Thanks for a great framework,
- I'm train a ner model but it seem training speed to very slow. It about ~3 hours to done 1 epoch with mini_batch_size = 64.
- During model training, it use only 695MiB GPU RAM and < 6% GPU Compute and about 5 - 6GB CPU RAM.
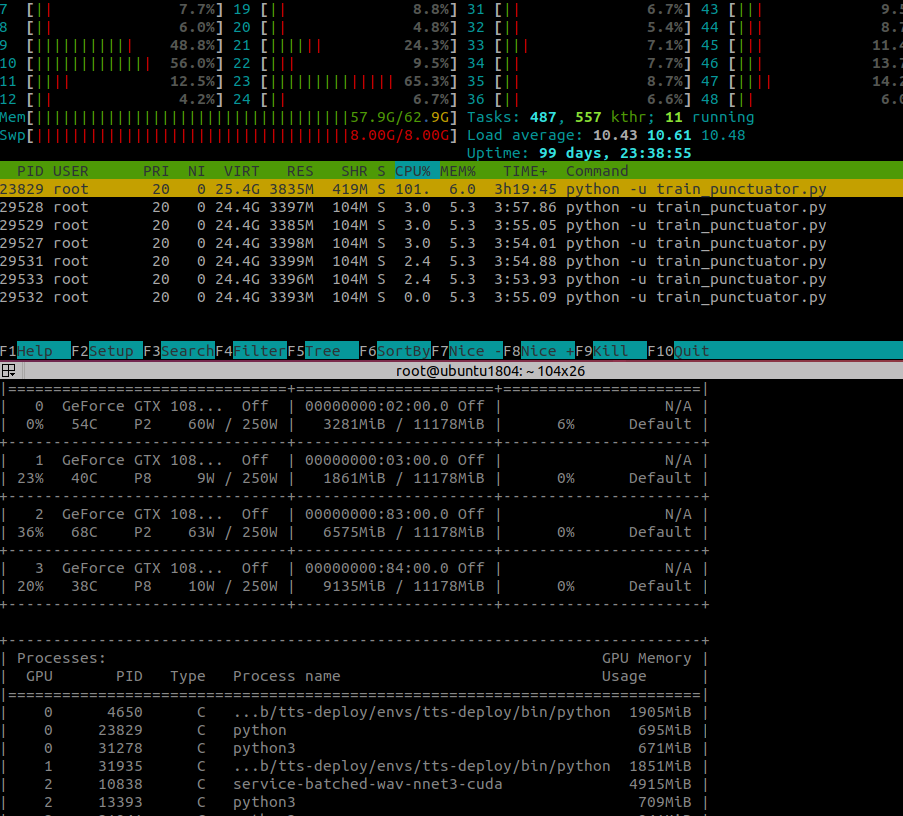
Training device info
- OS: Ubuntu 18.04
GPU: GTX 1080 Ti
Training configuration
Fasttext embedding, dim = 100
- Corpus: 2500000 train + 750000 dev + 750000 test
- Corpus mode: in_memory=False
- Embeddings storage mode: None
Training log
2020-05-27 15:39:00,529 Model: "SequenceTagger(
(embeddings): FastTextEmbeddings('embedding/news.prep.100.bin')
(word_dropout): WordDropout(p=0.05)
(locked_dropout): LockedDropout(p=0.5)
(embedding2nn): Linear(in_features=100, out_features=100, bias=True)
(rnn): LSTM(100, 256, batch_first=True, bidirectional=True)
(linear): Linear(in_features=512, out_features=6, bias=True)
(beta): 1.0
(weights): None
(weight_tensor) None
)"
2020-05-27 15:39:00,530 ----------------------------------------------------------------------------------------------------
2020-05-27 15:39:00,530 Corpus: "Corpus: 2500000 train + 750000 dev + 750000 test sentences"
2020-05-27 15:39:00,530 ----------------------------------------------------------------------------------------------------
2020-05-27 15:39:00,530 Parameters:
2020-05-27 15:39:00,530 - learning_rate: "0.1"
2020-05-27 15:39:00,530 - mini_batch_size: "64"
2020-05-27 15:39:00,530 - patience: "3"
2020-05-27 15:39:00,530 - anneal_factor: "0.5"
2020-05-27 15:39:00,530 - max_epochs: "150"
2020-05-27 15:39:00,530 - shuffle: "True"
2020-05-27 15:39:00,531 - train_with_dev: "False"
2020-05-27 15:39:00,531 - batch_growth_annealing: "False"
2020-05-27 15:39:00,531 ----------------------------------------------------------------------------------------------------
2020-05-27 15:39:00,531 Model training base path: "resources/punctuator-trainer_b64"
2020-05-27 15:39:00,531 ----------------------------------------------------------------------------------------------------
2020-05-27 15:39:00,531 Device: cuda:0
2020-05-27 15:39:00,531 ----------------------------------------------------------------------------------------------------
2020-05-27 15:39:00,531 Embeddings storage mode: None
2020-05-27 15:39:00,532 ----------------------------------------------------------------------------------------------------
/pytorch/torch/csrc/utils/tensor_numpy.cpp:141: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program.
2020-05-27 15:59:45,014 epoch 1 - iter 3906/39063 - loss 7.44133509 - samples/sec: 228.62
2020-05-27 16:20:18,614 epoch 1 - iter 7812/39063 - loss 7.22013033 - samples/sec: 230.63
2020-05-27 16:41:12,607 epoch 1 - iter 11718/39063 - loss 7.05320136 - samples/sec: 226.84
2020-05-27 17:02:01,065 epoch 1 - iter 15624/39063 - loss 6.91849714 - samples/sec: 227.89
2020-05-27 17:22:56,335 epoch 1 - iter 19530/39063 - loss 6.80771093 - samples/sec: 226.83
Question
- Why my model training with low speed?
 nguyenvanhieuvn
nguyenvanhieuvn
All 6 comments
Are you using Flair 0.5 (was just released)? Could you try to use WordEmbeddings instead of FastTextEmbeddings? Just to see if the problem is in the embeddings class.
Depending on your task you can also deactivate the CRF by doing use_crf=False when initializing the SequenceTagger which could speed things up.
 alanakbik
on 27 May 2020
alanakbik
on 27 May 2020
Are you using Flair 0.5
No, my installed flair version is 0.4.5.
deactivate the CRF
Thanks, I will deactivate it, and continue see what change to report!
nguyenvanhieuvn
on 27 May 2020
With the same as mention above, just change by convert fasttext embedding file to gensim format and change FasttextEmbeddings to WordEmbedings; and set use_crf=False
I got training speed there's no improment
Training logs
2020-05-27 21:20:48,512 Model: "SequenceTagger(
(embeddings): WordEmbeddings('embedding/news.prep.100.gensim')
(word_dropout): WordDropout(p=0.05)
(locked_dropout): LockedDropout(p=0.5)
(embedding2nn): Linear(in_features=100, out_features=100, bias=True)
(rnn): LSTM(100, 256, batch_first=True, bidirectional=True)
(linear): Linear(in_features=512, out_features=6, bias=True)
(beta): 1.0
(weights): None
(weight_tensor) None
)"
2020-05-27 21:20:48,512 ----------------------------------------------------------------------------------------------------
2020-05-27 21:20:48,512 Corpus: "Corpus: 2500000 train + 750000 dev + 750000 test sentences"
2020-05-27 21:20:48,512 ----------------------------------------------------------------------------------------------------
2020-05-27 21:20:48,512 Parameters:
2020-05-27 21:20:48,512 - learning_rate: "0.1"
2020-05-27 21:20:48,513 - mini_batch_size: "64"
2020-05-27 21:20:48,513 - patience: "3"
2020-05-27 21:20:48,513 - anneal_factor: "0.5"
2020-05-27 21:20:48,513 - max_epochs: "150"
2020-05-27 21:20:48,513 - shuffle: "True"
2020-05-27 21:20:48,513 - train_with_dev: "False"
2020-05-27 21:20:48,513 - batch_growth_annealing: "False"
2020-05-27 21:20:48,513 ----------------------------------------------------------------------------------------------------
2020-05-27 21:20:48,513 Model training base path: "resources/punctuator-trainer_b64"
2020-05-27 21:20:48,514 ----------------------------------------------------------------------------------------------------
2020-05-27 21:20:48,514 Device: cuda:0
2020-05-27 21:20:48,514 ----------------------------------------------------------------------------------------------------
2020-05-27 21:20:48,514 Embeddings storage mode: None
2020-05-27 21:20:48,515 ----------------------------------------------------------------------------------------------------
/pytorch/torch/csrc/utils/tensor_numpy.cpp:141: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program.
2020-05-27 21:42:00,925 epoch 1 - iter 3906/39063 - loss 7.45850880 - samples/sec: 226.78
2020-05-27 22:02:58,314 epoch 1 - iter 7812/39063 - loss 7.25216707 - samples/sec: 228.46
2020-05-27 22:23:50,612 epoch 1 - iter 11718/39063 - loss 7.07625870 - samples/sec: 229.25
2020-05-27 22:44:53,955 epoch 1 - iter 15624/39063 - loss 6.93890443 - samples/sec: 227.40
2020-05-27 23:05:54,430 epoch 1 - iter 19530/39063 - loss 6.82580035 - samples/sec: 228.03
2020-05-27 23:26:53,252 epoch 1 - iter 23436/39063 - loss 6.73009149 - samples/sec: 228.13
2020-05-27 23:48:01,748 epoch 1 - iter 27342/39063 - loss 6.64566891 - samples/sec: 226.41
2020-05-28 00:09:12,096 epoch 1 - iter 31248/39063 - loss 6.57423519 - samples/sec: 226.52
2020-05-28 00:30:18,761 epoch 1 - iter 35154/39063 - loss 6.50983181 - samples/sec: 226.76
2020-05-28 00:51:26,972 epoch 1 - iter 39060/39063 - loss 6.45359384 - samples/sec: 226.80
2020-05-28 00:51:27,875 ----------------------------------------------------------------------------------------------------
2020-05-28 00:51:27,876 EPOCH 1 done: loss 6.4536 - lr 0.1000
2020-05-28 01:43:25,573 DEV : loss 4.897789001464844 - score 0.3984
2020-05-28 01:49:57,387 BAD EPOCHS (no improvement): 0
2020-05-28 01:49:58,744 ----------------------------------------------------------------------------------------------------
2020-05-28 02:11:21,902 epoch 2 - iter 3906/39063 - loss 5.90120254 - samples/sec: 226.09
2020-05-28 02:32:41,423 epoch 2 - iter 7812/39063 - loss 5.88321241 - samples/sec: 225.37
2020-05-28 02:53:58,791 epoch 2 - iter 11718/39063 - loss 5.85995482 - samples/sec: 226.30
2020-05-28 03:15:17,369 epoch 2 - iter 15624/39063 - loss 5.84138609 - samples/sec: 227.36
2020-05-28 03:36:34,961 epoch 2 - iter 19530/39063 - loss 5.82352923 - samples/sec: 227.40
2020-05-28 03:57:52,460 epoch 2 - iter 23436/39063 - loss 5.80817408 - samples/sec: 227.48
2020-05-28 04:19:15,571 epoch 2 - iter 27342/39063 - loss 5.79589227 - samples/sec: 226.64
2020-05-28 04:40:29,996 epoch 2 - iter 31248/39063 - loss 5.78262263 - samples/sec: 228.01
2020-05-28 05:01:57,090 epoch 2 - iter 35154/39063 - loss 5.76937894 - samples/sec: 225.64
2020-05-28 05:23:25,372 epoch 2 - iter 39060/39063 - loss 5.75863678 - samples/sec: 225.85
2020-05-28 05:23:26,588 ----------------------------------------------------------------------------------------------------
2020-05-28 05:23:26,589 EPOCH 2 done: loss 5.7586 - lr 0.1000
2020-05-28 06:14:57,512 DEV : loss 4.6971049308776855 - score 0.3816
2020-05-28 06:21:30,124 BAD EPOCHS (no improvement): 1
Very strange that these setting did not make a difference. At least use_crf=False should increase GPU usage (we get a lot more when we train on machines like this).
I think the problem is the huge size of the dataset and the fact that you do in_memory=False. In the current implementation, if not in memory we open the file, traverse it until we find the sentence and then read it into an object. We repeat this for each sentence, so if the file is huge, traversing it takes a long while. Normally this is not a problem because we do it asynchronously, but in your case even with 6 workers this will be a bottleneck. So disk reads are the likely bottleneck here.
A quick fix would be to increase the number of workers by passing num_workers=12 or so, but that of course requires you to have so many CPU threads. A better fix requires us to refactor this part of the code so that fewer disk reads are required.
alanakbik
on 28 May 2020
My machine have lot of CPU,
I'll try to increase the number of workers to see what change,
Thanks for your help.
nguyenvanhieuvn
on 28 May 2020
change number of worker not improve training speed.
I already implement my own dataloader by split training file to multiple small file so i can load each part in memory.
Thank flair team,
nguyenvanhieuvn
on 29 May 2020
Related issues
 jewl123
·
3Comments
jewl123
·
3Comments
 Rahulvks
·
3Comments
Rahulvks
·
3Comments
 isanvicente
·
3Comments
isanvicente
·
3Comments
 mittalsuraj18
·
3Comments
mittalsuraj18
·
3Comments
 shoarora
·
3Comments
shoarora
·
3Comments