Flair: Tokenization MISMATCH and RuntimeError: shape '[...]' is invalid for input
HI, I am trying to use TransformerWordEmbeddings("bert-base-cased") to train a sequential labeller with IOB labels (only "I", "O", "B" without subcategories). I started from the tutorial code (no optimisation yet) and my own train-test-dev data. My corpus seems to be created without any trouble and when I use flair embeddings I don't get any errors and good results.
This is a sample sentence from the corpus:
Treatment of anemia \ in patients \ with heart \ disease \ : a clinical \ practice \ guideline \ from the American \ College \ of \ Physicians \ .
However, with "bert-base-cased" I get the following message:
Tokenization MISMATCH in sentence '2λr d λr = 6(4a - 1)(1 - 2a ) 2 / ( 1 - 3a ) 2 da '
Last matched: 'Token: 19 '
Last sentence: 'Token: 22 '
subtokenized: '['[CLS]', '2', '##λ', '##r', 'd', 'λ', '##r', '=', '6', '(', '4', '##a', '-', '1', ')', '(', '1', '-', '2', '##a', ')', '2', '/', '(', '1', '-', '3', '##a', ')', '2', 'da', '[SEP]']'
(I see some of the special characters don't display correctly in this text, it concerns unicode symbols U+2308 up to U+230B)
The message is followed by this error:
RuntimeError: shape '[32, 72, 3072]' is invalid for input of size 7065600
Is there any way to solve this without changing the tokens in the corpus itself?
PS: I run this code on a mac (Catalina), with PyCharm
 AylaRT
AylaRT
All 20 comments
I also have a similar issue using a custom trained BERT
My corpus might contain different characters, but I would assume this shouldn't interrupt the training
 eh-93
on 17 Jun 2020
eh-93
on 17 Jun 2020
Hello @AylaRT and @eh-93 could you try using the latest master version of Flair? At least the example sentence @AylaRT pasted seems to work there.
You can install from master with:
pip install --upgrade git+https://github.com/flairNLP/flair.git
 alanakbik
on 23 Jun 2020
alanakbik
on 23 Jun 2020
Hello @AylaRT and @eh-93 could you try using the latest master version of Flair? At least the example sentence @AylaRT pasted seems to work there.
You can install from master with:
pip install --upgrade git+https://github.com/flairNLP/flair.git
Thank you, this seems to work!
AylaRT
on 23 Jun 2020
Great, Flair 0.5.1 is coming probably this week that contains this fix!
alanakbik
on 23 Jun 2020
Hello, I am having the very same issue with a code to train a Sequence Tagger with CamemBERT. I use the french Wikiner corpus that I separated in 3 columns like this :
Il PRO:PER O
assure VER:pres O
à VER:pper O
la DET:ART O
suite NOM O
de PRP I-PER
Saussure NAM I-PER
le DET:ART O
because I had an encoding issue while tring to use this :
wiki_french = flair.datasets.WIKINER_FRENCH()
Here is my code to train the Sequence tagger model with CamemBERT :
from flair.data import Corpus
from flair.datasets import UD_ENGLISH
from flair.embeddings import TokenEmbeddings, WordEmbeddings, StackedEmbeddings
# 1. get the corpus
#corpus: Corpus = UD_ENGLISH().downsample(0.1)
print(corpus)
# 5. initialize sequence tagger
from flair.models import SequenceTagger
tagger: SequenceTagger = SequenceTagger(hidden_size=768,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type=tag_type,
use_crf=True)
# 6. initialize trainer
from flair.trainers import ModelTrainer
trainer: ModelTrainer = ModelTrainer(tagger, corpus)
# 7. start training
trainer.train('example-ner',
learning_rate=3e-5,
mini_batch_size=32,
max_epochs=150)
I get the following error :
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-16-af87aff77ef6> in <module>
3 learning_rate=3e-5,
4 mini_batch_size=32,
----> 5 max_epochs=150)
c:\users\nicod\miniconda3\lib\site-packages\flair\trainers\trainer.py in train(self, base_path, learning_rate, mini_batch_size, mini_batch_chunk_size, max_epochs, scheduler, anneal_factor, patience, initial_extra_patience, min_learning_rate, train_with_dev, monitor_train, monitor_test, embeddings_storage_mode, checkpoint, save_final_model, anneal_with_restarts, anneal_with_prestarts, batch_growth_annealing, shuffle, param_selection_mode, num_workers, sampler, use_amp, amp_opt_level, eval_on_train_fraction, eval_on_train_shuffle, **kwargs)
347
348 # forward pass
--> 349 loss = self.model.forward_loss(batch_step)
350
351 # Backward
c:\users\nicod\miniconda3\lib\site-packages\flair\models\sequence_tagger_model.py in forward_loss(self, data_points, sort)
597 self, data_points: Union[List[Sentence], Sentence], sort=True
598 ) -> torch.tensor:
--> 599 features = self.forward(data_points)
600 return self._calculate_loss(features, data_points)
601
c:\users\nicod\miniconda3\lib\site-packages\flair\models\sequence_tagger_model.py in forward(self, sentences)
632 len(sentences),
633 longest_token_sequence_in_batch,
--> 634 self.embeddings.embedding_length,
635 ]
636 )
RuntimeError: shape '[32, 68, 768]' is invalid for input of size 976128
I also have this warning repeated multiple times before the error trace :
Truncation was not explicitely activated butmax_lengthis provided a specific value, please usetruncation=Trueto explicitely truncate examples to max length. Defaulting to 'only_first' truncation strategy. If you encode pairs of sequences (GLUE-style) with the tokenizer you may want to check this is the right behavior.
But I didn't find where I can set this "truncation" to True. I also tried to upgrade Flair but I still have the issue. Any idea ?
 Nighthyst
on 29 Jun 2020
Nighthyst
on 29 Jun 2020
That's strange. Can you past the full example code to run and get this error?
I note that your learning rate is extremely small and the SequenceTagger hidden states are very large. We normally set a learning rate of 0.1 and 256 hidden states in the sequence tagger.
alanakbik
on 3 Jul 2020
For the learning rate, I choosed the one mentionned in the section "Training a Text Classification Model with Transformer" of the documentation : https://github.com/flairNLP/flair/blob/master/resources/docs/TUTORIAL_7_TRAINING_A_MODEL.md
I thought it made sense since when fine-tuning a transformer we don't want to make drastic changes to the model. For the hidden_size however, I had no idea how to choose it, so I went for the dimension of the output of the last layer of the camemBERT model. I am sorry : in my previous code snippet I forgot several lines.
So here is my full code :
from flair.embeddings import TransformerDocumentEmbeddings
from flair.data import Corpus
from flair.datasets import ColumnCorpus
# define columns
columns = {0: 'text', 1: 'pos', 2: 'ner'}
# this is the folder in which train, test and dev files reside
data_folder = 'wikiner'
# init a corpus using column format, data folder and the names of the train, dev and test files
corpus = ColumnCorpus(data_folder =data_folder,
column_format=columns,
train_file='train.txt',
test_file='test.txt',
in_memory=False)
# 1. get the corpus
#corpus: Corpus = UD_ENGLISH().downsample(0.1)
print(corpus)
# 2. what tag do we want to predict?
tag_type = 'ner'
# 3. make the tag dictionary from the corpus
tag_dictionary = corpus.make_tag_dictionary(tag_type=tag_type)
print(tag_dictionary)
# 4. initialize embeddings
embeddings = TransformerDocumentEmbeddings('camembert-base', fine_tune=True)
# 5. initialize sequence tagger
from flair.models import SequenceTagger
tagger: SequenceTagger = SequenceTagger(hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type=tag_type,
use_crf=True)
# 6. initialize trainer
from flair.trainers import ModelTrainer
trainer: ModelTrainer = ModelTrainer(tagger, corpus)
# 7. start training
trainer.train('example-ner-test',
learning_rate=0.1,
mini_batch_size=32,
max_epochs=2,
eval_on_train_fraction=0.1,
embeddings_storage_mode="gpu",
monitor_test=True,
checkpoint=True)
Even with a learning rate of 0.1 and a hidden size of 256 I run into the same issue :
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-4-a789edebda0e> in <module>
37 embeddings_storage_mode="gpu",
38 monitor_test=True,
---> 39 checkpoint=True)
c:\users\nicod\miniconda3\lib\site-packages\flair\trainers\trainer.py in train(self, base_path, learning_rate, mini_batch_size, mini_batch_chunk_size, max_epochs, scheduler, anneal_factor, patience, initial_extra_patience, min_learning_rate, train_with_dev, monitor_train, monitor_test, embeddings_storage_mode, checkpoint, save_final_model, anneal_with_restarts, anneal_with_prestarts, batch_growth_annealing, shuffle, param_selection_mode, num_workers, sampler, use_amp, amp_opt_level, eval_on_train_fraction, eval_on_train_shuffle, **kwargs)
347
348 # forward pass
--> 349 loss = self.model.forward_loss(batch_step)
350
351 # Backward
c:\users\nicod\miniconda3\lib\site-packages\flair\models\sequence_tagger_model.py in forward_loss(self, data_points, sort)
506 self, data_points: Union[List[Sentence], Sentence], sort=True
507 ) -> torch.tensor:
--> 508 features = self.forward(data_points)
509 return self._calculate_loss(features, data_points)
510
c:\users\nicod\miniconda3\lib\site-packages\flair\models\sequence_tagger_model.py in forward(self, sentences)
539 len(sentences),
540 longest_token_sequence_in_batch,
--> 541 self.embeddings.embedding_length,
542 ]
543 )
RuntimeError: shape '[32, 42, 768]' is invalid for input of size 379392
I use Flair 0.5 with Python 3.6.9 on Windows 10. My Wikiner dataset is pretty huge (roughly 295MB for train and test together) but you can see what it looks like in my sample.txt file.
On my laptop I have 16 GB RAM, a NVIDIA GeForce GTX 1050 Ti GDDR5 and CUDA 10.1. I run out of memory if I tried to load the dataset in memory by putting in_memory to True. But since I have a graphic card and CUDA I put embeddings_storage_mode to "gpu" this time.
Nighthyst
on 3 Jul 2020
Thanks for sharing the script - I'll see if it runs on my setup.
For sequence labeling, we generally find two options to work:
- fine-tune embeddings, very small learning rate, Adam optimizer and 5 epochs,
- do not fine-tune embeddings, 0.1 learning rate, SGD and 150 epochs
The above script looks like option 2, but you should set fine_tune=False. If you want to fine-tune, you should use the Adam optimizer, like in this example.
alanakbik
on 3 Jul 2020
Oh wait, I see the error now :D you should use TransformerWordEmbeddings, not TransformerDocumentEmbeddings.
alanakbik
on 3 Jul 2020
I.e. try these parameters:
# 4. initialize embeddings
embeddings = TransformerWordEmbeddings('camembert-base',
layers='all',
use_scalar_mix=True,
pooling_operation='mean')
# 5. initialize sequence tagger
from flair.models import SequenceTagger
tagger: SequenceTagger = SequenceTagger(hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type=tag_type,
use_crf=True)
# 6. initialize trainer
from flair.trainers import ModelTrainer
trainer: ModelTrainer = ModelTrainer(tagger, corpus)
# 7. start training
trainer.train('example-ner-test',
learning_rate=0.1,
mini_batch_size=32,
max_epochs=150,
embeddings_storage_mode="cpu",
monitor_test=True,
checkpoint=True)
Ok that wasn't a very interesting error to solve I guess (sorryyyy). Thank you for your insights I'll try this right away
Nighthyst
on 3 Jul 2020
With this code :
from flair.embeddings import TransformerWordEmbeddings
from flair.data import Corpus
from flair.datasets import ColumnCorpus
# define columns
columns = {0: 'text', 1: 'pos', 2: 'ner'}
# this is the folder in which train, test and dev files reside
data_folder = 'wikiner'
# init a corpus using column format, data folder and the names of the train, dev and test files
corpus = ColumnCorpus(data_folder =data_folder,
column_format=columns,
train_file='train.txt',
test_file='test.txt',
in_memory=False)
# 1. get the corpus
#corpus: Corpus = UD_ENGLISH().downsample(0.1)
print(corpus)
# 2. what tag do we want to predict?
tag_type = 'ner'
# 3. make the tag dictionary from the corpus
tag_dictionary = corpus.make_tag_dictionary(tag_type=tag_type)
print(tag_dictionary)
# 4. initialize embeddings
embeddings = TransformerWordEmbeddings('camembert-base',
layers='all',
use_scalar_mix=True,
pooling_operation='mean')
# 5. initialize sequence tagger
from flair.models import SequenceTagger
tagger: SequenceTagger = SequenceTagger(hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type=tag_type,
use_crf=True)
# 6. initialize trainer
from flair.trainers import ModelTrainer
trainer: ModelTrainer = ModelTrainer(tagger, corpus)
# 7. start training
trainer.train('example-ner-cam',
learning_rate=0.1,
mini_batch_size=32,
max_epochs=150,
embeddings_storage_mode="cpu",
monitor_test=True,
checkpoint=True)
This time I have this very different error :
2020-07-04 02:12:16,098 ----------------------------------------------------------------------------------------------------
2020-07-04 02:12:16,098 Corpus: "Corpus: 191579 train + 21287 dev + 53484 test sentences"
2020-07-04 02:12:16,098 ----------------------------------------------------------------------------------------------------
2020-07-04 02:12:16,098 Parameters:
2020-07-04 02:12:16,098 - learning_rate: "0.1"
2020-07-04 02:12:16,098 - mini_batch_size: "32"
2020-07-04 02:12:16,098 - patience: "3"
2020-07-04 02:12:16,098 - anneal_factor: "0.5"
2020-07-04 02:12:16,098 - max_epochs: "150"
2020-07-04 02:12:16,113 - shuffle: "True"
2020-07-04 02:12:16,113 - train_with_dev: "False"
2020-07-04 02:12:16,113 - batch_growth_annealing: "False"
2020-07-04 02:12:16,113 ----------------------------------------------------------------------------------------------------
2020-07-04 02:12:16,113 Model training base path: "example-ner-cam"
2020-07-04 02:12:16,113 ----------------------------------------------------------------------------------------------------
2020-07-04 02:12:16,113 Device: cuda:0
2020-07-04 02:12:16,113 ----------------------------------------------------------------------------------------------------
2020-07-04 02:12:16,113 Embeddings storage mode: cpu
2020-07-04 02:12:16,113 ----------------------------------------------------------------------------------------------------
Traceback (most recent call last):
File "<string>", line 1, in <module>
Traceback (most recent call last):
File "example1.py", line 56, in <module>
File "C:\Users\nicod\Miniconda3\lib\multiprocessing\spawn.py", line 105, in spawn_main
checkpoint=True)exitcode = _main(fd)
File "C:\Users\nicod\Miniconda3\lib\site-packages\flair\trainers\trainer.py", line 330, in train
File "C:\Users\nicod\Miniconda3\lib\multiprocessing\spawn.py", line 114, in _main
for batch_no, batch in enumerate(batch_loader):prepare(preparation_data)
File "C:\Users\nicod\Miniconda3\lib\site-packages\torch\utils\data\dataloader.py", line 279, in __iter__
File "C:\Users\nicod\Miniconda3\lib\multiprocessing\spawn.py", line 225, in prepare
return _MultiProcessingDataLoaderIter(self)_fixup_main_from_path(data['init_main_from_path'])
File "C:\Users\nicod\Miniconda3\lib\site-packages\torch\utils\data\dataloader.py", line 719, in __init__
File "C:\Users\nicod\Miniconda3\lib\multiprocessing\spawn.py", line 277, in _fixup_main_from_path
w.start()
run_name="__mp_main__") File "C:\Users\nicod\Miniconda3\lib\multiprocessing\process.py", line 105, in start
File "C:\Users\nicod\Miniconda3\lib\runpy.py", line 263, in run_path
self._popen = self._Popen(self)pkg_name=pkg_name, script_name=fname)
File "C:\Users\nicod\Miniconda3\lib\multiprocessing\context.py", line 223, in _Popen
File "C:\Users\nicod\Miniconda3\lib\runpy.py", line 96, in _run_module_code
return _default_context.get_context().Process._Popen(process_obj)mod_name, mod_spec, pkg_name, script_name)
File "C:\Users\nicod\Miniconda3\lib\multiprocessing\context.py", line 322, in _Popen
File "C:\Users\nicod\Miniconda3\lib\runpy.py", line 85, in _run_code
return Popen(process_obj)exec(code, run_globals)
File "C:\Users\nicod\Miniconda3\lib\multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "C:\Users\nicod\Desktop\camembert\example1.py", line 56, in <module>
reduction.dump(process_obj, to_child)checkpoint=True)
File "C:\Users\nicod\Miniconda3\lib\multiprocessing\reduction.py", line 60, in dump
File "C:\Users\nicod\Miniconda3\lib\site-packages\flair\trainers\trainer.py", line 330, in train
ForkingPickler(file, protocol).dump(obj)for batch_no, batch in enumerate(batch_loader):
BrokenPipeError File "C:\Users\nicod\Miniconda3\lib\site-packages\torch\utils\data\dataloader.py", line 279, in __iter__
: [Errno 32] Broken pipereturn _MultiProcessingDataLoaderIter(self)
File "C:\Users\nicod\Miniconda3\lib\site-packages\torch\utils\data\dataloader.py", line 719, in __init__
w.start()
File "C:\Users\nicod\Miniconda3\lib\multiprocessing\process.py", line 105, in start
self._popen = self._Popen(self)
File "C:\Users\nicod\Miniconda3\lib\multiprocessing\context.py", line 223, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "C:\Users\nicod\Miniconda3\lib\multiprocessing\context.py", line 322, in _Popen
return Popen(process_obj)
File "C:\Users\nicod\Miniconda3\lib\multiprocessing\popen_spawn_win32.py", line 33, in __init__
prep_data = spawn.get_preparation_data(process_obj._name)
File "C:\Users\nicod\Miniconda3\lib\multiprocessing\spawn.py", line 143, in get_preparation_data
_check_not_importing_main()
File "C:\Users\nicod\Miniconda3\lib\multiprocessing\spawn.py", line 136, in _check_not_importing_main
is not going to be frozen to produce an executable.''')
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
This time it sounds like a more difficult error to solve that only a few people reported in the issues section :
1665
1029
777
No one seemed to know a solution for that. Also I have a question : what is the difference between using :
flair.embeddings.TransformerWordEmbeddings('camembert-base')
and
flair.embeddings.CamembertEmbeddings()
I mean, when should we use one rather than the other ?
Nighthyst
on 4 Jul 2020
Hello, the CamembertEmbeddings are deprecated now so you should use TransformerWordEmbeddings instead.
The multiprocessing error its more difficult. Looks like it is thrown by PyTorch's DataLoader so I am not sure if we can fix this from the Flair side.
alanakbik
on 5 Jul 2020
Hello, I did some research about this error and indeed it seems to be some errors in PyTorch. Some people facing this same error, solved it by addind the :
if __name__ == '__main__':
protection. On Windows it seems to be necessary if we want multiprocessing to behave properly as said here :
https://github.com/pytorch/pytorch/issues/6183#issuecomment-378449567
https://github.com/pytorch/pytorch/issues/7485#issuecomment-388246016
Even the PyTorch documentation mentions this error. So it seems to be an error specific to Windows.
However I've tried to add the protection to my code on two OS : Windows and Ubuntu 16.04 (on AWS). Here is the script I launched on both :
from flair.embeddings import TransformerWordEmbeddings
from flair.data import Corpus
from flair.datasets import ColumnCorpus
import torch
def trainCamembert():
torch.multiprocessing.freeze_support()
# define columns
columns = {0: 'text', 1: 'pos', 2: 'ner'}
# this is the folder in which train, test and dev files reside
data_folder = 'wikiner'
# init a corpus using column format, data folder and the names of the train, dev and test files
corpus = ColumnCorpus(data_folder =data_folder,
column_format=columns,
train_file='train.txt',
test_file='test.txt',
in_memory=False)
# 1. get the corpus
#corpus: Corpus = UD_ENGLISH().downsample(0.1)
print(corpus)
# 2. what tag do we want to predict?
tag_type = 'ner'
# 3. make the tag dictionary from the corpus
tag_dictionary = corpus.make_tag_dictionary(tag_type=tag_type)
print(tag_dictionary)
# 4. initialize embeddings
embeddings = TransformerWordEmbeddings('camembert-base',
layers='all',
use_scalar_mix=True,
pooling_operation='mean')
# 5. initialize sequence tagger
from flair.models import SequenceTagger
tagger: SequenceTagger = SequenceTagger(hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type=tag_type,
use_crf=True)
# 6. initialize trainer
from flair.trainers import ModelTrainer
trainer: ModelTrainer = ModelTrainer(tagger, corpus)
# 7. start training
trainer.train('example-ner-camtest',
learning_rate=0.1,
mini_batch_size=32,
max_epochs=150,
embeddings_storage_mode="cpu",
monitor_test=True,
checkpoint=True)
if __name__=="__main__":
trainCamembert()
- On Windows
The execution hangs forever after printing a bunch of warnings
- On Ubuntu
This time we have the previous issue :
2020-07-05 12:51:39,157 ----------------------------------------------------------------------------------------------------
2020-07-05 12:51:39,157 Corpus: "Corpus: 191579 train + 21287 dev + 53484 test sentences"
2020-07-05 12:51:39,157 ----------------------------------------------------------------------------------------------------
2020-07-05 12:51:39,158 Parameters:
2020-07-05 12:51:39,158 - learning_rate: "0.1"
2020-07-05 12:51:39,158 - mini_batch_size: "32"
2020-07-05 12:51:39,158 - patience: "3"
2020-07-05 12:51:39,158 - anneal_factor: "0.5"
2020-07-05 12:51:39,158 - max_epochs: "150"
2020-07-05 12:51:39,158 - shuffle: "True"
2020-07-05 12:51:39,158 - train_with_dev: "False"
2020-07-05 12:51:39,158 - batch_growth_annealing: "False"
2020-07-05 12:51:39,158 ----------------------------------------------------------------------------------------------------
2020-07-05 12:51:39,158 Model training base path: "example-ner-camtest"
2020-07-05 12:51:39,158 ----------------------------------------------------------------------------------------------------
2020-07-05 12:51:39,158 Device: cuda:0
2020-07-05 12:51:39,158 ----------------------------------------------------------------------------------------------------
2020-07-05 12:51:39,158 Embeddings storage mode: cpu
2020-07-05 12:51:39,159 ----------------------------------------------------------------------------------------------------
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
2020-07-05 12:58:33,712 Tokenization MISMATCH in sentence 'V354 Cephei , RW Cephei sont d' autres supergéantes rouge .'
2020-07-05 12:58:33,712 Last matched: 'Token: 6 '
2020-07-05 12:58:33,712 Last sentence: 'Token: 12 .'
2020-07-05 12:58:33,713 subtokenized: '['<s>', '▁V', '35', '4', '▁Ce', 'phe', 'i', '▁', ',', '▁R', 'W', '▁Ce', 'phe', 'i', '▁sont', '▁d', "'", '▁autres', '▁super', 'gé', 'antes', '▁rouge', '▁', '.', '</s>']'
Traceback (most recent call last):
File "example1.py", line 62, in <module>
trainCamembert()
File "example1.py", line 59, in trainCamembert
checkpoint=True)
File "/home/ubuntu/anaconda3/lib/python3.7/site-packages/flair/trainers/trainer.py", line 349, in train
loss = self.model.forward_loss(batch_step)
File "/home/ubuntu/anaconda3/lib/python3.7/site-packages/flair/models/sequence_tagger_model.py", line 508, in forward_loss
features = self.forward(data_points)
File "/home/ubuntu/anaconda3/lib/python3.7/site-packages/flair/models/sequence_tagger_model.py", line 541, in forward
self.embeddings.embedding_length,
RuntimeError: shape '[32, 52, 768]' is invalid for input of size 1272576
So it seems indeed that pytorch has some issues using multiprocessing on Windows and I didn't find how to fix it : the if protection didn't change anything. On Ubuntu 16.04 however things are a little better but still we have the "shape" error. I've also tried to use the GPU and load the dataset in memory by changing this :
corpus = ColumnCorpus(data_folder =data_folder,
column_format=columns,
train_file='train.txt',
test_file='test.txt',
in_memory=True)
and this :
trainer.train('example-ner-camtest',
learning_rate=0.1,
mini_batch_size=32,
max_epochs=150,
embeddings_storage_mode="gpu",
monitor_test=True,
checkpoint=True)
in the previous code. I choosed a Deep Learning AMI (Ubuntu 16.04) Version 30.0 AMI with 8 vCPU and a Tesla T4 GPU (with 16 GB memory) : a g4dn.2xlarge instance. So I think here the resources are not the problem. Everything was forking fine but then my dataset was too big for the memory of the Tesla T4 so I've gotten a memory error. I downsampled my corpus :
corpus = corpus.downsample(0.5)
and then I get this error :
2020-07-05 15:07:01,736 ----------------------------------------------------------------------------------------------------
2020-07-05 15:07:01,736 Corpus: "Corpus: 95790 train + 10644 dev + 26742 test sentences"
2020-07-05 15:07:01,736 ----------------------------------------------------------------------------------------------------
2020-07-05 15:07:01,736 Parameters:
2020-07-05 15:07:01,736 - learning_rate: "0.1"
2020-07-05 15:07:01,736 - mini_batch_size: "32"
2020-07-05 15:07:01,736 - patience: "3"
2020-07-05 15:07:01,736 - anneal_factor: "0.5"
2020-07-05 15:07:01,736 - max_epochs: "150"
2020-07-05 15:07:01,736 - shuffle: "True"
2020-07-05 15:07:01,736 - train_with_dev: "False"
2020-07-05 15:07:01,736 - batch_growth_annealing: "False"
2020-07-05 15:07:01,736 ----------------------------------------------------------------------------------------------------
2020-07-05 15:07:01,736 Model training base path: "example-ner-camtest"
2020-07-05 15:07:01,736 ----------------------------------------------------------------------------------------------------
2020-07-05 15:07:01,736 Device: cuda:0
2020-07-05 15:07:01,736 ----------------------------------------------------------------------------------------------------
2020-07-05 15:07:01,736 Embeddings storage mode: gpu
2020-07-05 15:07:01,737 ----------------------------------------------------------------------------------------------------
2020-07-05 15:10:51,866 Tokenization MISMATCH in sentence 'V354 Cephei , RW Cephei sont d' autres supergéantes rouge .'
2020-07-05 15:10:51,866 Last matched: 'Token: 6 '
2020-07-05 15:10:51,866 Last sentence: 'Token: 12 .'
2020-07-05 15:10:51,866 subtokenized: '['<s>', '▁V', '35', '4', '▁Ce', 'phe', 'i', '▁', ',', '▁R', 'W', '▁Ce', 'phe', 'i', '▁sont', '▁d', "'", '▁autres', '▁super', 'gé', 'antes', '▁rouge', '▁', '.', '</s>']'
Traceback (most recent call last):
File "gpu.py", line 64, in <module>
trainCamembert()
File "gpu.py", line 61, in trainCamembert
checkpoint=True)
File "/home/ubuntu/anaconda3/lib/python3.7/site-packages/flair/trainers/trainer.py", line 349, in train
loss = self.model.forward_loss(batch_step)
File "/home/ubuntu/anaconda3/lib/python3.7/site-packages/flair/models/sequence_tagger_model.py", line 508, in forward_loss
features = self.forward(data_points)
File "/home/ubuntu/anaconda3/lib/python3.7/site-packages/flair/models/sequence_tagger_model.py", line 541, in forward
self.embeddings.embedding_length,
RuntimeError: shape '[32, 65, 768]' is invalid for input of size 1592064
I think the important part in this is :
2020-07-05 15:10:51,866 Tokenization MISMATCH in sentence 'V354 Cephei , RW Cephei sont d' autres supergéantes rouge .'
2020-07-05 15:10:51,866 Last matched: 'Token: 6 '
2020-07-05 15:10:51,866 Last sentence: 'Token: 12 .'
2020-07-05 15:10:51,866 subtokenized: '['<s>', '▁V', '35', '4', '▁Ce', 'phe', 'i', '▁', ',', '▁R', 'W', '▁Ce', 'phe', 'i', '▁sont', '▁d', "'", '▁autres', '▁super', 'gé', 'antes', '▁rouge', '▁', '.', '</s>']'
It seems the shape error occured because flair has hard time tokenizing the sentence : 'V354 Cephei , RW Cephei sont d' autres supergéantes rouge .'. What can I actually do for that ? The sentence don't have any weird character so I don't understand why flair raises an error. You may noticed that the very same sentence, made the program stops in the version of my code where I don't use gpu o load the dataset in memory. I guess the real issue with the multiprocessing library is that it doesn't work really well on Windows even if the if protection. Also I've noticed those "__" in the list of words :
2020-07-05 15:10:51,866 subtokenized: '['<s>', '▁V', '35', '4', '▁Ce', 'phe', 'i', '▁', ',', '▁R', 'W', '▁Ce', 'phe', 'i', '▁sont', '▁d', "'", '▁autres', '▁super', 'gé', 'antes', '▁rouge', '▁', '.', '</s>']'
Is it normal or is it an encoding problem ? Actually in the terminal those "__" look like :

So it seems that they aren't normal characters. But in my train.txt the sentence looks like this :
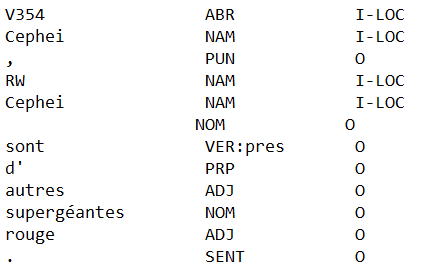
Some white space in it is labelled as a noun ("nom" in french) and has the tag O. But everything else is ok with this sentence.
Nighthyst
on 5 Jul 2020
Hello @Nighthyst the embeddings_storage_mode should almost never be 'gpu' since this will cause the trainer to try to keep everything in CUDA memory which is nearly never enough. In most cases, it should be left as 'cpu' default. The GPU will be utilized anyway - Flair checks if there is a GPU and if so, it will use it automatically, so you don't have to change any settings for that.
The second error, the token mismatch in the sentence, is I believe fixed in master branch. I just tried the sentence and it works. I am preparing release 0.5.1 now so the fix will then be installable through pip.
alanakbik
on 5 Jul 2020
@alanakbik I updated flair with master and now it seems to works better on both Ubuntu and Windows. I ran other tests with the previous code but I downsampled the dataset to only train and test on 10% of the complete dataset. For this I use the following line :
corpus = corpus.downsample(0.1)
right after loading the dataset.
- Ubuntu
You're right for the GPU memory, my full dataset was indeed to big for the Tesla T4 GPU : only 10% of the dataset used 3.7 GB of CUDA memory. In this case the program was working well and the training went on without issues.
- Windows
I updated Flair with master on Windows too. Same dataset (10%) and using the gpu storage mode, I can complete 1 epoch but then everything seems to stop after some warnings :
2020-07-06 06:56:47,366 ----------------------------------------------------------------------------------------------------
2020-07-06 06:56:47,366 Corpus: "Corpus: 19158 train + 2129 dev + 5348 test sentences"
2020-07-06 06:56:47,382 ----------------------------------------------------------------------------------------------------
2020-07-06 06:56:47,382 Parameters:
2020-07-06 06:56:47,382 - learning_rate: "0.1"
2020-07-06 06:56:47,382 - mini_batch_size: "32"
2020-07-06 06:56:47,382 - patience: "3"
2020-07-06 06:56:47,382 - anneal_factor: "0.5"
2020-07-06 06:56:47,382 - max_epochs: "150"
2020-07-06 06:56:47,382 - shuffle: "True"
2020-07-06 06:56:47,382 - train_with_dev: "False"
2020-07-06 06:56:47,382 - batch_growth_annealing: "False"
2020-07-06 06:56:47,382 ----------------------------------------------------------------------------------------------------
2020-07-06 06:56:47,382 Model training base path: "example-ner-camtest"
2020-07-06 06:56:47,382 ----------------------------------------------------------------------------------------------------
2020-07-06 06:56:47,382 Device: cuda:0
2020-07-06 06:56:47,382 ----------------------------------------------------------------------------------------------------
2020-07-06 06:56:47,382 Embeddings storage mode: gpu
2020-07-06 06:56:47,398 ----------------------------------------------------------------------------------------------------
2020-07-06 06:56:49.439387: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 06:56:53.940229: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 06:56:58.433400: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 06:57:02.960107: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 06:57:07.554057: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 06:57:12.202747: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 07:00:35,809 epoch 1 - iter 59/599 - loss 14.29446254 - samples/sec: 9.43
2020-07-06 07:04:32,481 epoch 1 - iter 118/599 - loss 10.00509571 - samples/sec: 8.81
2020-07-06 07:08:50,505 epoch 1 - iter 177/599 - loss 7.98958238 - samples/sec: 8.21
2020-07-06 07:13:09,823 epoch 1 - iter 236/599 - loss 6.90039632 - samples/sec: 8.18
2020-07-06 07:17:29,297 epoch 1 - iter 295/599 - loss 6.10292543 - samples/sec: 8.18
2020-07-06 07:21:53,587 epoch 1 - iter 354/599 - loss 5.57438329 - samples/sec: 8.02
2020-07-06 07:26:20,227 epoch 1 - iter 413/599 - loss 5.15239036 - samples/sec: 7.95
2020-07-06 07:31:12,152 epoch 1 - iter 472/599 - loss 4.82489295 - samples/sec: 7.19
2020-07-06 07:36:01,424 epoch 1 - iter 531/599 - loss 4.56669221 - samples/sec: 7.34
2020-07-06 07:41:14,597 epoch 1 - iter 590/599 - loss 4.34983164 - samples/sec: 6.73
2020-07-06 07:42:25,108 ----------------------------------------------------------------------------------------------------
2020-07-06 07:42:25,108 EPOCH 1 done: loss 4.3177 - lr 0.1000000
2020-07-06 07:42:27.906356: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 07:42:33.879459: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 07:42:39.971859: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 07:42:45.456795: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 07:42:50.692354: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 07:42:55.833521: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 07:47:14,632 DEV : loss 1.482055902481079 - score 0.8174
2020-07-06 07:47:18.626319: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 07:47:24.143144: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 07:47:29.645073: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 07:47:35.219993: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 07:47:40.996689: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 07:47:46.320306: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
On Ubuntu, epoch 2 started quickly after the results of epoch 1. On Windows however, even after 20 minutes of the above logs in the terminal, nothing happened so I stopped the program.
On my Windows I have a NVIDIA GeForce GTX 1050 Ti GDDR5 so only 4 GB memory but only 1.4 GB were used after epoch 1 was done. Then I tried to choose the cpu storage mode for embeddings and I got the same problem :
2020-07-06 08:03:31,858 ----------------------------------------------------------------------------------------------------
2020-07-06 08:03:31,858 Corpus: "Corpus: 19158 train + 2129 dev + 5348 test sentences"
2020-07-06 08:03:31,858 ----------------------------------------------------------------------------------------------------
2020-07-06 08:03:31,858 Parameters:
2020-07-06 08:03:31,858 - learning_rate: "0.1"
2020-07-06 08:03:31,858 - mini_batch_size: "32"
2020-07-06 08:03:31,858 - patience: "3"
2020-07-06 08:03:31,873 - anneal_factor: "0.5"
2020-07-06 08:03:31,873 - max_epochs: "150"
2020-07-06 08:03:31,873 - shuffle: "True"
2020-07-06 08:03:31,873 - train_with_dev: "False"
2020-07-06 08:03:31,873 - batch_growth_annealing: "False"
2020-07-06 08:03:31,873 ----------------------------------------------------------------------------------------------------
2020-07-06 08:03:31,873 Model training base path: "example-ner-camtest"
2020-07-06 08:03:31,873 ----------------------------------------------------------------------------------------------------
2020-07-06 08:03:31,873 Device: cuda:0
2020-07-06 08:03:31,873 ----------------------------------------------------------------------------------------------------
2020-07-06 08:03:31,873 Embeddings storage mode: cpu
2020-07-06 08:03:31,873 ----------------------------------------------------------------------------------------------------
2020-07-06 08:03:34.239527: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 08:03:39.223847: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 08:03:43.920580: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 08:03:48.714628: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 08:03:53.552611: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 08:03:58.479234: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 08:07:59,240 epoch 1 - iter 59/599 - loss 13.20852605 - samples/sec: 7.99
2020-07-06 08:12:23,636 epoch 1 - iter 118/599 - loss 9.22701921 - samples/sec: 7.83
2020-07-06 08:17:03,958 epoch 1 - iter 177/599 - loss 7.40224483 - samples/sec: 7.55
2020-07-06 08:21:45,898 epoch 1 - iter 236/599 - loss 6.42094271 - samples/sec: 7.49
2020-07-06 08:26:21,815 epoch 1 - iter 295/599 - loss 5.74338580 - samples/sec: 7.70
2020-07-06 08:31:03,981 epoch 1 - iter 354/599 - loss 5.26071296 - samples/sec: 7.50
2020-07-06 08:35:47,350 epoch 1 - iter 413/599 - loss 4.86944430 - samples/sec: 7.49
2020-07-06 08:40:38,168 epoch 1 - iter 472/599 - loss 4.59605295 - samples/sec: 7.25
2020-07-06 08:45:19,628 epoch 1 - iter 531/599 - loss 4.35149271 - samples/sec: 7.51
2020-07-06 08:50:37,122 epoch 1 - iter 590/599 - loss 4.13904264 - samples/sec: 6.57
2020-07-06 08:51:57,689 ----------------------------------------------------------------------------------------------------
2020-07-06 08:51:57,689 EPOCH 1 done: loss 4.1086 - lr 0.1000000
2020-07-06 08:52:00.740026: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 08:52:07.278569: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 08:52:13.557135: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 08:52:20.282821: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 08:52:27.775277: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
2020-07-06 08:52:34.669415: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll
unable to import 'smart_open.gcs', disabling that module
It hangs forever after the first epoch. Windows doesn't work well but Ubuntu is OK. I have just a question regarding CPU usage : is it normal that during the training Flair sticks to using only 1 CPU ? I had 1 CPU at 100% utilization and the others at 0% : is there any way to take advantage of more if not all CPUs ?
Nighthyst
on 6 Jul 2020
Hi, I am getting the same "tokenization mismatch" error again as in my original post. I made sure to upgrade flair so I use the latest version, but that did not help. I still get the exact same error.
AylaRT
on 25 Dec 2020
Could you paste a minimal code example to reproduce?
alanakbik
on 4 Jan 2021
It is the exact same error as reported in the original message, so that information is identical. The cade is basically the one from the flairnlp examples. The script works perfectly, except for these specific characters:
So, I am able to run everything when I remove these characters from the corpus. It would simply be nice if it also worked with those characters (this is only a problem with Bert embeddings, not with flair embeddings).
AylaRT
on 4 Jan 2021
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
![stale[bot] picture](https://avatars.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 5 May 2021
stale[bot]
on 5 May 2021
Related issues
 aslicedbread
·
21Comments
aslicedbread
·
21Comments
 sp3234
·
26Comments
sp3234
·
26Comments
 mittalsuraj18
·
26Comments
Nighthyst
·
18Comments
mittalsuraj18
·
26Comments
Nighthyst
·
18Comments
 emrul
·
21Comments
emrul
·
21Comments