Ghidra: PE code cave disassembly
Multiple ShadowHammer samples decrypt their shellcode via a function called from ___crtExitProcess(). The screenshot below is MD5 cdb0a09067877f30189811c7aea3f253.
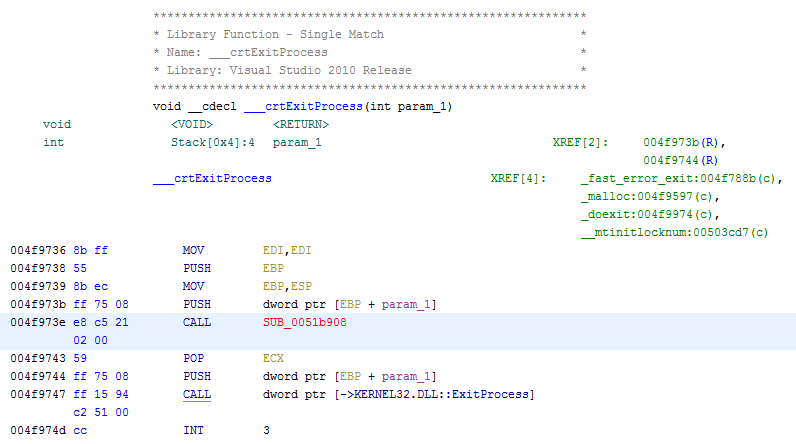
SUB_0051b908 cannot be viewed because it lies within a 511-byte code cave within the .text section. Ghidra sets the .text section boundary based on the VirtualSize (0x0011A801) as shown in the screenshot below. The RawSize of the .text section is 0x0011AA00.

For reference, IDA Pro's segmentation is shown below. It appears to treat everything up to the next section as part of the .text section and attempts to disassemble it.

Expanding the .text section in Ghidra's memory map does not cause it to re-read the file's bytes and undefined bytes are displayed. Outside of modifying the sample's PE header, is there a way to force Ghidra to read and disassemble these bytes?
 mwilliams31
mwilliams31
All 13 comments
No, there is currently not a way to force that. You could write a script that does it though! You'd have to reread in the file because Ghidra doesn't keep around the bytes it didn't load into the address space.
So the extra bytes at the end of the section in the file are actually code and not just all zeros? Do you know if that's common?
 ryanmkurtz
on 4 Apr 2019
ryanmkurtz
on 4 Apr 2019
Thanks for the quick reply Ryan. Correct, the executable bytes at the end of the .text section (0x401000-0x51b800) start at file offset 0x11ac02 (VA: 0x51b802) and end at offset 0x11add5 (VA: 0x5ab9d5). The remaining raw section bytes are NULLs. This type of code execution is uncommon but the technique (code caving) has been around for some time.
mwilliams31
on 4 Apr 2019
No need to read the bytes from the file then...you could just initialize your new memory block to 0 when you create it. This would be a pretty simple script to write.
ryanmkurtz
on 4 Apr 2019
Any thought about changing the way Ghidra loads sections to account for executable code in caves for executable sections?
mwilliams31
on 4 Apr 2019
We'll have to discuss how to best handle this generically. I'll leave this open as an enhancement request.
ryanmkurtz
on 4 Apr 2019
I propose (regardless of this issue) the following:
On the import dialog (where you can select Format, Language, etc.) should be an option to manually adjust the PE header and section fields.
Here is how I currently import the ShadowHammer binary:
- Import the PE binary as
Format: Binary - Run PE annotation analysis.
- Change the header fields. In this case set
.textlength (both virtual and raw) to0x11b000. - Ctrl+A to select the whole binary.
- "Extract and Import ...".
- On that import dialog select
Format: PE
Hope that helps.
A reasonable improvement would also be to mimic the platform loader, i.e., load the binary like Windows would load it. In this case load the PE code cave despite it not being within a section and hence not being loaded.
Isn't there some alignment for PE sections? It is quite possible that Windows follows that alignment but Ghidra doesn't hence not loading the code.
Anyway just my 2 cent.
 0x6d696368
on 8 Apr 2019
0x6d696368
on 8 Apr 2019
So the extra bytes at the end of the section in the file are actually code and not just all zeros? Do you know if that's common?
The extra bytes are code. It's a small shellcode. It is basically the whole malicious part of the binary.
I assume it was placed in that code cave with good reason. It's a malware technique.
Not sure how common, because IDA automatically will include the code outside the .text section into the analysis. But if you are dealing with malware things like that are to be expected and a good tool should handle them.
0x6d696368
on 8 Apr 2019
From running cdb0a09067877f30189811c7aea3f253 with a debugger, I confirmed that the extra bytes get loaded into memory. I'm wondering if this happens when the VirtualSize aligned to the SectionAlignment becomes greater than SizeOfRawData, as @0x6d696368 hinted at.
From a set of 10,000 "clean" PE files I downloaded from VirusTotal a few months back, there were ~7,100 with an executable section where VirtualSize < SizeOfRawData and SizeOfRawData < Aligned(VirtualSize, SectionAlignment), but only 67 had extra bytes that weren't all zeroes. Expanding this search to include data sections as well, there were ~2,300 where the extra data wasn't all zeroes. By far, the biggest culprit was the rsrc section.
I'd be in favor of having Ghidra load as many bytes as the Windows loader does, as @0x6d696368 suggested. It will take more research to identify the exact logic that it uses, though.
 recvfrom
on 9 Apr 2019
recvfrom
on 9 Apr 2019
I looked further into this and here is the bug: https://github.com/NationalSecurityAgency/ghidra/blob/49c2010b63b56c8f20845f3970fedd95d003b1e9/Ghidra/Features/Base/src/main/java/ghidra/app/util/opinion/PeLoader.java#L680
https://github.com/NationalSecurityAgency/ghidra/blob/49c2010b63b56c8f20845f3970fedd95d003b1e9/Ghidra/Features/Base/src/main/java/ghidra/app/util/opinion/PeLoader.java#L681
It does not do the required alignment as per https://docs.microsoft.com/en-us/windows/desktop/debug/pe-format
What needs to happen:
SectionAlignment(inIMAGE_OPTIONAL_HEADER32):
The alignment (in bytes) of sections when they are loaded into memory. It must be greater than or equal to FileAlignment. The default is the page size for the architecture.
FileAlignment(inIMAGE_OPTIONAL_HEADER32):
The alignment factor (in bytes) that is used to align the raw data of sections in the image file. The value should be a power of 2 between 512 and 64 K, inclusive. The default is 512. If the SectionAlignment is less than the architecture's page size, then FileAlignment must match SectionAlignment.
- VirtualSize:
The total size of the section when loaded into memory. If this value is greater than SizeOfRawData, the section is zero-padded. This field is valid only for executable images and should be set to zero for object files.
- SizeOfRawData
The size of the section (for object files) or the size of the initialized data on disk (for image files). For executable images, this must be a multiple of FileAlignment from the optional header. If this is less than VirtualSize, the remainder of the section is zero-filled. Because the SizeOfRawData field is rounded but the VirtualSize field is not, it is possible for SizeOfRawData to be greater than VirtualSize as well. When a section contains only uninitialized data, this field should be zero.
The code at
https://github.com/NationalSecurityAgency/ghidra/blob/49c2010b63b56c8f20845f3970fedd95d003b1e9/Ghidra/Features/Base/src/main/java/ghidra/app/util/opinion/PeLoader.java#L680
could be changed to:
int rawDataSize = ( (sections[i].getSizeOfRawData() + fileAlignment - 1) / fileAlignment) * fileAlignment)
And the code at
https://github.com/NationalSecurityAgency/ghidra/blob/49c2010b63b56c8f20845f3970fedd95d003b1e9/Ghidra/Features/Base/src/main/java/ghidra/app/util/opinion/PeLoader.java#L681
could be changed to:
int virtualSize = ( (sections[i].getVirtualSize() + sectionAlignment - 1) / sectionAlignment) * sectionAlignment)
I think that would fix the problem.
@ryanmkurtz can you implement the above fix? If not I can try to setup a build environment this weekend and implement it.
0x6d696368
on 9 Apr 2019
Since SizeOfRawData is used to know how many bytes exist in the section on disk, I can't imagine we'd want to increase this value and then read in more bytes than the PE says that that section contains, in the case where it's not already aligned to FileAlignment. We should see what the Windows loader does in this case.
For one binary in my test set, the SectionAlignment is zero, which would trigger a divide-by-zero error in this alignment code. We should guard against hitting that case, and also see what the Windows loader does with that (maybe it uses the architecture page size instead, for instance).
recvfrom
on 9 Apr 2019
OK, so @0x6d696368's analysis is right on the money. I either overlooked this when I was doing our malware PE triage or someone yanked the code. Note that in _FileHeader.processSections_, lines 313-315, we're doing the right thing, i.e. modifying _sizeOfRawData_ using _PortableExecutable.computeAlignment_ to permanently modify the value based on _fileAlignment_. We don't have the requisite fix for _virtualSize_ however, namely using _sectionAlignment_ to modify its value. Probably, _processSections_ is the wrong place to do this. Note the extra logic in _PeLoader.getVirtualSize_. I think the alignment needs to be done after all the other logic there. Also, a little sketchy having this logic done (potentially) over and over in a getter method. I know, it's only called by _PeLoader.processMemoryBlocks_ and is a private method, but....
I would recommend maybe renaming _getVirtualSize_, adding the logic to re-align based on _sectionAlignment_, and calling _SectionHeader.setVirtualSize_ to modify the value permanently a la the code in _processSections_. Also, per @recvfrom's comment, we need a zero check on alignment in _PortableExecutable.computeAlignment._
I suppose it would also make sense to create some JUnits to check this stuff out. When I originally started fuzzing these files, I relied heavily on Ange Albertini's (aka corkami) PE documentation. He has numerous files exhibiting aberrant PE behavior, which would make for good test cases. Note though, some of them are likely to trip AV sensors.
 d-millar
on 9 Apr 2019
d-millar
on 9 Apr 2019
Since SizeOfRawData is used to know how many bytes exist in the section on disk, I can't imagine we'd want to increase this value
I guess it depends. That's why it would be nice to have a manual override. This would make my workaround of import as RAW, then modify header, then "Extract and Import ..." obsolete. And would also allow for fixing corrupted PE headers.
For one binary in my test set, the SectionAlignment is zero, which would trigger a divide-by-zero error in this alignment code. We should guard against hitting that case, and also see what the Windows loader does with that (maybe it uses the architecture page size instead, for instance).
Yes. That's bad.
Anyone know any Windows loader research that already answers all the questions of how Windows handles PE headers that are out of spec?
I suppose it would also make sense to create some JUnits to check this stuff out. When I originally started fuzzing these files, I relied heavily on Ange Albertini's (aka corkami) PE documentation. He has numerous files exhibiting aberrant PE behavior, which would make for good test cases. Note though, some of them are likely to trip AV sensors.
+1 for unit tests. Radare2 has some good regression tests.
0x6d696368
on 9 Apr 2019
@d-millar Thanks for the hints into the code.
I prepared PR #418
It aligns virtualSize in processSections. This is analogous to the alignment of sizeOfRawData.
I then truncate virtualSize to the maximum of virtualSize or sizeOfRawData so the analysis doesn't end up with lots of uninitialized memory areas. While this truncation isn't 1:1 what the Windows PE loader does, it doesn't lose any data. The only thing that could happen is that data references to these uninitialized memory areas can not be resolved.
We can debate whether to remove the truncation or not.
Regarding doing exactly what the Windows PE loader does this is it now. Ghidra however loads a lot of binaries that Windows simply rejects as "invalid PE files", e.g. I also fixed the div by 0 in the PortableExecutable.computeAlignment (treating it as no alignment at all), which means that Ghidra loads those PEs as well. Windows simply won't recognize them as valid so we can't check how Windows would load them.
Anyway, anyone any hints how to make a .jar with only the changes to place into Ghidra/patch/? So I can give this fix to people that can't compile from source without having to send the full base.jar.
0x6d696368
on 12 Apr 2019
Related issues
 rrivera1849
·
3Comments
rrivera1849
·
3Comments
 loudinthecloud
·
3Comments
loudinthecloud
·
3Comments
 Merculous
·
3Comments
Merculous
·
3Comments
 huettenhain
·
3Comments
huettenhain
·
3Comments
 awsaba
·
3Comments
awsaba
·
3Comments
Most helpful comment
We'll have to discuss how to best handle this generically. I'll leave this open as an enhancement request.