Gensim: LdaSeqModel not replicable at 5th or 6th decimal despite fixed Python hash seed and random.state
I've estimated both the LDA model and DTM on a dataset of 1173 texts (the LDA is used as input for DTM), and I get different results in the 4th, 5th and 6th decimal for the word probabilities when I run the DTM model on three different computers. In the code the Python hash seed is disabled (i.e., PYTHONHASHSEED=0), and the random.state is fixed as well. Moreover, all the packages of Anaconda are exactly the same on each of the three computers and all the version numbers are exactly the same and updated to the latest versions, so there really shouldn't be any difference.
The way the DTM model is estimated is:
ldaseq = ldaseqmodel.LdaSeqModel(corpus=CBcorpus_1997to2016_pruned, id2word=dictionary_pruned, time_slice=time_slice,
num_topics=3, lda_model=ldamodel, random_state=np.random.RandomState(10))
The current idea that Radim, Bhargav (who wrote the code for this model) and I have is that it might be due to floating point approximation, and that this accumulates due to the many iterations in the model. Could someone please take a look to see where the problem might be?
Thanks!
Myrthe van Dieijen
Description
TODO: change commented example
Steps/Code/Corpus to Reproduce
Expected Results
Actual Results
Versions
 myrthevandieijen
myrthevandieijen
All 14 comments
Hello, thanks for report @myrthevandieijen, can you please add more information
- What's OS, python versions
- What's gensim version
- The small piece of code for reproducing (define missing variables in your example)
 menshikh-iv
on 4 Oct 2018
menshikh-iv
on 4 Oct 2018
Thanks for your response @menshikh-iv. I've listed the additional information below.
OS:
The OS is Windows 10 on my computer, and on the on the other two computers where I ran the code the OS was Windows 10 and Windows 7.
Python version and Gensim version:
On all computers we use Python version 3.6.6, and Gensim version 3.5.0. All the other (conda and pip) packages we use are of exactly the same version.
Code:
# set PYTHONHASHSEED=0 when you run it
dictionary_pruned=corpora.Dictionary.load('dict_below1_above95_fhs')
CBcorpus_1997to2016_pruned = MmCorpus('CBcorpus_below1_above95_fhs')
num_topics = 3
scalar = 0.01
eta = np.ones((num_topics, len(dictionary_pruned))) * scalar
lda_3k_fhs = LdaModel(
corpus=CBcorpus_1997to2016_pruned, id2word=dictionary_pruned, num_topics=num_topics,
alpha=50/num_topics, eta=eta, iterations = 1000, update_every=0, passes=100,
distributed=False, random_state=np.random.RandomState(10)
)
lda_3k_fhs.save('lda_below1_above95_SG_3k_100passes_1000iter_fhs')
ldamodel = gensim.models.LdaModel.load('lda_below1_above95_SG_3k_100passes_1000iter_fhs')
time_slice = [45, 56, 65, 61, 56, 74, 69, 95, 79, 70, 72, 70, 49, 54, 45, 41, 49, 36, 45, 42]
ldaseq = ldaseqmodel.LdaSeqModel(
corpus=CBcorpus_1997to2016_pruned, id2word=dictionary_pruned, time_slice=time_slice,
num_topics=3, lda_model=ldamodel, random_state=np.random.RandomState(10)
)
ldaseq.save('ldaseq_below1_above95_SG_3k_100passes_1000iter_fhs')
ldaseq = gensim.models.ldaseqmodel.LdaSeqModel.load('DTM_Results/ldaseq_below1_above95_SG_3k_100passes_1000iter_fhs')
Don't think this will matter, but the dictionary and corpus were created in one notebook, the lda model in another, and the ldaseqmodel was estimated in a third notebook. I always load the same dictionary and corpus files. In all 3 notebooks I use PYTHONHASHSEED=0.
I hope you might be able to help out with this issue. The word probabilities of the ldaseq model differ at the 5th and 6th decimal, and sometimes also starting at the 4th. See attached picture
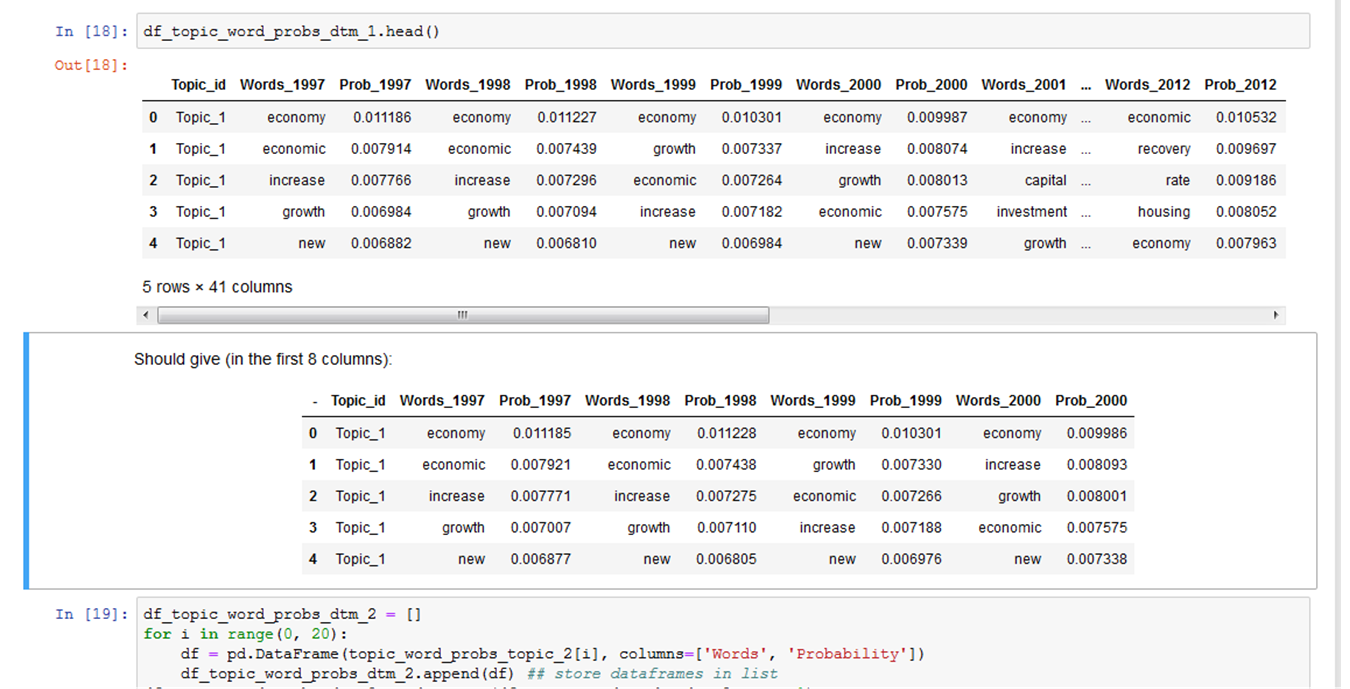
Thanks!
myrthevandieijen
on 4 Oct 2018
@myrthevandieijen thanks, can you please also
- add used corpus & dictionary files & both models (just attach here as file or link to any file-sharing service)
- extend code with one more piece - point to something that different (i.e. what's exactly different: inferred vector, internal matrix, something else?).
Don't misunderstand me, I just want to clarify all the details to increase a probability of resolving a current issue (for fix something, a person need to reproduce issue first).
menshikh-iv
on 4 Oct 2018
@menshikh-iv Thanks. The corpus and dictionary can be found via this link (will remove this later on):
https://drive.google.com/open?id=1RQI4hI07RGzLFdZu7Il6cOx7gqHnp2eO
After estimating the lda seq model and reloading it, the code continues as follows:
import pandas as pd
# evolution of the 1st topic
topic_word_probs_topic_1 = ldaseq.print_topic_times(topic=0, top_terms=len(dictionary_pruned))
# evolution of the 2nd topic
topic_word_probs_topic_2 = ldaseq.print_topic_times(topic=1, top_terms=len(dictionary_pruned))
# evolution of the 3rd topic
topic_word_probs_topic_3 = ldaseq.print_topic_times(topic=2, top_terms=len(dictionary_pruned))
df_topic_word_probs_dtm_1 = []
for i in range(0, 20):
df = pd.DataFrame(topic_word_probs_topic_1[i], columns=['Words', 'Probability'])
df_topic_word_probs_dtm_1.append(df)
# store dataframes in list
df_topic_word_probs_dtm_1 = pd.concat(df_topic_word_probs_dtm_1, axis=1)
# replace column names
df_topic_word_probs_dtm_1.columns = ['Words_1997', 'Prob_1997', 'Words_1998', 'Prob_1998', 'Words_1999', 'Prob_1999','Words_2000', 'Prob_2000',
'Words_2001', 'Prob_2001', 'Words_2002', 'Prob_2002', 'Words_2003', 'Prob_2003', 'Words_2004', 'Prob_2004',
'Words_2005', 'Prob_2005', 'Words_2006', 'Prob_2006', 'Words_2007', 'Prob_2007', 'Words_2008', 'Prob_2008',
'Words_2009', 'Prob_2009', 'Words_2010', 'Prob_2010', 'Words_2011', 'Prob_2011', 'Words_2012', 'Prob_2012',
'Words_2013', 'Prob_2013', 'Words_2014', 'Prob_2014', 'Words_2015', 'Prob_2015', 'Words_2016', 'Prob_2016']
# add column of topic number
df_topic_word_probs_dtm_1.insert(0, 'Topic_id', 'Topic_1')
df_topic_word_probs_dtm_1.head()
The dataframes is where I see the differences. I've copied the results I get on my computer in a markdown cell, and when I run the notebook on the two different computers I don't get the same results in the dataframe(s) after the third decimal. Moreover, the results on none of the three computers match, for all three the results are the same up until the third decimal, and then it becomes something different.
myrthevandieijen
on 4 Oct 2018
Thanks @myrthevandieijen
Data: drive-download-20181004T121809Z-001.zip
A bit reformatted first piece of code (training), ready to run (just be sure than you run it in same folder as data files
from gensim.corpora import MmCorpus, Dictionary
from gensim.models import LdaModel, LdaSeqModel
import numpy as np
dictionary_pruned=Dictionary.load('dict_below1_above95_fhs')
CBcorpus_1997to2016_pruned = MmCorpus('CBcorpus_below1_above95_fhs')
num_topics = 3
scalar = 0.01
eta = np.ones((num_topics, len(dictionary_pruned))) * scalar
lda_3k_fhs = LdaModel(
corpus=CBcorpus_1997to2016_pruned, id2word=dictionary_pruned, num_topics=num_topics,
alpha=50/num_topics, eta=eta, iterations=1000, update_every=0, passes=100,
distributed=False, random_state=np.random.RandomState(10)
)
lda_3k_fhs.save('lda_below1_above95_SG_3k_100passes_1000iter_fhs')
ldamodel = LdaModel.load('lda_below1_above95_SG_3k_100passes_1000iter_fhs')
time_slice = [45, 56, 65, 61, 56, 74, 69, 95, 79, 70, 72, 70, 49, 54, 45, 41, 49, 36, 45, 42]
ldaseq = LdaSeqModel(
corpus=CBcorpus_1997to2016_pruned, id2word=dictionary_pruned, time_slice=time_slice,
num_topics=3, lda_model=ldamodel, random_state=np.random.RandomState(10)
)
ldaseq.save('ldaseq_below1_above95_SG_3k_100passes_1000iter_fhs')
ldaseq = LdaSeqModel.load('DTM_Results/ldaseq_below1_above95_SG_3k_100passes_1000iter_fhs')
@menshikh-iv Thanks! Should this solve the problem? Why are the different folders the cause of the varying results? I'd like to understand where this issue is coming from, as it's been bugging me for months, unfortunately..
I'll run it all again, have to adjust the code first. As mentioned, I work with multiple notebooks, as there's a lot of extra code written around the code snippets I sent, to display the results of the LDA and LdaSeq model in an appealing way. Using one notebook would make the code too slow. Running the models again will take some time, as I have to test it on one of the other computers as well to see whether the results are now the same. I'll give you a heads up once it's done, so please don't close of this issue before we know it's replicable.
You are running it as well, right? Would be good to compare the results. Thanks for your help!
myrthevandieijen
on 4 Oct 2018
Should this solve the problem?
No, I'm just preparing all information/code/data for the person, who will take this issue in the future.
I'll run it all again, have to adjust the code first.
This code is fully equal to your, just formatted a bit + added missing imports, etc. Have no sense to rerun it again.
You are running it as well, right? Would be good to compare the results. Thanks for your help!
Yes, I ran, but this takes longer than I expect, I'm not sure than I'll wait until the end.
menshikh-iv
on 4 Oct 2018
@menshikh-iv ah that makes sense, I was already quite surprised. The model indeed takes a while to run. I'd really appreciate it if you could wait for it to run to investigate the problem further. I need the results to be replicable. Many (!) thanks in advance for all your help!
myrthevandieijen
on 4 Oct 2018
@myrthevandieijen thanks for your detailed report :+1:
menshikh-iv
on 4 Oct 2018
Hi @menshikh-iv, just checking in to see whether you might be a bit closer in solving this bug. Thanks!
myrthevandieijen
on 8 Oct 2018
Sorry @myrthevandieijen, I have no time for it now :disappointed:
menshikh-iv
on 9 Oct 2018
@menshikh-iv Sorry to hear that, but I understand that other things might take precedence. Do you have any idea when you are able to get to it? Sorry for pushing this so much, it's just that we've got an academic paper that uses this model and it's really important to know that we can use the results we get now. We now round to 3 decimals for the paper, if you can indicate that there's no reason to suspect that that should be a problem and that the issues starting at the 4th decimal will be fixed later on, that would be reassuring. Thanks for your understanding!
myrthevandieijen
on 9 Oct 2018
@myrthevandieijen
Do you have any idea when you are able to get to it?
No ideas, sorry (we have too many things with higher priority).
the issues starting at the 4th decimal will be fixed later on
I can't guarantee it (I hope then I'll dig this one someday, but it will definitely not happen soon).
menshikh-iv
on 9 Oct 2018
@menshikh-iv Thanks for your reply, we'll be patient in this. I'll occasionally check in with you on this but will leave it for now and just round to 3 decimals.
myrthevandieijen
on 9 Oct 2018
Related issues
 ahmedbhabbas
·
4Comments
ahmedbhabbas
·
4Comments
 shubhvachher
·
4Comments
shubhvachher
·
4Comments
 jeradf
·
4Comments
jeradf
·
4Comments
 volj1
·
4Comments
volj1
·
4Comments
 hhchen1105
·
4Comments
hhchen1105
·
4Comments