Gensim: Reading text model trained by word2vec and ValueError: invalid vector on line ...
I get this error when I want to load my word2vec models using the binary=False text models:
raise ValueError("invalid vector on line %s (is this really the text format?)" % (line_no))
ValueError: invalid vector on line 78289 (is this really the text format?)
I tried to train different models but I get this error with different lines in all models. My model is text and the line is a vector of one of my vocab words. Any reason causing this error?
 nick-magnini
nick-magnini
All 36 comments
That error says that the number of vector elements in your line 78289 doesn't match the number of elements declared in the header (=first line of the file).
Can you check what that line 78289 (counting from zero) actually contains?
Should be easy to verify.
 piskvorky
on 8 Jul 2015
piskvorky
on 8 Jul 2015
Also, what gensim version is this?
piskvorky
on 8 Jul 2015
I fixed the problem. I updated to the new version and now I can't read the model anymore.
Traceback (most recent call last):
File "
File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/gensim/models/word2vec.py", line 928, in load_word2vec_format
raise ValueError("invalid vector on line %s (is this really the text format?)" % (line_no))
ValueError: invalid vector on line 0 (is this really the text format?)
I use the same model in different computer where I have a non-updated version, I can read the model.
nick-magnini
on 9 Jul 2015
Can you share an example of the line giving the error? Do any of your word-tokens have whitespace inside them?
 gojomo
on 9 Jul 2015
gojomo
on 9 Jul 2015
I can load and use the model in the version 0.10.4 but it doesn't work in the most recent 0.12.0 version.
I get this error
model = Word2Vec.load_word2vec_format('model.txt' , binary=False)
Traceback (most recent call last):
File "", line 1, in
File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/gensim/models/word2vec.py", line 928, in load_word2vec_format
raise ValueError("invalid vector on line %s (is this really the text format?)" % (line_no))
ValueError: invalid vector on line 0 (is this really the text format?)
first line of model.txt: 640803 400
Other lines are correct since I loaded it in an older version.
nick-magnini
on 9 Jul 2015
Can you share what the line itself looks like? (Or is this a model.txt publicly available?)
gojomo
on 9 Jul 2015
No. It is not publicly available. It was trained on Wikipedia.
This is the first line/vector (line 0 is "640803 400"):
0.001001 0.001105 -0.000958 -0.000820 0.000342 0.000755 0.000235 0.000053 -0.000901 0.000555 -0.001089 0.000312 -0.000188 -0.000239 -0.000829 -0.000471 0.000645 0.000756 0.000742 0.000399 0.000386 -0.000951 -0.001024 0.001242 0.000950 0.000773 -0.000151 0.001004 -0.000124 0.000184 -0.000037 -0.000746 0.000328 -0.000334 -0.000956 0.001189 0.001095 -0.000274 -0.000057 0.000127 -0.000909 -0.001002 0.001139 0.000016 -0.000646 -0.000761 -0.000769 0.000424 0.000050 0.000333 -0.001053 -0.000952 -0.000033 0.000286 0.000637 -0.000793 0.001020 0.000232 0.000280 -0.000152 0.000747 -0.000572 -0.000524 0.000540 -0.000188 0.000258 0.000451 -0.001022 -0.000496 0.000728 0.001058 0.000983 -0.000762 -0.000527 -0.000227 0.000500 -0.000947 0.000749 0.000697 -0.000400 -0.000388 -0.000560 0.001057 0.000978 -0.000295 0.001054 0.001205 0.000454 0.001246 -0.000778 -0.000383 -0.000527 -0.000727 0.000704 0.000395 0.000106 -0.000548 0.000381 0.000765 0.000048 0.000570 -0.001238 0.001079 0.000120 -0.000458 -0.000521 -0.000187 -0.000734 -0.001092 -0.000709 0.001069 -0.000442 -0.000670 0.000579 -0.000426 0.001189 -0.000401 -0.001147 0.000679 -0.000019 -0.000872 0.000244 0.000360 -0.000120 0.000456 -0.000989 0.000220 0.000454 -0.000752 0.000036 -0.000015 -0.000600 -0.000708 -0.001173 0.000006 0.000038 0.000002 -0.000983 -0.001240 -0.001187 -0.001081 -0.000137 0.000348 0.000296 -0.000796 0.001250 -0.000503 -0.000318 -0.000351 0.001183 -0.000941 0.000290 -0.000334 0.000797 0.000010 0.001067 -0.000705 -0.000651 -0.001048 -0.000917 -0.000800 -0.000779 0.000611 -0.000467 0.000670 0.000923 0.000339 0.000738 0.000619 0.000585 -0.000888 -0.000858 -0.000914 -0.000033 0.001033 -0.000684 -0.000765 -0.001049 0.000826 -0.001045 -0.000145 0.000545 -0.001155 -0.001120 0.000361 0.000881 0.001066 0.000536 0.000791 -0.000782 -0.000910 0.000994 -0.000691 0.000438 0.000144 0.000448 -0.000296 0.000050 -0.000422 -0.000282 -0.001108 -0.000815 0.000871 0.000251 -0.000591 -0.000398 0.000624 -0.000883 -0.000578 0.001184 0.001062 -0.000990 0.000218 -0.000562 0.000038 0.000752 0.001212 0.000497 0.001028 0.000787 -0.000058 0.001119 0.000634 0.001185 -0.000426 0.001187 0.001082 -0.000357 -0.001105 0.001208 0.000224 -0.000520 -0.000179 -0.000184 -0.000963 -0.000358 -0.000111 -0.001232 -0.000879 -0.000301 -0.000235 0.000448 0.000204 -0.000154 0.000737 0.000362 0.000137 0.000904 -0.000281 -0.000357 -0.000103 -0.000682 -0.000750 0.000051 0.001085 -0.000342 -0.000005 -0.001034 0.000927 -0.000380 0.000742 -0.000602 -0.000224 0.000024 0.000906 -0.000022 0.001108 -0.000186 0.000525 -0.000034 -0.000975 0.001063 0.000264 -0.000757 0.000752 -0.001036 -0.001088 0.000817 -0.000858 -0.000662 0.000882 0.000821 0.000171 0.001131 0.001214 0.001014 0.000441 -0.001088 0.000572 -0.001223 -0.000322 0.000378 0.000245 -0.000381 0.000734 -0.001152 -0.000353 -0.000328 -0.000414 0.000768 -0.001183 0.000695 0.000334 0.000707 0.000919 0.000069 0.000206 -0.001138 -0.000257 0.000803 -0.000447 0.001053 -0.000298 -0.000969 -0.000648 0.001225 0.000835 -0.000992 0.001204 -0.001052 -0.001194 0.000619 -0.000164 -0.000583 -0.000095 -0.000629 0.000599 0.000954 0.001045 -0.001103 -0.000530 0.000002 -0.000234 0.000955 0.000550 0.001133 -0.000769 0.000427 0.001067 -0.000458 0.000730 0.000321 -0.001129 0.001050 0.001177 -0.000729 -0.000061 -0.000400 0.000611 -0.000966 0.000873 -0.000236 -0.000304 -0.000508 -0.001100 -0.000762 -0.000280 0.001154 -0.000630 -0.001159 0.000099 0.000153 0.000760 0.000018 0.000871 0.000746 -0.000327 -0.000159 0.000199 0.000316 0.000834 0.001004 -0.000626 -0.000630 -0.000405 -0.000673 0.000309 -0.000957 -0.000567 -0.001243 0.000544 0.001091 -0.000551 -0.001138 0.000742 0.000397 -0.000630 -0.000160 -0.000308 -0.000031 -0.000453 0.000009 -0.000691 0.000940 0.000957 0.000815 -0.000368 0.000068 0.000201 -0.000671
nick-magnini
on 9 Jul 2015
Looks fine to me.
Do you get the error consistently at the same place? I'm thinking maybe there's some disk/memory corruption on your machine?
Without more data, I'm not sure how else to debug this.
piskvorky
on 9 Jul 2015
Yes, I only see that error as possible if the corresponding line doesn't have exactly 401 tokens – the word and 400 dimensions. Your example line does. Is the data coming from someplace unlike a plain local volume – custom compression, remote/mesh storage, etc.? Maybe there's glitching when being read by the python process... but not when you then manually view the file later.
gojomo
on 9 Jul 2015
Actually, I can reproduce. The vector lines in a fresh word2vec.c text output file actually end in ' \n' (space-newline)... so the change in ad12ec9 now leaves one extra zero-length token at the end, triggering this error.
A .strip() of the line, before .split(' '), seems to fix.
gojomo
on 9 Jul 2015
Aha. Yes, let's rstrip (not strip) the line, that should be safe. I'll commit that.
@gojomo Let me know when you've fixed the other word2vec bugs, so we can make a new bugfix release.
Thanks all!
piskvorky
on 9 Jul 2015
For me, this is caused by setting binary=False. I'm loading Google News model, and setting binary to True solves the problem.
 lenhhoxung86
on 30 Nov 2017
lenhhoxung86
on 30 Nov 2017
I caused this error, when a whitespace is the vocabulary. the w2v is 200-dim.
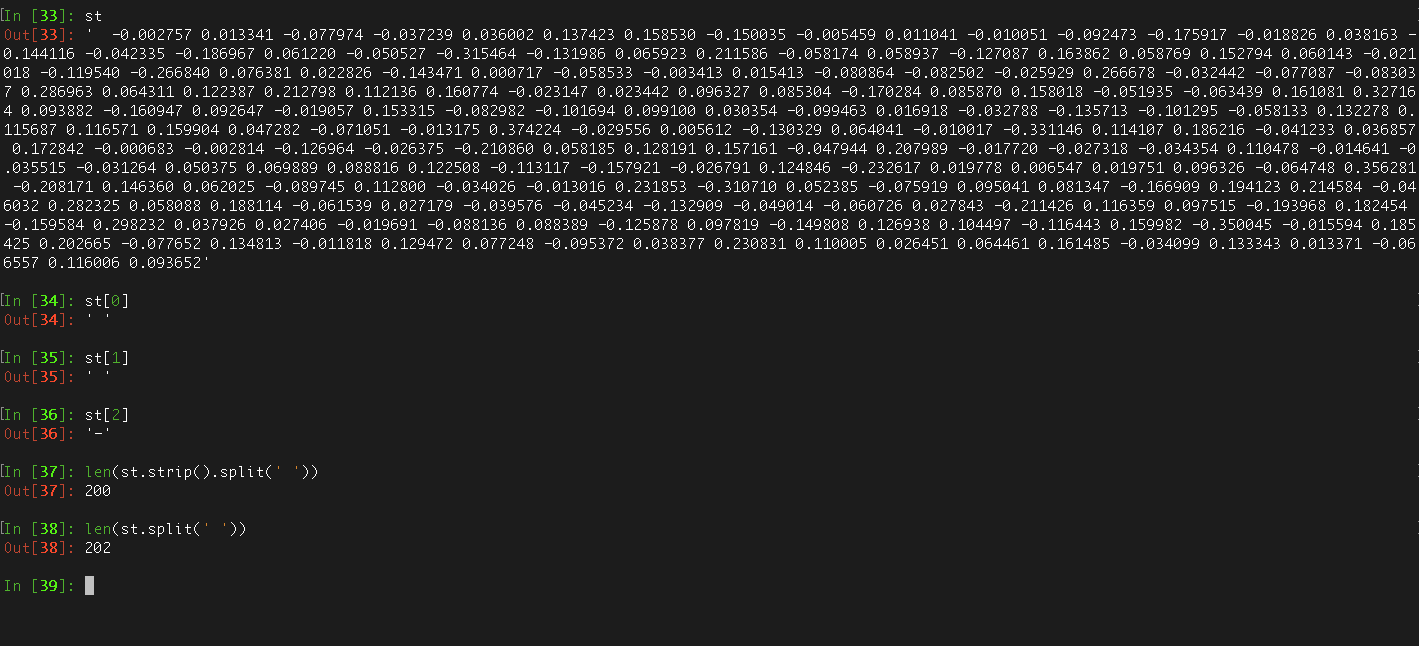
 stanpcf
on 1 Apr 2018
stanpcf
on 1 Apr 2018
@stanpcf please share your file
 menshikh-iv
on 1 Apr 2018
menshikh-iv
on 1 Apr 2018
@menshikh-iv I share the file in url .
stanpcf
on 3 Apr 2018
@stanpcf your file is broken
Line №9 (space instead of the token)
-0.065585 0.126010 0.056223 0.069626 -0.029134 0.067336 -0.204316 0.139422 -0.227337 0.198464 -0.119860 -0.169836 -0.028394 0.033589 0.113353 0.029154 0.063327 0.006931 0.027161 0.231387 -0.157665 0.019795 -0.216095 0.187386 -0.094718 -0.071525 0.163371 -0.157194 0.101622 0.034253 0.190488 -0.240157 -0.150281 0.112246 -0.187533 -0.095846 -0.005887 -0.048785 -0.168980 0.102162 0.107598 0.199509 0.205302 0.419411 0.005891 -0.105669 -0.090414 -0.005586 0.060165 -0.067295 -0.024423 -0.099194 -0.083894 -0.074042 0.104642 -0.060494 -0.110745 0.067888 -0.239107 0.133493 0.021400 -0.115407 -0.046922 -0.003634 0.147193 -0.008175 0.077847 0.022766 -0.003709 -0.099734 0.019586 0.118581 -0.037558 -0.147223 0.122130 -0.188494 -0.124651 0.056214 0.037080 0.104489 0.082679 0.104876 0.001397 0.120968 -0.078683 -0.165040 -0.011619 -0.012714 -0.055654 0.161629 -0.024803 0.078170 0.038378 0.267262 -0.095058 0.161170 -0.338052 0.067251 0.271388 0.216779 -0.127160 -0.052749 -0.092775 -0.023545 -0.127599 0.085860 -0.024313 -0.121204 0.073280 -0.103461 -0.153685 0.007918 0.005736 -0.113986 -0.283111 -0.013932 -0.129862 0.221664 0.245677 0.087173 0.104955 -0.051436 0.004821 -0.077722 0.291326 -0.166302 0.163637 -0.072505 -0.002202 0.161124 -0.251949 -0.119065 0.041845 -0.068551 0.039457 -0.053260 0.006834 0.266179 -0.097994 0.234098 -0.079942 0.078993 0.083595 0.069216 -0.106237 -0.097374 0.110697 0.142602 -0.035658 -0.020377 -0.046010 0.075475 0.224820 0.086804 0.013124 0.043212 -0.013541 -0.168338 -0.049675 0.027880 0.085575 -0.087013 0.078196 0.067902 0.264146 0.162130 -0.215149 -0.054623 -0.206150 0.204449 -0.249026 -0.027346 -0.194792 -0.019196 0.074567 -0.219620 0.022478 0.019117 0.027114 0.045352 -0.015983 0.094397 0.134142 -0.090520 -0.103326 -0.098753 -0.110604 0.114199 -0.183857 0.234064 -0.022948 -0.148547 -0.235645 -0.054405 -0.008171 0.130173 -0.045100 -0.063907 0.143528 0.043496
if you'll remove this line from your file (and don't forget to chage 132805 -> 132804 in header), all will work as expected.
menshikh-iv
on 3 Apr 2018
@stanpcf how did you generate this file?
piskvorky
on 3 Apr 2018
@menshikh-iv yes. When I find this problem. I removed this line and changed the vocabulary. all work fine. @piskvorky I have some chinese document. I cut it with jieba. and trained with gensim. this problem will not be caused if I clean data more careful. but I think whitespace may be useful in some case
stanpcf
on 4 Apr 2018
So the file was produced by gensim? That's not good.
I'd consider that a bug if gensim produces a file that it cannot read back itself.
piskvorky
on 4 Apr 2018
Whitespace is legal in the tokens for which vectors are learned - but causes problems if & only if using the original word2vec.c storage format. (I believe both its 'text' & 'binary' options have the problem, as both use a hard-coded ' ' to delimit end-of-token. Of course gensim's native pickle-based storage has no problems with token whitespace.) So some possible policies could be:
- loudly warn (but don't fail) at some earlier point if the vocabulary includes tokens-with-spaces, with specific text mentioning that such a choice is atypical and will prevent some save-formats from working
- warn (but don't necessarily fail) when writing a token-with-space via the
save_word2vec_format()path: attentive users will see the error, and still have a file-on-disk that can be hand-patched (as opposed to potentially losing all trained state to an error that cancels the writing) - hard-fail when about-to-write a token-with-space via
save_word2vec_format()– forcing the problem to be recognized & dealt with as soon as it occurs, but potentially losing trained work - skip-with-warning any tokens-with-spaces during
save_word2vec_format(), so that the format on disk contains all legal tokens (under the old format), and can be read into older tools, but some data may be inadvertently lost (if the user had a legitimate reason for whitespace-tokens). - try to 'read what was intended' in
load_word2vec_format(), via some heuristics for distinguishing internal whitespaces versus the end-of-token whitespace. This seems roughly possible for 'text' word2vec.c files – just take the last N space-delimited fields of a line as dimensions, and if there's more than 1 remaining at the front,' '.join()them to recover the original token. But it may not be straightforward in 'binary' word2vec.c files, as they mix space-delimiter-at-end fields with fixed-width binary-float fields, and those binary field ranges might contain space/newline/UTF8-looking values. - devise our own backward-compatible extension to the format that resolves the difficulties above for 'read what was intended' in the word2vec.c 'binary' format
If anything, I'd lean towards implementing the 1st 2 bullets - warnings without explicit failures – so that at least attentive users will get an advance hint something is amiss, or clues in their logs if they discover problems later. Everything else is a lot of work for rare, most-likely-user-error use-cases.
gojomo
on 4 Apr 2018
-1 on the first option, because like you say, there's nothing wrong with having whitespace-containing keys per se.
The failure should happen when trying to serialize to this specific format that cannot handle whitespace. And I'm more in favour of failing hard, with an explicit (and concrete, including the offending key) error.
Ignoring the offending keys with a clear warning/error, or hacking some guessing logic into the loading process sound also OK but more work (and feels less pythonic).
piskvorky
on 4 Apr 2018
I am using gensim word2vec to train into 20Newspaper dataset. After I train the model I use
model.wv.save_word2vec_format('models/model200.bin')
to save the model.
Right after I use
model_loaded = KeyedVectors.load_word2vec_format('models/model200.bin', binary=True).
While loading it I get in the log lines like this:
2018-07-02 12:35:21,781 : WARNING : duplicate word '7' in models/model200.bin, ignoring all but first
When I try to output the words of model_loaded, I get numbers, which means that the file is broken. Is there any problem with save_word2vec_format ?
 joanPlepi
on 2 Jul 2018
joanPlepi
on 2 Jul 2018
@joanPlepi you saved vectors in text format, but load in binary, should be
model.wv.save_word2vec_format('models/model200') # for text format
model_loaded = KeyedVectors.load_word2vec_format('models/model200')
or
model.wv.save_word2vec_format('models/model200', binary=True) # for binary format
model_loaded = KeyedVectors.load_word2vec_format('models/model200', binary=True)
@menshikh-iv I see. I thought that when I save the vectors it gets the appropriate format from the ending part (.bin or .txt).
Thank you !
joanPlepi
on 2 Jul 2018
I ran into this error and the fix by @menshikh-iv is not apparently the problem.
- The file is generated using:
model.wv.save_word2vec_format(fname=self.path) - The file is read using:
gensim.models.KeyedVectors.load_word2vec_format(self.path)
The error is:
Traceback (most recent call last):
File "/home/gustavomaia/.pycharm_helpers/pydev/_pydevd_bundle/pydevd_exec2.py", line 3, in Exec
exec(exp, global_vars, local_vars)
File "<input>", line 1, in <module>
File "/home/gustavomaia/miniconda3/envs/tcc/lib/python3.7/site-packages/gensim/models/keyedvectors.py", line 1498, in load_word2vec_format
limit=limit, datatype=datatype)
File "/home/gustavomaia/miniconda3/envs/tcc/lib/python3.7/site-packages/gensim/models/utils_any2vec.py", line 394, in _load_word2vec_format
raise ValueError("invalid vector on line %s (is this really the text format?)" % line_no)
ValueError: invalid vector on line 165 (is this really the text format?)
The header of the file is 353 100 and the lines 164, 165, 166:
antigo 0.01348348 -0.4641184 0.22886965 0.8362618 -0.30862916 0.43850273 0.01749821 0.6295799 0.0318072 1.0916225 0.17916651 1.102303 0.5117879 0.2714291 -0.070564084 0.44100133 0.47872567 -0.5434807 0.66890997 0.56793445 -0.80572385 -0.91804 -0.11759109 -0.1830387 -0.95603865 -0.30278385 -0.14139569 0.75650406 -0.018753564 -0.024388028 0.23747966 -0.544858 0.2556707 -0.5382204 0.25092375 0.28005373 -0.042723294 -0.41136006 -0.9573887 0.26466987 -0.24874616 -0.22010356 -0.4763563 0.42488757 -0.51409906 -0.52479434 0.117916495 -0.15412913 2.1199431 0.16303362 0.54662234 -0.25685343 0.5936994 0.29796824 -0.34390995 0.37316915 0.6477806 -0.52043146 -0.41748413 -0.4803786 0.33568484 -0.07540414 -0.01754003 -0.23958975 -0.18333383 -0.14417322 0.11307258 -0.28354236 0.32739615 -0.23039232 0.77706605 -0.6252185 0.73596185 -0.024725504 -0.4328708 0.5973603 -0.15084812 -0.17772163 -0.30530775 -0.06802995 -1.2411988 0.65623236 0.030302571 -0.47173184 0.31600043 0.08743988 -0.54037863 -0.30343318 0.7124531 0.46138057 0.09520146 0.6518586 -1.1302443 0.17883174 -0.78683645 0.29796362 -0.15632519 0.472022 -0.112577215 -0.16934174
esv 0.7177098 -0.3629863 -0.4227833 1.0095408 -0.2565117 0.16852637 -0.056725685 0.6018817 -0.24841377 0.8194262 0.5929137 0.33657566 -0.83139336 0.283198 0.29824722 -0.5436309 0.92458695 0.17291608 0.4106753 0.01107894 0.5743016 -0.93352175 -0.31139743 -0.5707805 -0.89087605 0.58928376 -0.24500206 -0.4527542 0.20173715 -0.3018211 -0.23314981 -0.31544703 -0.004237361 -0.09768513 -0.5039696 0.2940789 -0.20907314 -0.76492167 -0.5260634 -0.058505118 -0.23359443 -1.3380356 -0.48547217 0.8466003 -0.85924995 -0.4476155 -0.58273906 0.14948422 1.2815168 0.69919896 0.80025995 0.16497031 -0.5316537 0.11386405 -0.66610223 0.030601226 0.35326228 -0.20008172 0.18438235 0.11270134 -0.6758767 0.3116303 1.3197092 0.23498248 0.6474894 -0.29217106 0.60515904 0.11937684 0.44346502 -0.2236312 0.22510624 -0.5273623 0.6594942 0.28919166 -0.008753567 0.12139412 0.2632397 0.5520853 -0.26908386 -0.0488105 -0.5295915 -0.42312625 -0.29227513 -0.4295604 0.12477013 1.1610906 -0.074790135 0.023154194 -0.11022077 0.31097272 0.21296728 0.5654414 -0.88996285 0.103592925 -0.40504542 0.07089505 -0.6250654 0.046894133 0.22322942 -0.6241815
sve 0.089781865 -0.22261423 0.21754226 0.7629686 -0.5697394 -0.045781735 0.40838635 0.64682615 -0.4202031 0.54367286 0.3433876 0.4844083 -0.17961842 0.032287337 -0.04838498 -0.41975883 0.03587936 0.033681493 0.62033147 0.89497226 -0.09018101 -0.11295679 0.28058097 -0.27651915 -0.19490556 -0.088159576 -0.0142130125 0.12853011 0.25144014 0.33655107 0.33799964 -0.026224693 0.29842046 -0.3733831 0.062490016 0.34240678 0.21260348 -0.36670536 -0.4149401 0.0421675 0.26056203 -0.40068623 0.024282988 0.18496238 -0.45750362 -0.35819963 -0.07716395 -0.6188389 0.8916695 0.55129504 0.38416567 0.25008366 0.16675721 -0.10127659 -0.29227433 0.27525026 0.41765255 -0.41784602 -0.29274833 -0.13550636 0.3066468 0.08882454 0.34171635 0.123645775 0.25522473 -0.33589864 0.18358077 -0.16076721 0.33960474 -0.22304851 0.20803854 0.13039736 0.61511755 -0.10132083 -0.018072244 0.17063995 -0.08298167 0.08710574 -0.3034286 0.39950213 -0.74815595 -0.011003374 -0.017410163 0.11461042 0.2354214 -0.26700085 0.04761678 -0.49744007 0.48480397 0.12367638 0.30109996 0.29405195 -0.57142043 0.20731927 -0.60225403 0.41321626 -0.16425082 -0.10937819 0.39870414 -0.13597246
Any thoughts?
 vmgustavo
on 20 Aug 2019
vmgustavo
on 20 Aug 2019
@vmgustavo Looks fine to me. Can you share the actual file?
piskvorky
on 20 Aug 2019
As that error is thrown if the code doesn't see the right number of space-delimited tokens (though your excerpt looks fine), it could be interesting to edit the error-throwing code to show more info – actual count seen, the full raw line - for more hints.
gojomo
on 21 Aug 2019
@piskvorky the full file: my_model.txt
@gojomo how to edit the error-throwing code to show more info?
vmgustavo
on 21 Aug 2019
The error is in lines 166 and 342 (counting from 0). Both contain token with whitespace, which is exactly the problem described above. 166 = negativo v4, 342 = negativo v6.
piskvorky
on 21 Aug 2019
Maybe there could be a warning before writing the model to a file. Because the error was when trying to read an already printed file I thought the problem was with the reading not with way back at the tokens used to train the model.
vmgustavo
on 21 Aug 2019
Yes, that's exactly the suggestion above https://github.com/RaRe-Technologies/gensim/issues/388#issuecomment-378691876. Gensim should fail to write files it cannot read back.
Btw Gensim's native save()/load() format is much preferable to this external word2vec text format. Use save/load to speed up I/O and avoid such issues.
piskvorky
on 21 Aug 2019
Note this happens because gensim can otherwise handle word-tokens with internal spaces, whereas the original word2vec.c tool, and its original format, cannot.
We could also make a backwards-compatible upgrade to gensim's use/understanding of the format, and consider the last vector_size fields per line as the vector, and any one-or-more earlier fields as a single word-token (possibly with internal whitespace). That'd only require a change in load_word2vec_format(). (I have an odd deja vu feeling that I may have made this suggestion before, but not sure where.) (See my earlier comment above for more discussion of this & similar ideas, including a note that this might be harder for binary word2vec-format files.)
gojomo
on 22 Aug 2019
Why can't you introduce delimiter param in both save and load _w2v_format()?
It would make so much sense.
 heisen273
on 26 May 2020
heisen273
on 26 May 2020
Because it wouldn't be "w2v format" then.
If you need more flexibility, use the standard "native" model.save() & load().
piskvorky
on 26 May 2020
Why can't you introduce
delimiterparam in both save and load _w2v_format()?
It would make so much sense.
That's not part of the format as originally defined by others & widely used by software in many languages – so adding it could create a bunch of expectations (& likely followup errors/questions) across many projects. Also, it's very rare, given usual practices, to need to have spaces inside tokens - using some other more-explicit joiner, like a '_', is far more common. (Many people who fumble into tokens-with-spaces should probably change their approach.)
For the occasional true need, saving the whole object is better in most ways. The plain word2vec-format is pretty limited & inefficient, losing any extra info with the vectors. Its main value is interoperability, which would be lost with an atypical variation of delimiters.
But finally, if you want/need a non-standard word2vec format, you could easily cut & paste the code with tiny changes to support that.
gojomo
on 26 May 2020
@gojomo yep, I ended up replacing them.
heisen273
on 26 May 2020
Related issues
menshikh-iv
·
3Comments
 bgokden
·
3Comments
bgokden
·
3Comments
 Jianqiang
·
3Comments
Jianqiang
·
3Comments
 franciscojavierarceo
·
3Comments
menshikh-iv
·
4Comments
franciscojavierarceo
·
3Comments
menshikh-iv
·
4Comments
Most helpful comment
Whitespace is legal in the tokens for which vectors are learned - but causes problems if & only if using the original word2vec.c storage format. (I believe both its 'text' & 'binary' options have the problem, as both use a hard-coded
' 'to delimit end-of-token. Of course gensim's native pickle-based storage has no problems with token whitespace.) So some possible policies could be:save_word2vec_format()path: attentive users will see the error, and still have a file-on-disk that can be hand-patched (as opposed to potentially losing all trained state to an error that cancels the writing)save_word2vec_format()– forcing the problem to be recognized & dealt with as soon as it occurs, but potentially losing trained worksave_word2vec_format(), so that the format on disk contains all legal tokens (under the old format), and can be read into older tools, but some data may be inadvertently lost (if the user had a legitimate reason for whitespace-tokens).load_word2vec_format(), via some heuristics for distinguishing internal whitespaces versus the end-of-token whitespace. This seems roughly possible for 'text' word2vec.c files – just take the last N space-delimited fields of a line as dimensions, and if there's more than 1 remaining at the front,' '.join()them to recover the original token. But it may not be straightforward in 'binary' word2vec.c files, as they mix space-delimiter-at-end fields with fixed-width binary-float fields, and those binary field ranges might contain space/newline/UTF8-looking values.If anything, I'd lean towards implementing the 1st 2 bullets - warnings without explicit failures – so that at least attentive users will get an advance hint something is amiss, or clues in their logs if they discover problems later. Everything else is a lot of work for rare, most-likely-user-error use-cases.