I have a zombie process in my cluster. And this is not the first time.
I have web in my Procfile, and i scale it to 0. However, in the logs i have 1 always restarting web process
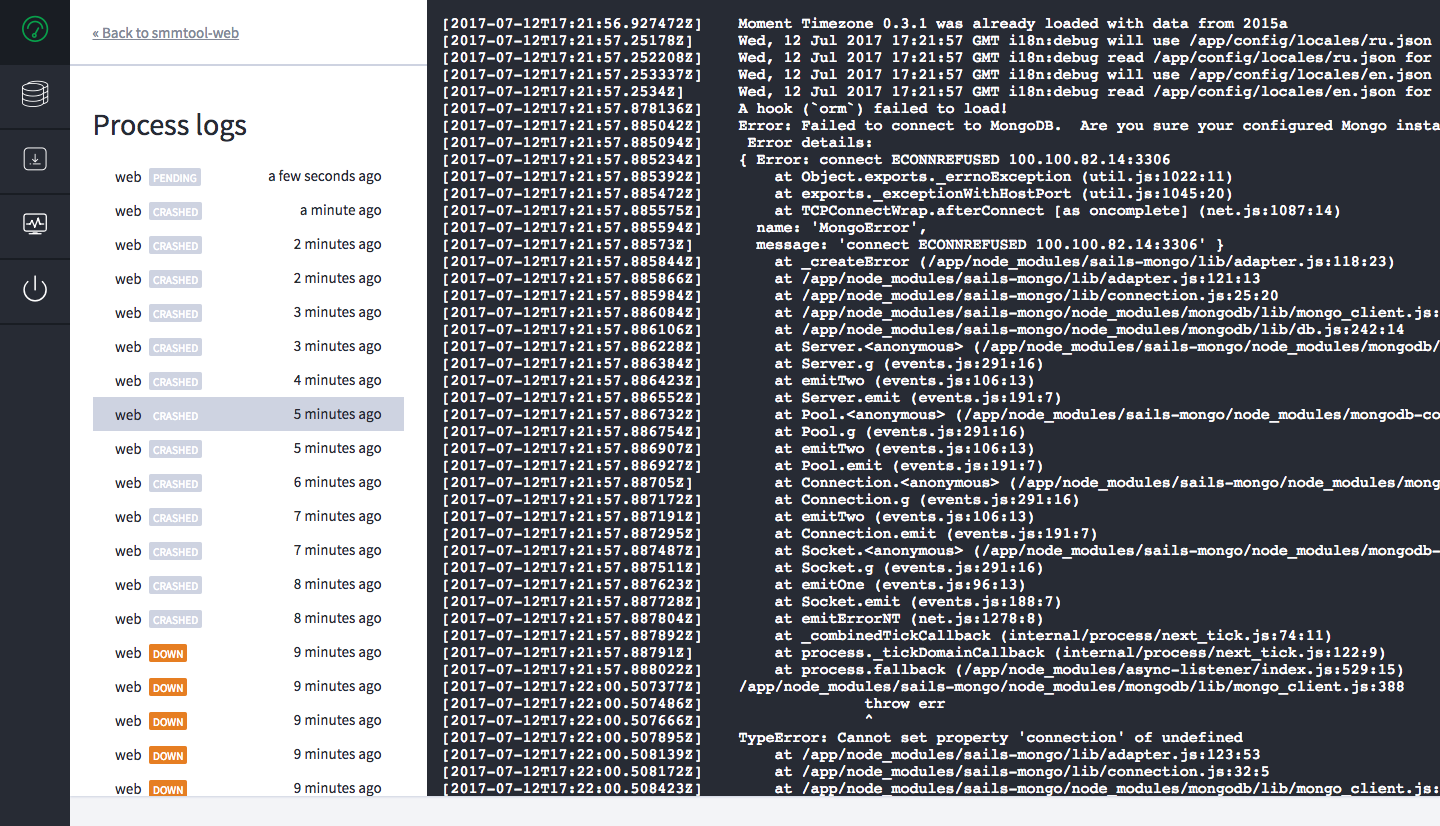
It starts, crashes with error, and starts again. And i dont know how to stop it, it is impossible.
By the way, if i scale to 1 or more, all my apps starts normally, without any error, but zombie continues to restart.
 dilame
dilame
All 14 comments
Check flynn scale -a for the app, perhaps an old release is running.
 titanous
on 12 Jul 2017
titanous
on 12 Jul 2017
@titanous i deleted my app and then created again. Now i dont see zombie in logs.
But anyway it is not normal.
flynn scale -a
9926fc70-10a8-4c18-9ae1-ffb0da81f786 (current)
web=6
36d76289-064f-46f9-a686-9aea97b3c342
@titanous why did you closed it? Isn't it a bug?
dilame
on 14 Jul 2017
It sounds like there was an old release running (can be scaled down with flynn scale -r RELEASE_ID web=0). Since you deleted the app there's not much to work with.
titanous
on 14 Jul 2017
@titanous it happened again. Now i have 3 extra processes.
dilame
on 18 Jul 2017
Please post the output of flynn scale -a (from a client) and flynn-host version (from a server).
titanous
on 18 Jul 2017
$ flynn scale -a
5bdc7af9-d31a-46b0-ac60-813b7bc0e64b (current)
fea0adf4-f4cc-4821-b090-cdabb645695e
94275862-ae16-45f7-8917-fd49c8237131
db876964-428e-4030-a050-e96434ea331c
web=3
fc59484a-188f-4a19-8a71-1a0efe84a728
d4ac8f5e-e554-4fc0-ade3-0097ddc2082d
a7549486-8016-4c53-a74b-c995d1de9bab
07260bbf-15fe-4baa-8092-0d64a51012f3
21d6ba36-115e-4492-9021-910cdd98e800
87d16b00-f445-4d53-9e7d-4d9738c6769d
73dec777-e96f-4b99-b33d-b5d898fc3a55
97830978-1b65-4879-a10d-fb3c8c97054c
c0c07105-c21a-4f45-bc41-2a2a9c79cd42
53f22d67-f405-4ba5-904e-bffb1458d2b0
root@ih588696:~# flynn-host version
v20170514.0-a013e9a
flynn scale -r db876964-428e-4030-a050-e96434ea331c web=0 will scale the processes down.
Run sudo flynn-host collect-debug-info and post the logs here so we can investigate.
titanous
on 18 Jul 2017
dilame
on 18 Jul 2017
This looks like a bug.
A deployment was started at 2017-07-18T01:30:50+0000 from release db876964-428e-4030-a050-e96434ea331c to 94275862-ae16-45f7-8917-fd49c8237131 but that failed because the new release failed to scale up, so a rollback to db876964-428e-4030-a050-e96434ea331c was performed:
t=2017-07-18T01:30:50+0000 lvl=info msg="handling deployment" app=worker fn=HandleDeployment job_id=31 error_count=0
t=2017-07-18T01:31:19+0000 lvl=eror msg="error scaling up new formation" app=worker fn=deployAllAtOnce release.id=94275862-ae16-45f7-8917-fd49c8237131 err="web job failed to start: got down job event"
t=2017-07-18T01:31:20+0000 lvl=info msg="restoring the original formation" app=worker fn=HandleDeployment deployment_id=6d45d5ad-142c-4b16-8a41-77b88939b6e4 app_id=62482d0a-d2a4-4f30-a211-5f9dda35a74e strategy=all-at-once fn=rollback release.id=db876964-428e-4030-a050-e96434ea331c
The deploy was retried and the worker decided there was nothing to do, thus leaving the old release scaled up:
t=2017-07-18T01:31:40+0000 lvl=info msg="handling deployment" app=worker fn=HandleDeployment job_id=31 error_count=1
t=2017-07-18T01:31:40+0000 lvl=info msg="deployment already completed, nothing to do" app=worker fn=Perform deployment_id=6d45d5ad-142c-4b16-8a41-77b88939b6e4 app_id=62482d0a-d2a4-4f30-a211-5f9dda35a74e
t=2017-07-18T01:31:40+0000 lvl=info msg="setting the app release" app=worker fn=HandleDeployment deployment_id=6d45d5ad-142c-4b16-8a41-77b88939b6e4 app_id=62482d0a-d2a4-4f30-a211-5f9dda35a74e strategy=all-at-once
t=2017-07-18T01:31:40+0000 lvl=info msg="deployment complete" app=worker fn=HandleDeployment deployment_id=6d45d5ad-142c-4b16-8a41-77b88939b6e4 app_id=62482d0a-d2a4-4f30-a211-5f9dda35a74e strategy=all-at-once
We should investigate why the worker deemed the deployment as complete (and make sure it scales the old release down even if the new release is up and running).
 lmars
on 19 Jul 2017
lmars
on 19 Jul 2017
This happens from time to time, specially if you stop the deployment on the middle of it. Like you did a git push and cancelled, or when the deployment fails to start.
The only way out is to kill the zombie instance manually:
flynn scale -r RELEASE_ID web=0
But the error persists and the cluster becomes to get worse and worse, at some point I usually experience that this completely kill the cluster making me start from the backups again or from scratch with a new deployment of everything.
 thomasmodeneis
on 8 Jun 2018
thomasmodeneis
on 8 Jun 2018
Does anybody have any idea how to stop these?
It's not caused by a failed deployment, or the deployment failing to start - these happen after a few weeks of uptime for almost all our applications.
We typically have to rebuild the cluster.
When we try and scale to zero with the release ID we get dial tcp: i/o timeout
 troykelly
on 22 Jan 2020
troykelly
on 22 Jan 2020
@troykelly it's better to go kubernetes or dokku.
dilame
on 22 Jan 2020
Flynn is unmaintained and our infrastructure will shut down on June 1, 2021. See the README for details.
titanous
on 18 Feb 2021
Related issues
 neil-wwt
·
19Comments
titanous
·
24Comments
neil-wwt
·
19Comments
titanous
·
24Comments
 kareemcoding
·
17Comments
kareemcoding
·
17Comments
 Detry322
·
88Comments
troykelly
·
9Comments
Detry322
·
88Comments
troykelly
·
9Comments
Most helpful comment
This looks like a bug.
A deployment was started at
2017-07-18T01:30:50+0000from releasedb876964-428e-4030-a050-e96434ea331cto94275862-ae16-45f7-8917-fd49c8237131but that failed because the new release failed to scale up, so a rollback todb876964-428e-4030-a050-e96434ea331cwas performed:The deploy was retried and the worker decided there was nothing to do, thus leaving the old release scaled up:
We should investigate why the worker deemed the deployment as complete (and make sure it scales the old release down even if the new release is up and running).