Flair: Can't use trained flair embedding
Hello!
I've trained flair embedding for russian language like here (with generation of dictionary): https://github.com/flairNLP/flair/blob/master/resources/docs/TUTORIAL_9_TRAINING_LM_EMBEDDINGS.md
I have such dir structure:
corpus/train/train.txt
corpus/test.txt
corpus/valid.txt
In each file there is usual russian text like in books.
When I run training with the embedding I get an error RuntimeError: shape '[48, 1312, 128]' is invalid for input of size 11770128:
2020-03-19 13:41:14,935 ----------------------------------------------------------------------------------------------------
2020-03-19 13:41:14,937 Model: "SequenceTagger(
(embeddings): FlairEmbeddings(
(lm): LanguageModel(
(drop): Dropout(p=0.1, inplace=False)
(encoder): Embedding(144, 100)
(rnn): LSTM(100, 128)
(decoder): Linear(in_features=128, out_features=144, bias=True)
)
)
(dropout): Dropout(p=0.19832467649524788, inplace=False)
(word_dropout): WordDropout(p=0.05)
(locked_dropout): LockedDropout(p=0.5)
(embedding2nn): Linear(in_features=128, out_features=128, bias=True)
(rnn): LSTM(128, 512, num_layers=2, batch_first=True, dropout=0.5, bidirectional=True)
(linear): Linear(in_features=1024, out_features=24, bias=True)
(beta): 1.0
(weights): None
(weight_tensor) None
)"
2020-03-19 13:41:14,940 ----------------------------------------------------------------------------------------------------
2020-03-19 13:41:14,941 Corpus: "Corpus: 739 train + 246 dev + 246 test sentences"
2020-03-19 13:41:14,943 ----------------------------------------------------------------------------------------------------
2020-03-19 13:41:14,944 Parameters:
2020-03-19 13:41:14,946 - learning_rate: "0.15"
2020-03-19 13:41:14,947 - mini_batch_size: "48"
2020-03-19 13:41:14,948 - patience: "3"
2020-03-19 13:41:14,950 - anneal_factor: "0.5"
2020-03-19 13:41:14,951 - max_epochs: "150"
2020-03-19 13:41:14,952 - shuffle: "True"
2020-03-19 13:41:14,953 - train_with_dev: "False"
2020-03-19 13:41:14,955 - batch_growth_annealing: "False"
2020-03-19 13:41:14,956 ----------------------------------------------------------------------------------------------------
2020-03-19 13:41:14,957 Model training base path: "training"
2020-03-19 13:41:14,958 ----------------------------------------------------------------------------------------------------
2020-03-19 13:41:14,959 Device: cuda:0
2020-03-19 13:41:14,960 ----------------------------------------------------------------------------------------------------
2020-03-19 13:41:14,961 Embeddings storage mode: gpu
2020-03-19 13:41:14,970 ----------------------------------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
4 learning_rate=0.15,
5 mini_batch_size=48,
----> 6 max_epochs=150)
/opt/conda/lib/python3.7/site-packages/flair/trainers/trainer.py in train(self, base_path, learning_rate, mini_batch_size, mini_batch_chunk_size, max_epochs, anneal_factor, patience, min_learning_rate, train_with_dev, monitor_train, monitor_test, embeddings_storage_mode, checkpoint, save_final_model, anneal_with_restarts, batch_growth_annealing, shuffle, param_selection_mode, num_workers, sampler, use_amp, amp_opt_level, eval_on_train_fraction, eval_on_train_shuffle, **kwargs)
329
330 # forward pass
--> 331 loss = self.model.forward_loss(batch_step)
332
333 # Backward
/opt/conda/lib/python3.7/site-packages/flair/models/sequence_tagger_model.py in forward_loss(self, data_points, sort)
491 self, data_points: Union[List[Sentence], Sentence], sort=True
492 ) -> torch.tensor:
--> 493 features = self.forward(data_points)
494 return self._calculate_loss(features, data_points)
495
/opt/conda/lib/python3.7/site-packages/flair/models/sequence_tagger_model.py in forward(self, sentences)
524 len(sentences),
525 longest_token_sequence_in_batch,
--> 526 self.embeddings.embedding_length,
527 ]
528 )
RuntimeError: shape '[48, 1312, 128]' is invalid for input of size 11770128
So how to solve this?
Also the strange think is that during 10 epoches of training of flair embedding loss is always close to 2.3.
 dortonway
dortonway
All 4 comments
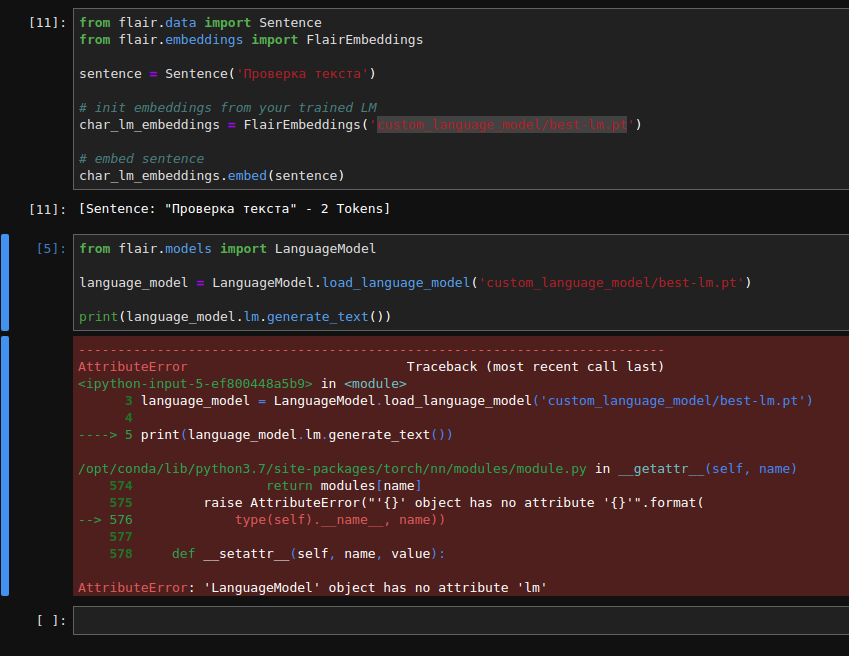
Hm that's strange. Maybe something went wrong during training of the language model. Could you run this:
language_model = LanguageModel.load_language_model('path/to/your/model.pt')
print(language_model.lm.generate_text())
Does the printed text look ok?
 alanakbik
on 19 Mar 2020
alanakbik
on 19 Mar 2020
@alanakbik, It seems like there is no 'lm' property:
But without 'lm' it generates meaningless text with correct, but mostly incorrect words:
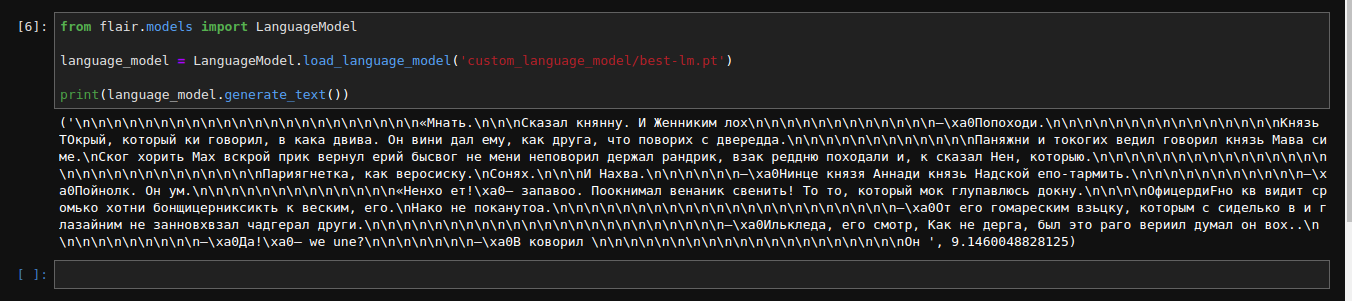
('\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n«Мнать.\n\n\nСказал княнну. И Женниким лох\n\n\n\n\n\n\n\n\n\n\n\n–\xa0Попоходи.\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nКнязь ТОкрый, который ки говорил, в кака двива. Он вини дал ему, как друга, что поворих с двередда.\n\n\n\n\n\n\n\n\n\n\n\nПаняжни и токогих ведил говорил князь Мава симе.\nСког хорить Мах вскрой прик вернул ерий бысвог не мени неповорил держал рандрик, взак реддню походали и, к сказал Нен, которыю.\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nПариягнетка, как веросиску.\nСонях.\n\n\nИ Нахва.\n\n\n\n\n\n–\xa0Нинце князя Аннади князь Надской епо-тармить.\n\n\n\n\n\n\n\n\n\n\n–\xa0Пойнолк. Он ум.\n\n\n\n\n\n\n\n\n\n\n\n\n«Ненхо ет!\xa0– запавоо. Поокнимал венаник свенить! То то, который мок глупавлюсь докну.\n\n\n\nОфицердиFно кв видит сромько хотни бонщицерниксикть к веским, его.\nНако не поканутоа.\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n–\xa0От его гомареским взьцку, которым с сиделько в и глазайним не занновхвзал чадгерал други.\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n–\xa0Илькледа, его смотр, Как не дерга, был это раго вериил думал он вох..\n\n\n\n\n\n\n\n\n\n–\xa0Да!\xa0– we une?\n\n\n\n\n\n\n–\xa0В коворил \n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nОн ', 9.1460048828125)
P.S. I pass embeddings to train the model like so:
tagger: SequenceTagger = SequenceTagger(dropout=0.1,
embeddings=FlairEmbeddings('custom_language_model/best-lm.pt'),
dortonway
on 19 Mar 2020
Ah yes sorry, the 'lm' was wrong. If it generates meaningless text this means that the language model did not learn well. But 128 states really is not much, so that could be the problem. Could you share the script you used to train the model?
alanakbik
on 19 Mar 2020
So training works now. I'm not sure what's caused it, may be kernel restart or params changing. Thanks for your help!
dortonway
on 24 Mar 2020
Related issues
 prematurelyoptimized
·
3Comments
prematurelyoptimized
·
3Comments
 jannenev
·
3Comments
jannenev
·
3Comments
 isanvicente
·
3Comments
isanvicente
·
3Comments
 frtacoa
·
3Comments
frtacoa
·
3Comments
 jewl123
·
3Comments
jewl123
·
3Comments