Flair: Training with FastTextEmbeddings - Incredibly large model size
Hi,
I try to train a PoS Tagger with FastText+subword (300 dimensional common crawl) using FastTextEmbeddings which was added a few hours ago. (Thank you!) But when 'best-model.pt' was saved after the first epoch, following error happened.
OSError: [Errno 28] No space left on device
This error happened because of incredibly large size of the model. So far, model saving stopped on 8.4 GB but I think it was still on progress. As a comparison, I also trained the models with different StackEmbeddings (i.e, BERT+Flair, existing FastText 'en-crawl' + Flair), but sizes were at most 1.5 GB. Seems like FastText+subword Embeddings take too much space on model.
Is there any way to solve this problem?
Note that my original dataset is not that big, only about 100k tokens in total. Thus, unique number of token should be much less.
Thank you.
 THEEJUNG
THEEJUNG
All 8 comments
Hello @THEEJUNG yeah this is a problem since the FastText models are incredibly large. I tried with a model for English downloaded from the FastText webpage that is 7 GB (which is huge) and saving worked because I had enough space, but the final model was over 4 GB. I am not sure if there is anything that can be done (apart from training smaller FT models) since embedding vectors are difficult to compress. @pranaychandekar any ideas?
Otherwise I can recommend using BytePairEmbeddings as a low memory alternative. You could use them either standalone or together with normal WordEmbeddings which is probably somewhat similar in performance but requires much less memory.
 alanakbik
on 16 Jul 2019
alanakbik
on 16 Jul 2019
I compared FastText and BPEmb for POS-tagging. BPEmb combined with character embeddings is a good method in many languages and probably the best you can currently do if resources (disk space / GPU RAM) are a concern:
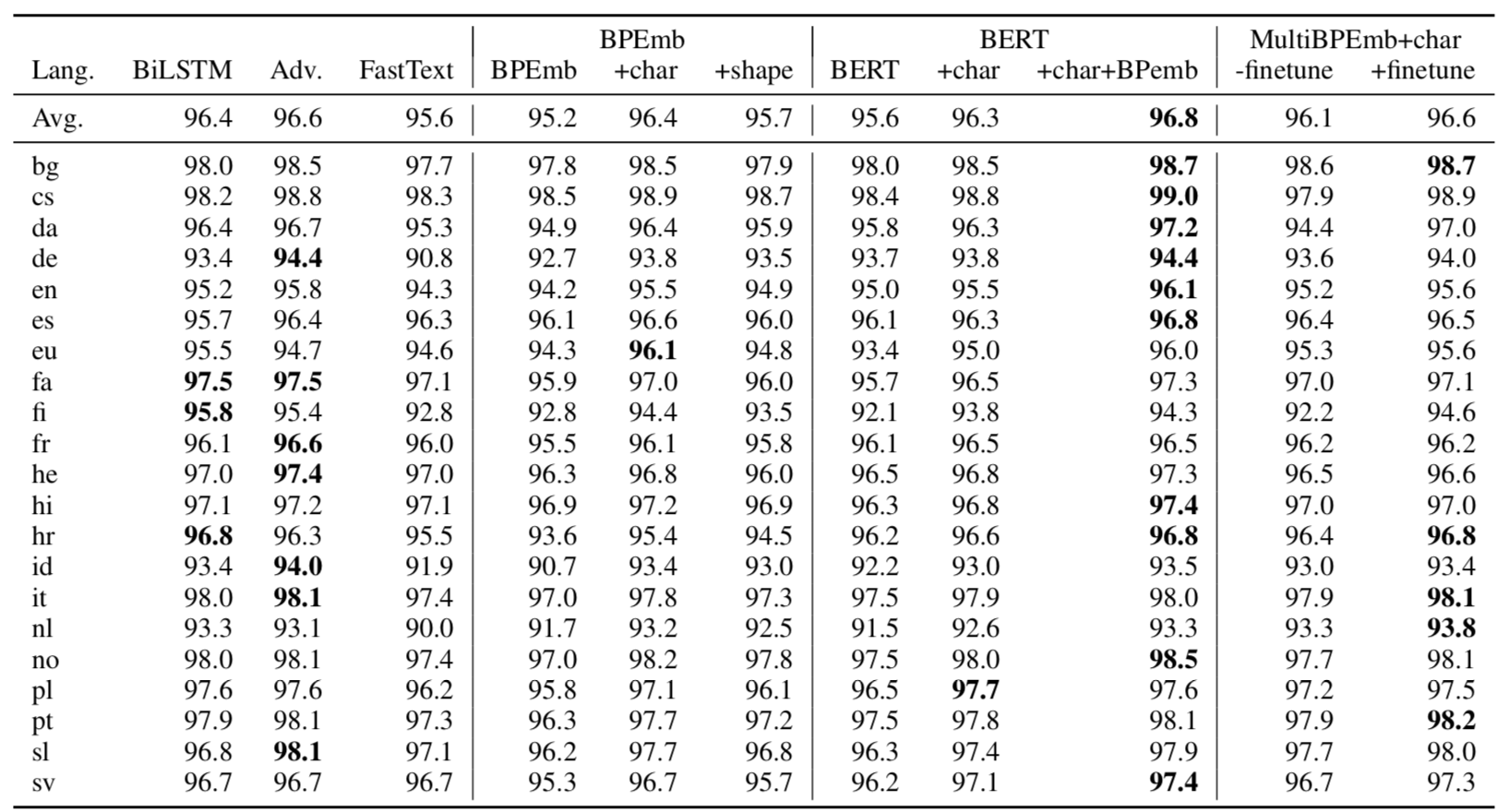
 bheinzerling
on 17 Jul 2019
bheinzerling
on 17 Jul 2019
@THEEJUNG and @alanakbik I am running into the same problem as well with TextClassifier. The reason seems to be the same what @alanakbik pointed out. I am trying to figure a solution for the same. As of now, it seems that using the FastTextEmbeddings just for getting vectors and then training a low-level model(in case of text classification) would be a better option. I will update once I figure out something.
 pranaychandekar
on 17 Jul 2019
pranaychandekar
on 17 Jul 2019
@alanakbik and @bheinzerling thanks for good suggestions. I will try both BytePairEmbeddings and BPEmb for my work. Also, thank you for @pranaychandekar for sharing your FastTextEmbeddings code! So far I couldn't find a nice solution but I will also try to figure out!
THEEJUNG
on 17 Jul 2019
BytePairEmbeddings and BPEmb are the same thing, BPEmb is just the abbreviation
bheinzerling
on 17 Jul 2019
@pranaychandekar @alanakbik There are two ways of making FastText embeddings use less space, but neither is perfect:
- Generate embeddings for all words in the corpus and then store only those (basically this https://github.com/facebookresearch/fastText#obtaining-word-vectors-for-out-of-vocabulary-words). This will drastically reduce file size for small corpora, but now the embeddings are specific to the corpus.
- Prune infrequent subwords, use hashing trick to further reduce vocab (https://www.aclweb.org/anthology/papers/N/N19/N19-1353/). This kind of compression seems to work well, but the resulting embeddings are not the original FastText embeddings anymore.
bheinzerling
on 17 Jul 2019
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
![stale[bot] picture](https://avatars.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 30 Apr 2020
stale[bot]
on 30 Apr 2020
You can now also use the WordEmbeddingsStore to create smaller models with FastText embeddings, see #1514
alanakbik
on 30 Apr 2020
Related issues
 Y4rd13
·
3Comments
alanakbik
·
3Comments
Y4rd13
·
3Comments
alanakbik
·
3Comments
 frtacoa
·
3Comments
frtacoa
·
3Comments
 jannenev
·
3Comments
jannenev
·
3Comments
 stefan-it
·
3Comments
stefan-it
·
3Comments
Most helpful comment
I compared FastText and BPEmb for POS-tagging. BPEmb combined with character embeddings is a good method in many languages and probably the best you can currently do if resources (disk space / GPU RAM) are a concern:
https://arxiv.org/abs/1906.01569