. It can increase performance if the query string is same. So I never use Stmt inside a transaction. It is too complex and almost no performance gain (the query inside one transaction do not repeat in my use case) for me. By the way, I do not even know why the prepare stuff exist, the mysql server should do the query parse cache itself and make query string and input parameters in the same round trip or just let me pass the sql ast to mysql server(marshal a sql string is just difficult and unsafe.). - Looks like I just merge DB.Query/Db.Exec and Tx.Query/Tx.Exec into one interface, And write some generic logic on top of them. It will be better if
database/sqljust merge DB.Query/Tx.Query into one method on some struct so the caller do not need implement it again.
bronze1man
on 15 Nov 2017
Scan query results directly to a struct
 gale93
on 15 Nov 2017
gale93
on 15 Nov 2017
Scan query results directly to a struct
Doesn't work in the general case with NULL values.
 cznic
on 15 Nov 2017
cznic
on 15 Nov 2017
@cznic RE struct NULLs: Yes, we would need some type of strategy for handling that, but I could envision the actual struct scan code provided by a user settable interface, so rather then trying to cover all scanning cases, we provide one or two default ones, but then allows users to provide their own specific one as well.
kardianos
on 15 Nov 2017
It seems like database/sql has had a lot of issues over the past few years around data races and goroutine leaks, more so than the other standard library packages. I worry that there's something fundamental in the design of the package as it's currently constructed that makes it difficult to write correct code. Maybe it's just that we're asking it to do a lot and support a lot of different use cases and backends. But I am wondering if the design or API's could be altered to make it easier to write a correct implementation.
I have long wished for some type of unified, cross-database API for reporting the constraint failures that are features of most databases:
- Not null constraint failure
- Uniqueness constraint failure
- Foreign key reference failure
- Check constraint failure
- Enum not known
- Type failure (inserted a number where a UUID was expected, or whatever)
The fact that each database reports these differently makes it difficult for e.g. ORM's to properly handle constraint failures. Instead of just issuing an INSERT and waiting for the constraint failure, Rails starts a transaction, issues a SELECT, checks the number of rows, and throws if a row already exists. It would be cool if database/sql just returned you the uniqueness constraint on an INSERT failure instead of an err you had to cast to a pq.Error or whatever else. I tried to get into this a little bit with this talk. https://kev.inburke.com/slides/feral-concurrency
I tried to address this a little bit with https://github.com/shyp/go-dberror, which attempted to wrap the existing database error in a more friendly message. Presumably that could be extended to handle more backends and more classes of errors.
 kevinburke
on 15 Nov 2017
kevinburke
on 15 Nov 2017
RE struct NULLs: Yes, we would need some type of strategy for handling that
Without knowing any other context about the data model, there's only one safe strategy in this case: refuse to continue scanning and panic.
cznic
on 15 Nov 2017
@kevinburke Re database/sql reliability: yes, the pool and stmt code are too interconnected with everything else, it would be great to be able to have some of that code in internal sub-packages.
Interesting idea to classify error types (constraint failures). I've done similar things to provide more useful DB error information as well.
kardianos
on 15 Nov 2017
@bronze1man
By the way, I do not even know why the prepare stuff exist, the mysql server should do the query parse cache itself and make query string and input parameters in the same round trip
Indeed. MS SQL Server and Oracle (probably others) don't benefit from a separate prepare step; you send the SQL text and parameters in the same message and will reuse recent cached query plans by matching similar SQL text. Even postgresql can have an anonymous prepared query that can be prepared and executed in a single round trip. MySQL now has the protocol X that probably supports similar. This is why I never personally use *sql.Stmt; it adds a real cost without offering a benefit (for me and the systems I use).
*sql.Stmt also add significant complication to the internal database/sql code base.
kardianos
on 15 Nov 2017
I tried doing it the regular way and with *sql.Stmt. When I benchmarked one of my main joins, *sql.Stmt ended up being 30% faster on MySQL. I'm curious as to what it would be like on this new protocol.
 Azareal
on 20 Nov 2017
Azareal
on 20 Nov 2017
@Azareal
There are four ways to send sqls to mysql:
- merge 1000+ sqls into one sql.(use Db.Query/Db.Exec)
- embed data in sql. (use Db.Query/Db.Exec)
- cache
*sql.Stmtand reuse it with different parameters (use Stmt.Query/Stmt.Exec) - create a new
*sql.Stmtand use it and close the*sql.Stmt. (use Db.Query/Db.Exec)
From what I benched with same data and ssd disk and table size bigger than the machine memory.
- The first one is usually 10-100 times faster then the remain three, but it may not work in all situations.(like the request only contain one row of data)(because of less transaction stuff? or less sql parse stuff?)
- The second one and the three are usually 30%-100% faster the the fourth one.
You should benchmark all four ways if you want to increase your database speed.
bronze1man
on 21 Nov 2017
@kardianos MySQL's X Protocol does parameterized queries without preparing, plus allows more data types like arrays (eg. WHERE x IN (?) looks possible, only tried scalars so far) and objects.
Also can prepare & execute in one round trip.
Turns out whilst the protobufs for the protocol supports binding arrays to parameters, MySQL (5.7.20) doesn't like it.
 renthraysk
on 24 Nov 2017
renthraysk
on 24 Nov 2017
I've updated my previous comment with wishlist: https://github.com/golang/go/issues/22697#issuecomment-344095510 .
kardianos
on 27 Nov 2017
Ah, I should add that values that can be null in the database are a particular problem. Assuming you need to distinguish between null values and the empty value (which I do), either you have to have one version of your struct that talks to the database and has e.g. sql.NullTime, and then another one for serializing to JSON, or you use something like e.g. https://godoc.org/github.com/kevinburke/go-types#NullTime that has MarshalJSON support. (or Protobuf support, or whatever you're using...)
kevinburke
on 27 Nov 2017
@kevinburke Yeah, you would need to be able to encode null-state into a separate struct field or within the existing value space (null==-1). But I would envision having an user settable interface that would enable something like that.
kardianos
on 27 Nov 2017
@kevinburke, Embedding sql.Null* types in a struct seems unnecessary. Just scan into a local sql.Null* type variable and map it manually into a struct instance.
renthraysk
on 27 Nov 2017
For DB fields that allow NULL, and mapping a record to a struct, couldn't you just require that field to be a pointer? e.g. name VARCHAR(200) DEFAULT NULL and scanning to a struct type MyRow struct { name *string }, if name in DB is NULL then name on struct is null, if name in DB is NOT NULL then name on struct is a string. And if you have a NULL value but the field is not a pointer type you panic. I believe https://github.com/jmoiron/sqlx supports this in addition to sql.NullString
 ryan0x44
on 27 Nov 2017
ryan0x44
on 27 Nov 2017
I want to stop the bike shedding about scanning from NULLABLE columns now. There are many valid strategies each with different trade offs.
I don't want conversation about different strategies for scanning from nullable columns. Here is what I do want:
proposal kardianos/1
// This is an example proposal of about what I'd like to see discussed here. Note, no mention of actual
// strategy to deal with NULLs or other issues. Rather it is flexible enough to handle multiple different
// strategies.
//
// This isn't well thought out, but it is the general direction I'm leaning to.
package sql
var ErrNULL = errors.New("value is NULL")
// ResultTable is provided by the sql package per result table.
// While it is an interface in this example, a final implementation would almost certainly
// be a concrete struct with methods.
type ResultTable interface {
ColumnCount() int
Names() []string
// Other methods for fetching column types.
// Scan column index into value. If column value is NULL and the provided type
// cannot be scanned into, returned error will be ErrNULL.
//
// A value must only be scanned once to allow the driver to forget the value
// after scanning. Values must be scanned sequentially (index may never descend)
// or repeat).
Scan(index int, value interface{}) error
// NextRow returns false when no more rows exist to be scanned.
// NextRow must be called before Scan is called.
NextRow() (bool, error)
// DoneResult will move on to the next result set if available, even if additional
// row may still be read.
// Once called, no other methods should be called.
DoneResult() error
}
// Scanner is provided by the user. While there is a default implementation, that looks like
// the original Scan method, it is more flexible to record multiple result sets, ordered messages,
// and multiple errors.
type Scanner interface {
// LastInsertID is called zero or one times. Value may be an int32, int64, string, or []byte.
LastInsertID(value interface) error
// Scan is called for each table in the result set.
Scan(r ResultTable) error
// Message is called for each non-error message (NOTICE) returned.
Message(v string) error
// Error is called for each SQL level error returned.
Error(v Error) error
}
// The scanner is passed directly into the Query method.
func (db *DB) Query(ctx context.Context, sql string, into Scanner) error {...}
package mypackage
import (
"database/sql"
// This package can decide specific NULL handling policy.
// The standard sql package would also have a few scanners as well to choose from.
"super-sql/scan"
)
func main() {
db, err := sql.Open("pg", "DSN")
// Scan into struct.
list := []struct{
ID int64 `scan: "value,-1"`,
Name string `scan: "field,NameNULL"`,
NameNULL bool
}{}
err = db.Query(ctx, "select ID, Name from Account;", scan.IntoSlice(&list))
// Scan into variables like it is currently possible.
res := sql.Result()
err = db.Query(ctx, "select ID, Name from Account;", res)
for res.Next() {
var id int64
var name string
err = res.Scan(&id, &name)
}
// Scan into generic table buffer.
set := table.Set() // List of tables.
err = db.Query(ctx, "select ID, Name from Account;", set)
}
In other words, a specific NULL strategy doesn't matter any more. We define an interface for scanning, then users can plug in their own strategy, as they effectively do anyway today.
kardianos
on 27 Nov 2017
@kardianos
I think we can just put a ScanToByteSlice(fn function([][]byte)) error To the sql.Result, and let other package to do the other stuff.
bronze1man
on 28 Nov 2017
@bronze1man Are the arguments to fn a row of []byte encoded values? That would be too DB specific, this needs to be after the value get's interpreted as a concrete type. One of the potential values of not passing in the entire row at a time is you only need to interpret a single value at a time, and you could skip interpreting a returned value if it is not requested.
kardianos
on 28 Nov 2017
@kardianos
The interface ScanToByteSlice(fn function([][]byte)) error is the one that can be implemented fast, you can put inner network byte slice buffer direct to this fn arguments if I just want a mysql varchar/blob type from the select result. As other type , strconv.Itoa/strconv.FormatBool format should be good. And you can put a nil []byte to say the return value is NULL value.
When I need a no-type database interface, Just let me do the type transfer job.
The type system in database/sql make the function package in my client code complex. So I only use []byte/string and parse the string in my code if I want get a string and marshal my int to the string if I want. I can write a type transfer stuff myself.
I used to convert the result of select sql to []map[string]string . The type []map[string]string simple the process of the result of select sql. Unmarshal the result to a struct may not solve this kind of simple interface problem.
DB specific may be not a problem. My client code of mysql and sqlite3 is different too. They have different sql syntax. The consistent sql interface just do not exist, different sql server always have different sql syntax.
One of the potential values of not passing in the entire row at a time is you only need to interpret a single value at a time, and you could skip interpreting a returned value if it is not requested.
The caller can also put less stuff in his select sql. If you want less data, you can just ask less data.
bronze1man
on 29 Nov 2017
@bronze1man That is a layer violation. If change is made, it would be allowing various row scanning strategies (into struct, into value, into table, etc) and it would not include decoding the value itself. I won't discuss that point further here (feel free to email me or discuss on golang-sql if you disagree and would like to show your point).
kardianos
on 29 Nov 2017
I’ve noticed that there may be a possibility that I’m changing my SQL statements or scan variable data types depending on the actual database I’m using for the same application. Switching is something I'll be doing in the future.
There seems to be a lot of implementation at the database/sql level above the driver, maybe we’re losing capability for specific database systems that would have been exposed in independent packages without the database/sql constraints. I don't have an example.
For my first round with https://github.com/lib/pq I've had no problems. But maybe a driver client library instead of a generic library would make more sense for features and performance?
 pciet
on 10 Dec 2017
pciet
on 10 Dec 2017
In https://github.com/golang/go/issues/21659 I said:
My thought is change *DB to a struct of reference/pointer types and call methods on an sql.DB instead, where the context is an optional field assigned before making these calls to Exec, Ping, Prepare, Query, and QueryRow in which there’s an if DB.context != nil { block with the context handling behavior.
This pattern means the API surface is minimized while allowing for context-like additions in the future without API growth besides an exposed struct field or getter/setter pair.
pciet
on 17 Dec 2017
sql.DB is currently thread safe and I don’t believe that your proposed
design would be.
On Sat, Dec 16, 2017 at 15:03 Matt Juran notifications@github.com wrote:
In #21659 https://github.com/golang/go/issues/21659 I said:
My thought is change *DB to a struct of reference/pointer types and call
methods on an sql.DB instead, where the context is an optional field
assigned before making these calls to Exec, Ping, Prepare, Query, and
QueryRow in which there’s an if DB.context != nil { block with the context
handling behavior.This pattern means the API surface is minimized while allowing for
context-like additions in the future without API growth besides an exposed
struct field or getter/setter pair.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/golang/go/issues/22697#issuecomment-352217925, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AAOSI_OHb9QSmzBlgfGtW5eNPAKbaHePks5tBExFgaJpZM4Qcdex
.>
--
Kevin Burke
925.271.7005 | kev.inburke.com
kevinburke
on 17 Dec 2017
My suggesting requires these fields be changed to pointer types:
type DB struct {
numClosed *uint64
mu *sync.Mutex
nextRequest *uint64
numOpen *int
closed *bool
The change calls for a benchmark to prove either approach is more performant (one dereference versus a five, one pointer on the stack versus the entire struct), but this is an approach to cleanly growing the API surface.
Setting request context on a sql.DB-typed struct doesn't make much sense without documentation about how your function's instance of the DB is separated from others. A partial solution would be to only do it for Tx.
pciet
on 17 Dec 2017
Okay, i was about to post a wall of text suggesting that Stmt should be the ONLY interface (that is, instead of deleting Stmt, delete everything else), because it fits with database/sql being the only SQL API I've seen that makes doing SQL the correct way the only way (in every situation other than statement preparation, such as row scanning and connection pooling), and would also allow things like catching non-constant strings in SQL calls in golint.
But some of the comments above suggest that I should be able to, say, write
var db *sql.DB
db.Query("SELECT name FROM people WHERE id = ?;", id)
and it wouldn't have any of the security vulnerabilities that not using prepared statements would also have? No chance for injection or string rewriting or anything? Does database/sql itself currently do named parameter substitution, or is that done on the server side? And what about percent syntax in these calls? Is there a General Standard Rule for this that makes Stmt unnecessary? I am now thoroughly confused.
 andlabs
on 31 Jan 2018
andlabs
on 31 Jan 2018
@andlabs The SQL you posed is perfectly fine. Parameters in queries will either use the databases immediate query execution passing in parameters separately, or it will first prepare a stmt in the background (trip 1) and then execute that stmt with the parameters (trip 2). Explicit Stmts have the disadvantage to many systems they require two trips, when many systems support parameter queries with a single trip. Furthermore, better SQL plan matching on any modern systems makes explicit stmts nearly obsolete. Not only that, most (all?) systems have limits on the number of Stmts that can be defined at once, which can lead to problems for larger mature system that prepare stmts from the application manually. Many systems support server side stored procedures (sprocs) which become part of the database schema as much as tables and views. Many organizations I've worked in mandate using server side stored procedures. To call these procedures, you would call db.QueryContext(ctx, "pr_insert_widget", uuid, name, color) without a client side Stmt at all.
database/sql never parses or alters the SQL string provided; parameters provided are always sent to the server individually (doing so is hard to do well for SQLite SQL, T-SQL, PL/SQL (Postgres vs Oracle), DB2, and they have different placeholder syntax and identifier escape syntax). A "General Standard Rule" for when Stmt is unnecessary? Anytime the database protocol / interface supports sending the SQL and parameters together it should be used. If you are inserting a modest 10 000 000 rows into a database, first look for a bulk ingestion method. Failing that, ensure you wrap all the inserts with a single (or batched) transaction. You could make a Stmt for the insert SQL and in some cases for some systems that might matter, but generally your disk IO is going to dominate (thus the transaction size is important, though other factors such as dropping indexes before bulk insert can be equally important). But latency is in wire and disk, so minimize both regardless; parsing a query and finding a cached query plan is cheap.
Useful reading may include:
- http://use-the-index-luke.com/blog/2011-07-16/planning-for-reuse
- https://docs.microsoft.com/en-us/sql/t-sql/language-reference
- https://docs.oracle.com/cd/B28359_01/appdev.111/b28370/toc.htm
- https://www.postgresql.org/docs/9.6/static/protocol-flow.html#PROTOCOL-FLOW-EXT-QUERY
- https://dev.mysql.com/doc/internals/en/x-protocol-use-cases-use-cases.html
kardianos
on 31 Jan 2018
Change https://golang.org/cl/106659 mentions this issue: database/sql: update interface for Go2
 gopherbot
on 12 Apr 2018
gopherbot
on 12 Apr 2018
Change https://golang.org/cl/126416 mentions this issue: database/sql: allow Scan to work with structs
gopherbot
on 27 Jul 2018
- Add the
MaxConnectionIdleTimeOption.Db.SetConnMaxLifetimeis useless, SetConnMaxLifetime just set the max time of a connection from the startTime.I think the max time of a connection from last Idle, should be a good solution to gc the useless tcp connection after a huge traffic.
Please read this article. http://techblog.en.klab-blogs.com/archives/31093990.html
Some images in the article are disappeared, but can be seen here: https://gist.github.com/methane/5e5324f66245bf27420e111fe4423115
In short, MaxLifetime is much better than MaxIdleConns about closing idle connection efficiently, and solves many other problems too.
MaxIdleTime may be litter better than MaxLifetime about closing idle connections. But it doesn't solve many other problems MaxLifetime solves.
And I'm not sure MaxLifetime is not enough for closing idle connections and MaxIdleTime is really needed. I hadn't seen any benchmark demonstrate MaxLifetime is not enough for closing idle connection in real world apps.
If benefit of MaxIdleTime compared MaxLifetime is not enough, I don't think we shouldn't add it. Writing connection pool right is hard. Adding more option make it more hard.
 methane
on 26 Sep 2018
methane
on 26 Sep 2018
If benefit of MaxIdleTime compared MaxLifetime is not enough, I don't think we shouldn't add it. Writing connection pool right is hard. Adding more option make it more hard.
I have wroten a mysql connection pool with MaxOpenConns and MaxConnectionIdleTime and wait_timeout parameters. It is not so hard as long as those parameters is set at the time the db object is created, and never change after it created. With my own mysql connection pool , the avg connection number of my busiest mysql server reduce more than 30%.
- You can use a buffered chan
make(chan struct{},req.MaxOpenConns)to implement MaxOpenConns. - You can use a goroutine with a for loop to implement MaxConnectionIdleTime or MaxLifetime .
- You can use tcpConn.SetDeadline to implement wait_timeout.
The mysql connection pool in golang package database is complex because those parameters can be changed after the db object is created and it tries to create a new connection in background after an old one is dead because of bad network. (i do not know why it have this logic) .
bronze1man
on 26 Sep 2018
With my own mysql connection pool , the avg connection number of my busiest mysql server reduce more than 30%.
Compared with what? MaxLifetime?
As I wrote in this gist, MaxLifetime can reduce amount of connections when application is idle.
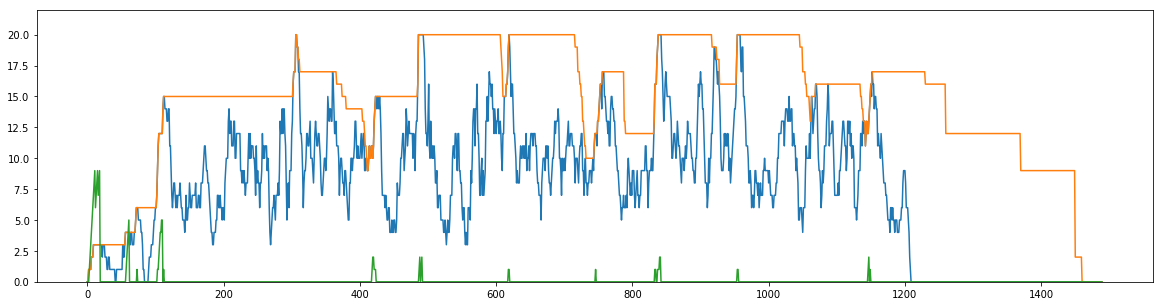
Of course, MaxLifetime cause close&reconnect even for non-idle connections. It is good for load-balanced DB setup, and MySQL variables. There are overhead for reconnection, but I think the overhead should be negligible if MaxLifetime is configured to appropriate value.
I don't know any rational for MaxIdleTime is required "in addition to" MaxLifetime. Why aren't you satisfied with MaxLifetime?
The mysql connection pool in golang package database is complex because those parameters can be changed after the db object is created and it tries to create a new connection in background after an old one is dead because of bad network. (i do not know why it have this logic) .
I agree about this. Prohibiting dynamic configuration will make connection pool much simple and robust, maintainable.
methane
on 26 Sep 2018
Compared with what? MaxLifetime?
As I wrote in this gist, MaxLifetime can reduce amount of connections when application is idle.
Sorry, I do not compare MaxConnectionIdleTime to MaxLifetime , I just compare it to not set them both.
I just "think" MaxConnectionIdleTime may be better than MaxLifetime, because MaxConnectionIdleTime create less connections and it can reduce some stmt create delay with stmt cache which only works on one connection, but i do not have evidence. Maybe they both have the same qps.
bronze1man
on 26 Sep 2018
When is Go 2 version of database/sql going to be released?
 smithaitufe
on 19 Apr 2019
smithaitufe
on 19 Apr 2019
@smithaitufe There is no schedule or plan. This issue exists to gather ideas to create a plan.
 ianlancetaylor
on 19 Apr 2019
ianlancetaylor
on 19 Apr 2019
Scan query results directly to a struct
I perfer go style rather rust style, go style is simple.
 ghost
on 20 Aug 2019
ghost
on 20 Aug 2019
Explore the idea changing the definition of driver.Value from interface{} to an union type.
- Reduces autoboxing.
- Handling NULL is simplified as removes need for NullX types
Seems protobuf is going that direction too. https://github.com/protocolbuffers/protobuf-go/tree/master/reflect/protoreflect
renthraysk
on 29 Sep 2019
fetchALL() would be a critical feature, so that an entire table can be brought into memory for advanced processing. I needed this for some NLP project once. The default way of scanning each row means Cgo and reflect get called every row! this meant it took 8 seconds to read the database table into memory. Pythons fetchall took only 4 seconds.
see https://github.com/mattn/go-sqlite3/issues/379
a fetchall method could do all conversions and memory layout in C, and then GO could just cast it after one cgo call, that way reading an entire table should be similar speed to C
 robert-king
on 6 Mar 2020
robert-king
on 6 Mar 2020
Proposal 1: pass context to all driver methods that might involve blocking network operations.
For example driver.Conn.Close() should accept a context, since the underlying driver might block on this call in case of a network failure. Passing context will allow using timeout defined by the user in the current context because otherwise, the user might hang on the call to database/sql library.
It also applies to driver.Stmt.Close().
Proposal 2: remove the background goroutine that opens and closes connections and do it in the request goroutine instead.
Right now connections get opened/closed from both places: in the request goroutine and in the background goroutine hidden from the user. In the second case database/sql doesn't have the current user context and hence can only pass a background context to the underlying driver that will not contain a user-defined context. Removing the background goroutine will allow to always call driver open/close from the request goroutine and provide timeouts via context that the user might set.
I described this in more detail here: https://github.com/golang/go/issues/38185
 georgysavva
on 21 Jul 2020
georgysavva
on 21 Jul 2020
Is there any reason sql.DB, sql.Tx, sql.Stmt are structs instead of interfaces?
In the current situation it is impossible to write a "middleware" like nap and use it in any existing code which uses standard database/sql (like sqlx). Also opencensus had to write a complicated driver to get telemetry, see ocsql.
I understand that sql.DB is merely doing connection pooling but it works quite well and most people use sql.DB connection pooling instead of doing their own and using database/sql/driver interfaces. So what prevented to use interfaces for sql.DB itself? High-level interfaces would also make testing easier, I guess.
 k3a
on 16 Aug 2020
k3a
on 16 Aug 2020
Have a way to pass back a user error and notify the connection pool the connection is bad as well. Differentiate between a bad connection that didn't execute and a bad connection that may have executed and should pass execution back to the client and not retry. It may also be useful to note if the error was caused by a ctx cancel #25829.
Since Go 1.13 errors can be wrapped. This can give some ideas to improve the error API. For instance, with the addition of errors.As() we could move away from global static Error variables to Error types, wrapping the originating error.
For instance var ErrBadConn = errors.New("driver: bad connection") in the driver package could become:
````
type BadConnErr struct {
reason error
}
func (e BadConnErr) Error() string {
return fmt.Spritf("driver: bad connection: %v", e.reason)
}
func (e BadConnErr) Unwrap() error {
return e.reason
}
````
A driver could then do something like:
if err := ctx.Err(); err != nil {
return nil, BadConnErr{reason: err}
}
Building on the above, we can also start to define other error types, signaling different levels of error in a standard way. For instance:
- Connection errors (eg. Connection has failed, nothing has been committed to the DB)
- Database fatal exception errors (eg. data corruption, out of space)
- Database user exception errors (eg. syntax errors, sql type errors, missing arguments)
For example, if we look to lib/pq its Error type is pretty rich. Then, a caller could assert the error to a pq.Error and obtain the PostgreSQL error code. Those codes are documented here.
In contrast, go-sql-driver/mysql uses a bunch of static error variables.
If one is developer that builds a product that is supposed to be SQL idempotent, it can get messy very quickly. Drivers know best what a certain error signifies. And my idea would be to define these 3 (or perhaps more) levels of Error types. So that a driver can wrap its current errors into them and thus providing a unified error interface to consumers. Whom could then do:
````
if errors.Is(err, context.Canceled) {
// Maybe we want to ignore?
}
if errors.As(err, &BadConnErr) {
// e-mail the sysadmin
}
if errors.As(err, &UserErr) {
log.Printf("You did something wrong: %v", err)
}
````
On a general note, currently it is hard to predict what errors to expect and look out for. This is no unification across drivers. For instance, in case of canceled context. lib/pq just returns context.Canceled as-is. But DATA-HOG/go-sqlmock sometimes return an error containing canceling query due to user request. Resulting in different behaviors between mock tests and production. This might be a bug on sqlmock's side, but I'm just highlighting that currently drivers can do what they want regarding errors and there is no (forced) convention.
I really hope we can improve this by providing boiler plate error types and wrapping.
 muhlemmer
on 14 Oct 2020
muhlemmer
on 14 Oct 2020
Related issues
gopherbot
·
3Comments
 enoodle
·
3Comments
enoodle
·
3Comments
 myitcv
·
3Comments
myitcv
·
3Comments
 natefinch
·
3Comments
natefinch
·
3Comments
 rsc
·
3Comments
rsc
·
3Comments
Most helpful comment
database/sql Go2 wishlist:
database/sql suggested exploration topics prior to Go2:
Experience Reports