Flair: AttributeError when finetuned bert model for downstream task is used
Describe the bug
I got the error called AttributeError:'BertTokenizer' object has no attribute 'model_max_length' when i used model.predict(sentence)
To Reproduce
I didn't get any errors when I trained. The script for training model is
``
from flair.data import Corpus
from flair.datasets import ColumnCorpus
from flair.embeddings import TransformerWordEmbeddings, TokenEmbeddings, StackedEmbeddings, BertEmbeddings, CharacterEmbeddings, BytePairEmbeddings, WordEmbeddings
from flair.visual.training_curves import Plotter
from flair.models import SequenceTagger
from flair.trainers import ModelTrainer
from typing import List
from torch.optim.adam import Adam
import sys
import flair, torch
flair.device = torch.device('cuda:0')
columns = {0: 'text', 1: 'ner'}
data_folder = './data/Model_Trainer_Data'
corpus: Corpus = ColumnCorpus(data_folder, columns,train_file= sys.argv[1] , dev_file=sys.argv[3], test_file= sys.argv[4], in_memory=False)
tag_type = 'ner'
tag_dictionary = corpus.make_tag_dictionary(tag_type=tag_type)
embeddings = TransformerWordEmbeddings(
'bert-base-multilingual-cased', # which transformer model
layers="-1", # which layers (here: only last layer when fine-tuning)
pooling_operation='first_last', # how to pool over split tokens
fine_tune=True, # whether or not to fine-tune
)
tagger: SequenceTagger = SequenceTagger(
hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type=tag_type,
use_crf=False,
use_rnn=False,
)
trainer = ModelTrainer(tagger, corpus, optimizer=torch.optim.Adam)
trainer.train('./results/'+ sys.argv[2],
learning_rate=3e-5,
embeddings_storage_mode = 'gpu',
mini_batch_chunk_size=2,
max_epochs=4,
train_with_dev=False,
checkpoint=True)
plotter = Plotter()
plotter.plot_weights('./results/'+ sys.argv[2]+'/weights.txt')
``
The prediction script is below.

Expected behavior
To get no errors in predicting with model
Screenshots
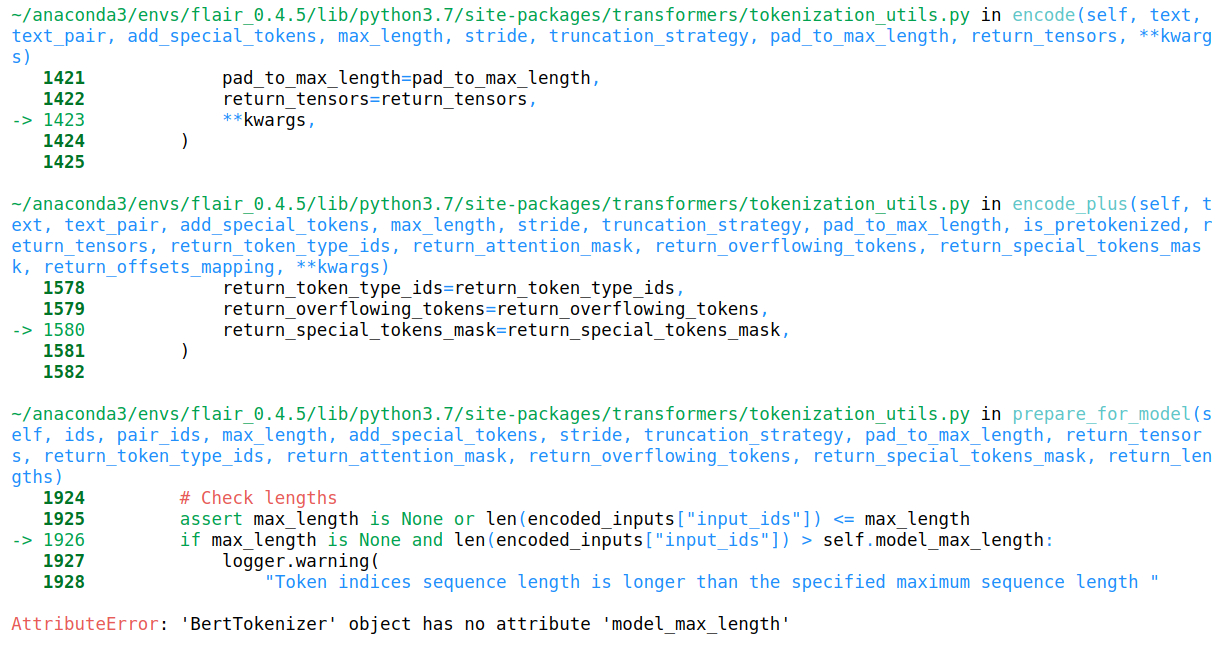
Environment (please complete the following information):
- OS [Linux mint 19.3]:
- Version [flair current lastest branch]:
 Michael95-m
Michael95-m
All 10 comments
Thanks for reporting this. I can reproduce this error if I train the model on one machine and then predict on another. Is this the same for you? If I train and predict on the same machine, it seems to work.
 alanakbik
on 14 May 2020
alanakbik
on 14 May 2020
I've merged a PR that fixes this for me. Can you update and try again?
alanakbik
on 14 May 2020
@alanakbik yes bro. I trained and predicted on different machines.
Michael95-m
on 14 May 2020
I still got these two errors.

This is another errors.
~/Research/flair/utils_flair/utils/word_break_flair.py in word_break_only(wb_model_path, sent_data)
70
71 def word_break_only(wb_model_path, sent_data):
---> 72 wb_model = SequenceTagger.load(wb_model_path)
73 if type(sent_data) == str:
74 wb_str = word_break(sent_data, wb_model)
~/Research/flair/flair/nn.py in load(cls, model)
84 # see https://github.com/zalandoresearch/flair/issues/351
85 f = file_utils.load_big_file(str(model_file))
---> 86 state = torch.load(f, map_location=flair.device)
87
88 model = cls._init_model_with_state_dict(state)
~/anaconda3/envs/flair_0.4.5/lib/python3.7/site-packages/torch/serialization.py in load(f, map_location, pickle_module, **pickle_load_args)
591 return torch.jit.load(f)
592 return _load(opened_zipfile, map_location, pickle_module, **pickle_load_args)
--> 593 return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
594
595
~/anaconda3/envs/flair_0.4.5/lib/python3.7/site-packages/torch/serialization.py in _legacy_load(f, map_location, pickle_module, **pickle_load_args)
771 unpickler = pickle_module.Unpickler(f, **pickle_load_args)
772 unpickler.persistent_load = persistent_load
--> 773 result = unpickler.load()
774
775 deserialized_storage_keys = pickle_module.load(f, **pickle_load_args)
~/Research/flair/flair/embeddings/token.py in __setstate__(self, d)
1062 # reload tokenizer to get around serialization issues
1063 model_name = self.name.split('transformer-word-')[-1]
-> 1064 self.tokenizer = AutoTokenizer.from_pretrained(model_name)
1065
1066
~/anaconda3/envs/flair_0.4.5/lib/python3.7/site-packages/transformers/tokenization_auto.py in from_pretrained(cls, pretrained_model_name_or_path, *inputs, **kwargs)
187 config = kwargs.pop("config", None)
188 if not isinstance(config, PretrainedConfig):
--> 189 config = AutoConfig.from_pretrained(pretrained_model_name_or_path, **kwargs)
190
191 if "bert-base-japanese" in pretrained_model_name_or_path:
~/anaconda3/envs/flair_0.4.5/lib/python3.7/site-packages/transformers/configuration_auto.py in from_pretrained(cls, pretrained_model_name_or_path, **kwargs)
190 """
191 config_dict, _ = PretrainedConfig.get_config_dict(
--> 192 pretrained_model_name_or_path, pretrained_config_archive_map=ALL_PRETRAINED_CONFIG_ARCHIVE_MAP, **kwargs
193 )
194
~/anaconda3/envs/flair_0.4.5/lib/python3.7/site-packages/transformers/configuration_utils.py in get_config_dict(cls, pretrained_model_name_or_path, pretrained_config_archive_map, **kwargs)
247 proxies=proxies,
248 resume_download=resume_download,
--> 249 local_files_only=local_files_only,
250 )
251 # Load config dict
~/anaconda3/envs/flair_0.4.5/lib/python3.7/site-packages/transformers/file_utils.py in cached_path(url_or_filename, cache_dir, force_download, proxies, resume_download, user_agent, extract_compressed_file, force_extract, local_files_only)
265 resume_download=resume_download,
266 user_agent=user_agent,
--> 267 local_files_only=local_files_only,
268 )
269 elif os.path.exists(url_or_filename):
~/anaconda3/envs/flair_0.4.5/lib/python3.7/site-packages/transformers/file_utils.py in get_from_cache(url, cache_dir, force_download, proxies, etag_timeout, resume_download, user_agent, local_files_only)
444 logger.info("%s not found in cache or force_download set to True, downloading to %s", url, temp_file.name)
445
--> 446 http_get(url, temp_file, proxies=proxies, resume_size=resume_size, user_agent=user_agent)
447
448 logger.info("storing %s in cache at %s", url, cache_path)
~/anaconda3/envs/flair_0.4.5/lib/python3.7/site-packages/transformers/file_utils.py in http_get(url, temp_file, proxies, resume_size, user_agent)
335 initial=resume_size,
336 desc="Downloading",
--> 337 disable=bool(logger.getEffectiveLevel() == logging.NOTSET),
338 )
339 for chunk in response.iter_content(chunk_size=1024):
~/anaconda3/envs/flair_0.4.5/lib/python3.7/site-packages/tqdm/notebook.py in __init__(self, *args, **kwargs)
207 total = self.total * unit_scale if self.total else self.total
208 self.container = self.status_printer(
--> 209 self.fp, total, self.desc, self.ncols)
210 self.sp = self.display
211
~/anaconda3/envs/flair_0.4.5/lib/python3.7/site-packages/tqdm/notebook.py in status_printer(_, total, desc, ncols)
102 # #187 #451 #558
103 raise ImportError(
--> 104 "FloatProgress not found. Please update jupyter and ipywidgets."
105 " See https://ipywidgets.readthedocs.io/en/stable"
106 "/user_install.html")
ImportError: FloatProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
I am not sure this is because of new update but the older model(not transformer model.. I mean bilstm plus crf) works just fine and only transformer model got these errors.
Michael95-m
on 14 May 2020
Can you share your model to reproduce?
alanakbik
on 14 May 2020
I used the same previous model that got the errors. I didn't retrain it. Should I need to retrain the model?
Michael95-m
on 14 May 2020
The same model should work.
alanakbik
on 14 May 2020
I think my pytorch version got problem. Which torch version did u use @alanakbik ??
Michael95-m
on 14 May 2020
I'm using 1.4.0
alanakbik
on 14 May 2020
@alanakbik , it works when running in python script but doesn't work and get errors when running in jupyter notebook. I think my jupyter notebook causes the problems. The updated code works!!! Thank you.
Michael95-m
on 14 May 2020
Related issues
 Aditya715
·
3Comments
Aditya715
·
3Comments
 ChessMateK
·
3Comments
ChessMateK
·
3Comments
 ciaochiaociao
·
3Comments
ciaochiaociao
·
3Comments
 davidsbatista
·
3Comments
davidsbatista
·
3Comments
 Y4rd13
·
3Comments
Y4rd13
·
3Comments
Most helpful comment
@alanakbik , it works when running in python script but doesn't work and get errors when running in jupyter notebook. I think my jupyter notebook causes the problems. The updated code works!!! Thank you.