Expected behavior
The "Message queues" should be processed and at least the open tasks number should be close to 0.
Actual behavior
The "Message queues" are filling up, currently this are the Numbers:
Message queues: 8267 - 3628
The first number ist constantly increasing, the second is going up and down but not below 2000.
Steps to reproduce the problem
Maybe enable "direct relay" function (might be one reason for this to happen, function enabled yesterday).
Friendica version you encountered the problem
2018-05-dev
(I thought I did a pull before, but unfortunately I didn't, so this is the latest "git pull" output)
remote: Counting objects: 11, done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 11 (delta 6), reused 7 (delta 6), pack-reused 3
Unpacking objects: 100% (11/11), done.
From https://github.com/friendica/friendica
48f849205..7f0bd63b7 develop -> origin/develop
Updating 48f849205..7f0bd63b7
Fast-forward
Vagrantfile | 2 +-
{util => bin/dev}/friendica-to-smarty-tpl.py | 0
{util => bin/dev}/make_credits.py | 0
{util => bin/dev}/minifyjs.sh | 0
{util => bin/dev}/updatetpl.py | 0
{util => bin/dev}/vagrant_provision.sh | 2 +-
{util => bin/dev}/vagrant_vhost.sh | 0
7 files changed, 2 insertions(+), 2 deletions(-)
rename {util => bin/dev}/friendica-to-smarty-tpl.py (100%)
rename {util => bin/dev}/make_credits.py (100%)
rename {util => bin/dev}/minifyjs.sh (100%)
rename {util => bin/dev}/updatetpl.py (100%)
rename {util => bin/dev}/vagrant_provision.sh (98%)
rename {util => bin/dev}/vagrant_vhost.sh (100%)
Loading composer repositories with package information
Installing dependencies (including require-dev) from lock file
Nothing to install or update
Generating optimized autoload files
Already up to date.
Friendica source (git, zip)
git
PHP version
PHP Version => 7.2.4
SQL version
mysql Ver 15.1 Distrib 10.1.31-MariaDB, for Linux (x86_64) using readline 5.1
Edit
- The worker is running fine, there is almost no load on the system, ps aux returns 30 processes of the worker, I increased this from 20 in the hope to have the queue decreasing faster.
 utzer
utzer
All 67 comments
This PR should help: https://github.com/friendica/friendica/pull/4783
 annando
on 8 Apr 2018
annando
on 8 Apr 2018
This PR should help: #4783
With the second number too (the open tasks in the queue) and not the deferred ones?
The deferred (zurückgestellt) ones ist the first number.
utzer
on 8 Apr 2018
There is a worker task for every queue task.
annando
on 8 Apr 2018
There is a worker task for every queue task.
I assumed so, lets see the PR effect, I will do a pull asap.
utzer
on 8 Apr 2018
It is merged, you can pull.
 MrPetovan
on 8 Apr 2018
MrPetovan
on 8 Apr 2018
I merged it locally just 5 minutes because... well patience. :-D
Numbers are both decreasing now, I think I will give it one hours to be sure and will close the issue then.
Thanks @annando and @MrPetovan!
utzer
on 8 Apr 2018
@karbovskibg it is fixed, I will now close it, people should do a git pull if they use develop branch. @annando will probably improve this further if I got him right, but for now it seems OK.
New "Message queues - 8105 - 718" it was over 4500 when I did pull the commit, so 2h down by 4000 tasks, also I activated the "direct relay" again.
utzer
on 8 Apr 2018
OK I guess the direct relay is too much, I will disable it again, we are back at this numbers here:
Nachrichten-Warteschlangen 6647 - 6587
utzer
on 8 Apr 2018
@karbovskibg I thought I already replied to the question, sorry about the long time.
ben-utzer i see you in friendica globar directory what you want to comment is this issue is coming on the latest update ? so peoples should not update untill developer fix it
The Problem is already solved, the problem was only present for a short time in the develop branch. I guess further improvement of the relay function will happen in the future.
utzer
on 10 Apr 2018
Update: The last PRs should have helped in reducing the queue. There is a new setting that defines the time until a contact is archived.
annando
on 10 Apr 2018
Update: The last PRs should have helped in reducing the queue. There is a new setting that defines the time until a contact is archived.
Did you also change anything regarding the direct relay? I do not mind about having 4000 undeliverable posts in the queue as long as posts and messages are sent out fast and as long as new messages from contacts and relay are coming in fast.
The undeliverable messages queue improvement is nice to have, I will see this next days then.
utzer
on 10 Apr 2018
How can I check if the direct relay posts are causing that posts delivery to my contacts is delayed? I activated the function and see my posts to other people are taking 30+ minutes. The queue was about 700 items as per info in /admin.
utzer
on 11 Apr 2018
Activate the debug log then execute this command in the command line:
tail -f friendica.log | grep -a :Worker.php:688
You should see lines like [DEBUG]:Worker.php:688:tooMuchWorkers Load: 2.46/20 - processes: 4/85 - jpm: 5/137/92 (0:1, 30:3/34, 40:1/54, 50:0/1) - maximum: 14/20
Then do a public post and watch how the system reacts. Posts are executes with priority "20". Then you can watch how fast your workerqueue is processed.
annando
on 11 Apr 2018
With PR https://github.com/friendica/friendica/pull/4817 direct relais posts should be at the end of the delivery chain. And with some other PRs in past, we just drop direct relay posts, when the target isn't reachable.
annando
on 12 Apr 2018
My queue is filling up again with messages for a long dead profiles on dead server e.g.
And there i donÄt know if it is a misconfiguration or if the server is also dead
 hoergen
on 13 Apr 2018
hoergen
on 13 Apr 2018
It's happening again with these accounts.
http://indyfractal.com/u/analytica
http://hubzilla.eu/channel/michaelmeer
http://node.hfrc.de/channel/holger
There is even a message to myself???
hoergen
on 17 Apr 2018
But besides this, the queue behaviour is now back to normal, I hope?
annando
on 17 Apr 2018
Define normal ;) If you ignore all anomalies that are there = everything is completely normal ;)
hoergen
on 17 Apr 2018
Since last week when i deleted my queue by hand the queue is constantly growing again. Acutally 261. Every day there are 2-10 new "queued" messages.
Meanwhile it is so fucked up, that the queue wants to deliver messages from myself to my friendica instance, since several days (2018-04-12)
There are again all those dead acconts and dead servers again. Why this is happening again and again and again. I need help :(
PS: I should add that I don't miss any messages or got complaints about it.
hoergen
on 22 Apr 2018
Like I said: You could archive the contacts. This is more useful than deleting the queue.
annando
on 23 Apr 2018
Yes I understood that, but how can I archive contacts, that I don't have any more? should I archive actuall contacts? And how should I archive my own admin account without being locked out?
PS: To be clear: I I didn't have those contacts any more before I noticed this queue issue
hoergen
on 23 Apr 2018
Every queue item belongs to a contact. So when you are having a queue item for some receiver then the receiver's contact does exist. Let me work out something.
annando
on 23 Apr 2018
I looked in the database and the "next" field contains0001-01-01 00:00:00 and the retrial field "0" this looks wrong. Isn't it?
In some guids are "mailto:" addresses?
hoergen
on 23 Apr 2018
Check if http://indyfractal.com/u/analytica exists. As far as I see, this server doesn't exist.
hoergen
on 23 Apr 2018
I created a PR. With this you could call:
bin/console archivecontact http://indyfractal.com/u/analytica
Then there shouldn't be any queue entry with this contact any more.
annando
on 23 Apr 2018
Ok I will try. Thank you 🌻 And what do I do with all th other contacts, that exists and with my own admin accoun?
hoergen
on 23 Apr 2018
What network code does the line tell?
annando
on 23 Apr 2018
Not sure, what you mean with network code ?
You mean the network field? Mostly dspr, then dfrn and twit
hoergen
on 23 Apr 2018
Every line with "twit" means that a post to Twitter hadn't got through.
annando
on 23 Apr 2018
Every line with "twit" means that a post to Twitter hadn't got through.
I thought that already ;) And I think the same is with dispr and dfrn ;) Even the delivery of my own messages to my own instance ;)
hoergen
on 23 Apr 2018
Du you have posts with your own profile link with "dfrn" as network? This really shouldn't happen at all!
annando
on 23 Apr 2018
No, that are only twit with my account
hoergen
on 23 Apr 2018
Okay. Then the Twitter postings don't come through. Please check your Friendica log and check for content with "twitter.php" in it. There will be some Twitter error that prevents these posts from being posted.
annando
on 23 Apr 2018
These are only 2 Messages from 2 from menawhile 270 messages and they are there since2 days. Whereas the other 268 are. This is not really a problem of some Auth or something. This is an other problem. Believe me.
hoergen
on 23 Apr 2018
Okay. Your explanation sounded like 100 Twitter messages. Are you on the latest develop? Have you archived the dead account?
annando
on 23 Apr 2018
I archived this one account. But I cant archive myself or other accounts.
hoergen
on 23 Apr 2018
I'm confused. So just to clarify: How much queue entries do you have with your profile that don't have "twit" as network? What do they have as network?
annando
on 23 Apr 2018
There are only 2 entries with (twit) all others are dspr and dfrn.
At the moment there are 249 all over all entries.
The archived ones are gone :)
hoergen
on 23 Apr 2018
And the 247 that are left are all pointing to contacts on different servers?
annando
on 23 Apr 2018
Yes they are
hoergen
on 23 Apr 2018
I will add a check for hubzilla servers, so that we check whether the server is able to speak the Diaspora protocol.
annando
on 23 Apr 2018
Alle queue entries in the database are showing the same data in the field "next" and "retrail". Maybe that helps?
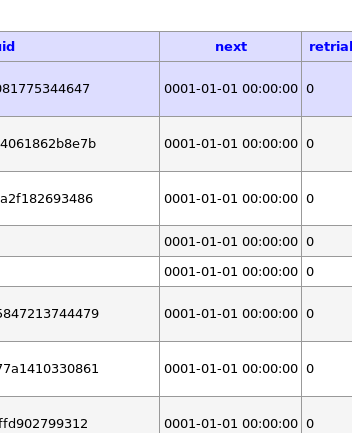
hoergen
on 23 Apr 2018
Today there are 261 messages in the queue (yesterday 241)
Again dead accounts and servers (i'll try to archive them)
http://emgee.longmusic.com/channel/marting
That worked.
Question: Can I archive all messages in the que without harming the state of the connection to this account? (unfollow etc)
If yes, you should rename the command archivecontact to archivemsginqueue or just archivemsgq to avoid misunderstanding of this command.
hoergen
on 24 Apr 2018
The command sets the "archive" flag of the contact. So the name is correct. _Additionally_ it removes entries from queued contacts from the queue.
So we only have to check if the remote contacts and servers do exist. If they do then we could check why the messages had been queued.
annando
on 24 Apr 2018
Still having the "queue filling up" problem. Now it slowly speeds up, so that I started deleting those "next" entries with the value "0001-01-01 00:00:00" manually.
As far I understand, this value should contain a date in the future, where the node will try to send this message to its destination. But because all those entries have a date in the past, it will never be delivered.
If I'm right with my assumption, there should be a simple check, if the date is older than the max waiting time for a message before it gets deleted.
hoergen
on 30 Apr 2018
The "next" field is the time when the entry is tried to send next. the 1.st Jan 1 is the lowest date possible. So when the worker is looking for a job that should be done and looks for dates in the past from the next table, those entries should be picked up.
 tobiasd
on 30 Apr 2018
tobiasd
on 30 Apr 2018
We will have a look on it, because those entries never disapeared.
https://horche.demkontinuum.de/display/ec054ce7115ae6d81c01421484272107
hoergen
on 30 Apr 2018
The queue is still filling (450). I deleted in between several times. And those entries are not vanishing sometime. They keep sitting there.
Some of the entries are from subscribed forums where the contacts doesnt exist any more for a long time.
hoergen
on 10 May 2018
There are as well a lot entries with this content . I put a picture in it, because the markdown editor interpreted it :(
And for sure normal posts ..
hoergen
on 10 May 2018
Deleting the queue doesn't help very much, archiving the contact does help better.
annando
on 10 May 2018
I know @annando . But as I asked several times before:
How do I archive contacts, that doesn't exist any more or where I don't have any connection to them?
hoergen
on 10 May 2018
With bin/console archivecontact http:://domain.tld/profile/user
annando
on 10 May 2018
So you mean it doesn't have something to do with my private account contacts, it has something to do with global "contacts"?
hoergen
on 10 May 2018
It has to be done for every contact on the server.
annando
on 10 May 2018
Thats not really an answer I can understand. .. what does that mean?
hoergen
on 10 May 2018
The contact url [email protected] can exist for many users - we have to archive them all.
annando
on 10 May 2018
Found something that may have to with it?
The path for the worker in my cronjob was wrong. I wonder how friendica worked and I could comunicate? anyways ...I corrected it. The worker is working now and my queue looks like 758 - 4431 now.
What was the second number for?
hoergen
on 10 May 2018
Jobs for the worker on the ToDo list. That should go down over time and may rise again during that time, but the trend should go down.
tobiasd
on 10 May 2018
Thanks a lot. Will watch it the next days. The database is working hard on my server. Top says it is working 124% ;)
hoergen
on 10 May 2018
Yeah, the wrong path was the reason. The system can work without it, but it won't be able to process all stuff in time - like you realized.
annando
on 10 May 2018
We will see. I doubt it a little that this is the reason for those "lost" entries and non existing contacts. But I'm happy looking forward to be completely wrong :)
hoergen
on 11 May 2018
Me too. :grin:
annando
on 11 May 2018
Checked the queue again: 1543 - 6053
and sorted to the most actual date looks like it stoped trying to deliver? Date and time are correct on the server.
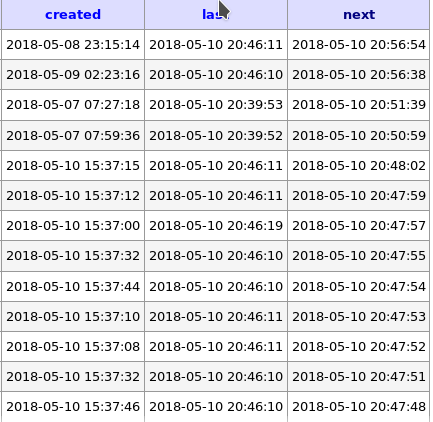
hoergen
on 11 May 2018
It is looking fine.
annando
on 11 May 2018
From my point of view this issue is solved.
hoergen
on 4 Jun 2018
Sorry, I thought you opened the issue.
MrPetovan
on 4 Jun 2018
AFAIK @ben-utzer had some performance issues on his machine that we solved during the 35C3. So I guess this should be fine now.
annando
on 27 Jan 2019
Related issues
 AlfredSK
·
66Comments
MrPetovan
·
71Comments
AlfredSK
·
66Comments
MrPetovan
·
71Comments
 clacke
·
76Comments
AlfredSK
·
47Comments
MrPetovan
·
52Comments
clacke
·
76Comments
AlfredSK
·
47Comments
MrPetovan
·
52Comments
Most helpful comment
Sorry, I thought you opened the issue.