Glow: Unexpected results with quantization
Using a simple fully-connected network (784*128*10) on the MNIST dataset, I tested the quantization method proposed in this document. I made the quantization profile using the MNIST training dataset and used it to create quantized bundles targeting different architectures. I then ran the networks on the first 100 images of the MNIST testing dataset and measured the mean time required to do one inference. Here are the results:
Architecture | Not quantized | Quantized
---------------- | ------------------ | --------------
ARM Cortex-A9 | 3304 µs | 9713 µs
ARM Cortex-M7 | 10729 µs | 3725 µs
ARM Cortex-M4 | 20506 µs | 22713 µs
One would expect that the inference time would be less for the quantized versions of the network. But as you can see, this is not the case for Cortex-A9 and Cortex-M4. This is particularly strange for the Cortex-M4 which has a soft float-abi.
Is this a bug or am I doing something wrong?
 byersin
byersin
All 2 comments
@byersin This might surprise you but it is not guaranteed that a quantized model runs faster than a floating-point one. The only direct and controlled impact is memory footprint: a quantized model will use roughly 4x less memory (int8 vs float32).
What does quantization mean: means using integer operations to approximate floating-point operations. There are multiple quantization schemas which accomplish this with different tradeoffs between accuracy (of the approximation) and run-time complexity. For example:
asymmetricschema (default) - best accuracy, worst performancesymmetricschema - moderate accuracy, moderate performancesymmetric_with_power2_scale- worst accuracy, best performance
Just to give you an example of how the math looks like for a floating-point dot-product:
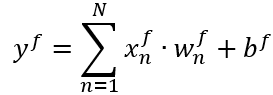
Simple right? This is how it looks like for a quantized implementation using an asymmetric schema:

Not so simple right? We end up with more integer operations for approximating a simple floating-point expression. Some quantization schema get rid of some of the computations by forcing some parameters to 0. The only way to have a faster quantized implementation is to use HW acceleration features like integer SIMD arithmetic, etc which means that you would need some specialized kernels (Glow is using some generic implementations which are not optimized for a particular HW).
Bottom line: quantization only guarantees lower memory footprint. Better performance needs special intervention.
You should try with other quantization schema and observe the results.
 mciprian13
on 11 May 2020
mciprian13
on 11 May 2020
Thank you for your explanation! I still need to do more testing but indeed things are not as straightforward as I expected them to be.
byersin
on 27 May 2020
Related issues
 artemrakhov-glow
·
4Comments
artemrakhov-glow
·
4Comments
 dati91
·
3Comments
dati91
·
3Comments
 alannnna
·
3Comments
alannnna
·
3Comments
 ayermolo
·
3Comments
ayermolo
·
3Comments
 tlepley-cadence
·
4Comments
tlepley-cadence
·
4Comments
Most helpful comment
@byersin This might surprise you but it is not guaranteed that a quantized model runs faster than a floating-point one. The only direct and controlled impact is memory footprint: a quantized model will use roughly 4x less memory (
int8vsfloat32).What does quantization mean: means using integer operations to approximate floating-point operations. There are multiple
quantization schemaswhich accomplish this with different tradeoffs between accuracy (of the approximation) and run-time complexity. For example:asymmetricschema (default) - best accuracy, worst performancesymmetricschema - moderate accuracy, moderate performancesymmetric_with_power2_scale- worst accuracy, best performanceJust to give you an example of how the math looks like for a floating-point dot-product:
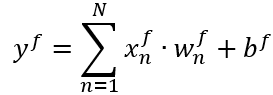

Simple right? This is how it looks like for a quantized implementation using an asymmetric schema:
Not so simple right? We end up with more integer operations for approximating a simple floating-point expression. Some quantization schema get rid of some of the computations by forcing some parameters to 0. The only way to have a faster quantized implementation is to use HW acceleration features like integer SIMD arithmetic, etc which means that you would need some specialized kernels (Glow is using some generic implementations which are not optimized for a particular HW).
Bottom line: quantization only guarantees lower memory footprint. Better performance needs special intervention.
You should try with other quantization schema and observe the results.