Flux: Adding CRDs to Flux repo leads to high sync time and CPU usage
Describe the bug
While our git repository is fairly big, we recently added Prometheus-Operator CRDs (https://github.com/helm/charts/tree/master/stable/prometheus-operator/crds). That single change lead to a high CPU usage and Flux is now taking a long time to sync. In our case, we are reaching the 5 minutes timeout.

We already have several CRDs in Flux and such a behavior never happened before.
The behavior of Helm V3 / Helm-Operator is to never update a CRD. This is why we are pushing them through Flux directly.
To Reproduce
Tested configuration:
- Flux chart from
https://charts.fluxcd.io/ - Chart version: 1.4.0
- Values:
additionalArgs: ["--connect=ws://fluxcloud"]
git:
pollInterval: 1m
timeout: 2m
image:
tag: "1.20.1"
manifestGeneration: true
registry:
automationInterval: 1m
resources:
requests:
cpu: 1
memory: 500Mi
sync:
timeout: 5m
interval: 5m
syncGarbageCollection:
enabled: true
- Add the CRDs (https://github.com/helm/charts/tree/master/stable/prometheus-operator/crds) to the repository watched by Flux
- Observe a big increase in CPU usage and a longer sync time
Expected behavior
A small increase in CPU as the CRDs are not "that big".
Logs
No relevant logs
Additional context
- Flux version: 1.20.1
- Kubernetes version: v1.16.11-gke.5
- Git provider: NA
- Container registry provider: NA
I'm unsure if the problem is coming from unmarshal, validation, ... so if you need more information (profile / flame graph / ...), ping me.
 Sayrus
Sayrus
All 6 comments
See https://github.com/kubernetes/kubernetes/pull/92456 until the fix is merged and released in kubectl there is nothing we can do.
 stefanprodan
on 7 Aug 2020
stefanprodan
on 7 Aug 2020
Great to hear that this is already a known issue and not some unique weird behavior.
Thanks for linking the issue.
Shall I keep this issue open until the fix is merged?
Sayrus
on 7 Aug 2020
Yes let's keep it opened until we have a kubectl fix.
stefanprodan
on 7 Aug 2020
Looks to be fixed in kubectl 1.17.10 and above.
 wlritchi
on 13 Aug 2020
wlritchi
on 13 Aug 2020
I can confirm with a prerelease build with multiple CRDs (kube-prometheues, istio + more) seeing much faster overall sync times + CPU/Mem reduction.
@stefanprodan Any chance on cutting a patch release soon primarily for this fix?
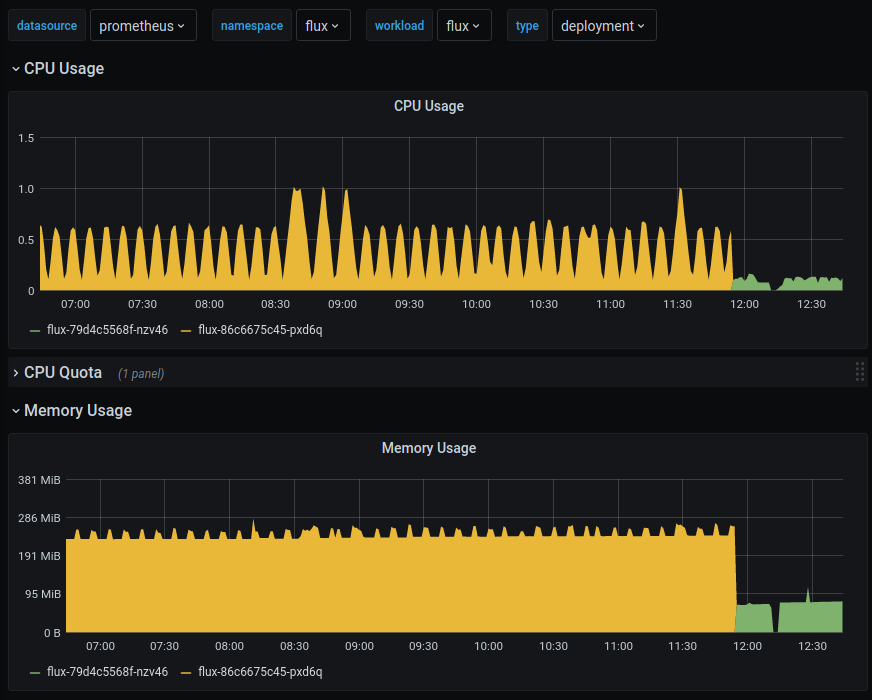

 Dev25
on 19 Aug 2020
Dev25
on 19 Aug 2020
@Dev25 yes, today we'll publish a patch release.
stefanprodan
on 19 Aug 2020
Related issues
 phoppe93
·
4Comments
phoppe93
·
4Comments
 alexhumphreys
·
4Comments
alexhumphreys
·
4Comments
 eimarfandino
·
3Comments
eimarfandino
·
3Comments
 astraldragon
·
3Comments
astraldragon
·
3Comments
 MaralKay
·
3Comments
MaralKay
·
3Comments
Most helpful comment
@Dev25 yes, today we'll publish a patch release.