Fluent-bit: [backpressure setup issue] Fluent Bit is OOM-Killed (8 GB Mem usage) during load test
Problem Report
Describe the problem
I'm trying to run Fluent Bit as a centralized aggregator. I have a bunch of containers which logs to a single Fluent Bit instance (also a container) using the Fluentd Docker Log Driver. This works, but Fluent Bit's memory usage climbs continuously until it is OOMKilled. The memory limit for the Fluent Bit container is 8 GB. So the OOMKill is surprising.
I am not currently using this in production- I'm load testing Fluent Bit to see what it can handle.
The OOM Kill only happens under high load. My load-test containers output events at 200 log lines per second- they output standard apache log lines. (That's 200*200 = 40,000 events per second- 2.4 million per minute).
With 200 containers sending logs over Forward TCP to Fluent Bit, it will reach 8 GB of memory and be killed after about 2 hours. With 150 containers, it still eventually dies, but takes a bit longer for its memory usage to reach 8 GB.
With 100 containers, it does not always die. That's 20,000 events per second, ~1 million per minute.
Have I simply pushed Fluent Bit to its limits, or could I get better results?
To Reproduce
- Example log message if applicable:
{"log":"209.125.74.30 - Fadel6076 656 [2019-11-24T07:03:27Z] "GET /roi/web services/bricks-and-clicks/user-centric" 405 15442","stream":"stdout","time":"2018-06-11T14:37:30.681701731Z"}
Expected behavior
After looking at this repo, I thought Fluent Bit could comfortably handle a few million events per minute: https://github.com/fluent/fluent-bit-perf
I understand though that the results of a performance test my depend on the details.
I've run Fluentd under similarly high load though and its memory usage stayed under 8 GB.
Screenshots
These images show memory usage metrics for the Fluent Bit aggregator. The Y-axis is percent of limit (which is 8 GB). The saw-tooth comes from it getting OOM-Killed and then re-started.
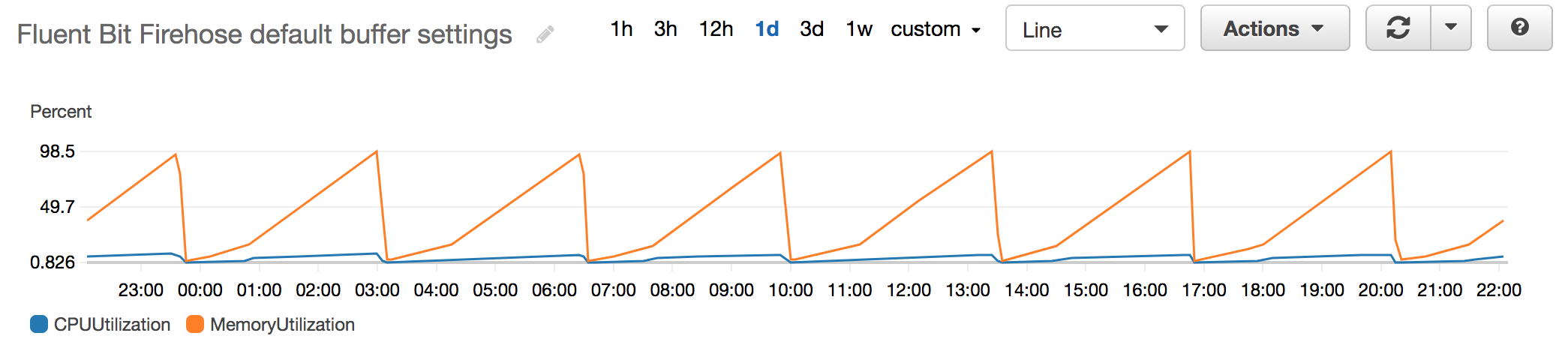

Your Environment
- Version used: 1.3.2 - with the amazon/aws-for-fluent-bit image.
- Configuration: I tried multiple configs: one, two, and three.
- Environment name and version (e.g. Kubernetes? What version?): Amazon ECS
- Server type and version: Amazon EC2 c5.9xlarge instance, which I think use Skylate Xeon processors. I constrained my container so that it can only use 4 threads though. I can provide more details if that truly helps.
- Operating System and version: Amazon Linux 2. I can provide more details if that truly helps.
- Filters and plugins: No filters, just the AWS Fluent Bit output plugins for CloudWatch and Kinesis. Which are external Go Plugins.
 PettitWesley
PettitWesley
All 7 comments
I removed bug from the title because I don't think its fair to call this a bug. Fluent Bit performs pretty well. I think/hope it could do better though.
I'm going to try (when I have time) the following modifications next:
- Allow Fluent Bit a higher docker CPU limit (though given Fluent Bit is not multi-threaded I doubt this will help)
- Try a file buffer
- Use a built in output which is not a Go plugin. I have a sinking suspicion that the multiple Go plugin instances are very inefficient.
Please let me know if you have any other suggestions!
PettitWesley
on 24 Nov 2019
what about if you add the mem_buf_limit option to the input side ?:
[INPUT]
Name forward
Listen 0.0.0.0
Port 24224
Mem_Buf_Limit 2G
reference: https://docs.fluentbit.io/manual/configuration/backpressure
 edsiper
on 24 Nov 2019
edsiper
on 24 Nov 2019
@PettitWesley Can you confirm that the outputs have the capacity to scale up that much? Fluent-bit can either buffer in the hope of bandwidth becoming available, or drop records to avoid out-of-memory or out-of-disk. Can 200 containers be sustained with a file output, rather than forward?
 nigels-com
on 25 Nov 2019
nigels-com
on 25 Nov 2019
@PettitWesley did you try the mem_buf_limit option ?
edsiper
on 11 Dec 2019
@nigels-com Can you confirm that the outputs have the capacity to scale up that much?
They do. The aggregator splits logs between 10 outputs, all of which are for Amazon CloudWatch Logs. It should be able to handle the throughput: https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/cloudwatch_limits_cwl.html
With default limits you get 5 MB/s or 50,000 events/second per stream- I'm sending to 10 streams.
I'm working on testing out your suggestion @edsiper.
PettitWesley
on 11 Dec 2019
@edsiper I re-deployed the aggregator with Mem_Buf_Limit 2G, it is stable now.
Thank you!
PettitWesley
on 11 Dec 2019
Thanks!
Just for the record:
When the destination service or due to network restriction the data cannot flow fast enough, Fluent Bit will face backpressure since it's also retrieving more data from it sources. To deal with Backpressure we recommend to use the Mem_Buf_Limit option, more details here:
edsiper
on 11 Dec 2019
Related issues
 dawidmalina
·
31Comments
dawidmalina
·
31Comments
 rgomesf
·
32Comments
rgomesf
·
32Comments
 max-rocket-internet
·
24Comments
max-rocket-internet
·
24Comments
 mitchellmaler
·
24Comments
edsiper
·
64Comments
mitchellmaler
·
24Comments
edsiper
·
64Comments
Most helpful comment
Thanks!
Just for the record:
When the destination service or due to network restriction the data cannot flow fast enough, Fluent Bit will face backpressure since it's also retrieving more data from it sources. To deal with Backpressure we recommend to use the Mem_Buf_Limit option, more details here: