Flair: Training gets stuck indefinitely at epoch 1
Working on a multi class classification problem with 11 classes! Train had 45k documents, Val and Test have 9.5k documents each.
In my initial model run, I had defined the document embeddings using standalone embeddings and the training worked alright.
word_embeddings = [WordEmbeddings('glove')]
document_embeddings = DocumentRNNEmbeddings(word_embeddings, hidden_size=512, reproject_words=False,reproject_words_dimension=256)
However, when I try to stack embeddings,
glove_embedding = WordEmbeddings('glove')
flair_embedding_forward = FlairEmbeddings('news-forward')
flair_embedding_backward = FlairEmbeddings('news-backward')
document_embeddings = DocumentRNNEmbeddings([glove_embedding,flair_embedding_backward,flair_embedding_forward], hidden_size=512, reproject_words=False, reproject_words_dimension=256)
The training gets stuck at epoch1 indefinitely.
Longest sequence in train has 367 tokens! Already performed text truncation based on some data exploration and would not be able to truncate to a lower number of tokens.
System config:
- Ubuntu 18.04.2
- 64 GB RAM
- 2 NVIDIA Tesla P4 GPUs
Is it something got to do with my system config? Anything else I could do to speed up training? Thank you.
 tsu3010
tsu3010
All 9 comments
Hello @tsu3010 that is strange. What is the system doing? Is the memory filling up too much and it is swapping to disk? Could you print your full training script?
 alanakbik
on 27 May 2019
alanakbik
on 27 May 2019
Hi @alanakbik ,
Please find below the script I used for training,
import os
from flair.embeddings import FlairEmbeddings, DocumentPoolEmbeddings, WordEmbeddings, DocumentRNNEmbeddings, StackedEmbeddings
from flair.data import Sentence
from flair.data_fetcher import NLPTaskDataFetcher
from flair.models import TextClassifier
from flair.trainers import ModelTrainer
from flair.training_utils import EvaluationMetric
from flair.visual.training_curves import Plotter
data_path = os.path.join(os.path.realpath('..'), 'data')
model_iteration = 'test'
model_result_path = os.path.join(os.path.realpath('..'), 'models', model_iteration)
corpus = NLPTaskDataFetcher.load_classification_corpus(data_path, test_file='test2_trunc.csv',dev_file='val2_trunc.csv', train_file='train2_trunc.csv')
print(corpus.obtain_statistics())
glove_embedding = WordEmbeddings('glove')
flair_embedding_forward = FlairEmbeddings('news-forward')
flair_embedding_backward = FlairEmbeddings('news-backward')
document_embeddings = DocumentRNNEmbeddings([glove_embedding,flair_embedding_backward,flair_embedding_forward], hidden_size=512, reproject_words=False, reproject_words_dimension=256)
label_dict = corpus.make_label_dictionary()
classifier = TextClassifier(document_embeddings, label_dictionary=label_dict, multi_label=False)
trainer = ModelTrainer(classifier, corpus)
trainer.train(model_result_path,
evaluation_metric=EvaluationMetric.MICRO_F1_SCORE,
learning_rate=0.1,
mini_batch_size=32,
anneal_factor=0.5,
patience=5,
max_epochs=50)
I tested with an instance with more RAM and the training worked okay. Checked the memory usage for that instance while training and noticed that it was using up nearly 91 gigs.
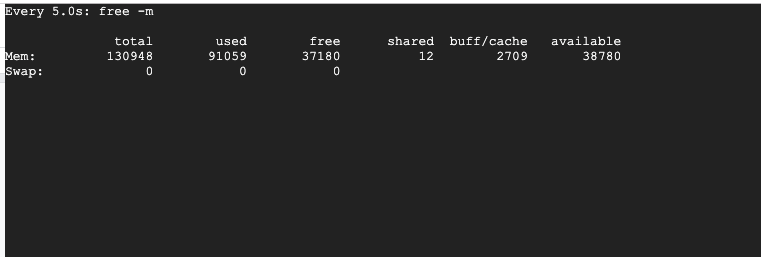
Is it common for stacked embeddings to use up this amount of memory during training?
tsu3010
on 28 May 2019
Hello @tsu3010 thanks for sharing the details. We have memory optimizations in the master branch that will be part of the next release. You can already use them by installing master branch like this:
pip install --upgrade git+https://github.com/zalandoresearch/flair.git
Then, you can adapt your script like this to optimize memory usage:
import os
from flair.embeddings import FlairEmbeddings, DocumentPoolEmbeddings, WordEmbeddings, DocumentRNNEmbeddings, StackedEmbeddings
from flair.data import Sentence
from flair.datasets import ClassificationCorpus
from flair.models import TextClassifier
from flair.trainers import ModelTrainer
from flair.training_utils import EvaluationMetric
from flair.visual.training_curves import Plotter
data_path = os.path.join(os.path.realpath('..'), 'data')
model_iteration = 'test'
model_result_path = os.path.join(os.path.realpath('..'), 'models', model_iteration)
corpus = ClassificationCorpus(data_path, test_file='test2_trunc.csv',dev_file='val2_trunc.csv', train_file='train2_trunc.csv', in_memory=False)
print(corpus.obtain_statistics())
glove_embedding = WordEmbeddings('glove')
flair_embedding_forward = FlairEmbeddings('news-forward', use_cache=True)
flair_embedding_backward = FlairEmbeddings('news-backward', use_cache=True)
document_embeddings = DocumentRNNEmbeddings([glove_embedding,flair_embedding_backward,flair_embedding_forward], hidden_size=512, reproject_words=False, reproject_words_dimension=256)
label_dict = corpus.make_label_dictionary()
classifier = TextClassifier(document_embeddings, label_dictionary=label_dict, multi_label=False)
trainer = ModelTrainer(classifier, corpus)
trainer.train(model_result_path,
evaluation_metric=EvaluationMetric.MICRO_F1_SCORE,
learning_rate=0.1,
mini_batch_size=32,
anneal_factor=0.5,
patience=5,
max_epochs=50,
embeddings_in_memory=False
)
Note the two in_memory parameters that are both set to False. This will stream the data from disk and discard embeddings after each use, so it will store nothing in memory. However, this comes at the price of speed since this means that FlairEmbeddings need to be generated each epoch. Because of this, I've set use_cache to True for the FlairEmbeddings, but you should only set this option if you have a fast disk drive and a lot of storage space available, otherwise set it to False.
An incremental Flair release is also upcoming, so this feature will be available to all very soon.
alanakbik
on 29 May 2019
I'm having the same problem but on google colab and setting in_memory to false didn't help...
 abbyokleung
on 13 Oct 2019
abbyokleung
on 13 Oct 2019
Hello @abbyokleung - we've just released Flair 0.4.4 which does a lot more memory optimizations and changes a few things. The use_cache parameter no longer extists for FlairEmbeddings, and the embeddings_im_memory parameter has been replaced by an embeddings_storage_mode which can be one of 'none', 'cpu' and 'gpu'. You also no longer need to specify multi_label when initializing the classifier.
For most memory effective training, do the following:
glove_embedding = WordEmbeddings('glove')
flair_embedding_forward = FlairEmbeddings('news-forward')
flair_embedding_backward = FlairEmbeddings('news-backward')
document_embeddings = DocumentRNNEmbeddings(
[glove_embedding, flair_embedding_backward, flair_embedding_forward],
hidden_size=512, reproject_words=False, reproject_words_dimension=256
)
label_dict = corpus.make_label_dictionary()
classifier = TextClassifier(document_embeddings, label_dictionary=label_dict)
trainer = ModelTrainer(classifier, corpus)
trainer.train(model_result_path,
learning_rate=0.1,
mini_batch_size=32,
anneal_factor=0.5,
patience=5,
max_epochs=50,
# set embedding storage to 'none' to hold no embeddings in memory
embeddings_storage_mode='none',
)
I'm having the same issue. embeddings_storage_model is set to cpu (default).
flair version=0.4.4
Training code:
tag_type = 'ner'
# 3. make the tag dictionary from the corpus
tag_dictionary = corpus.make_tag_dictionary(tag_type=tag_type)
print(tag_dictionary.idx2item)
# 4. initialize embeddings
embedding_types: List[TokenEmbeddings] = [
WordEmbeddings('glove'),
FlairEmbeddings('news-forward'),
FlairEmbeddings('news-backward')
]
embeddings: StackedEmbeddings = StackedEmbeddings(embeddings=embedding_types)
# 5. initialize sequence tagger
tagger: SequenceTagger = SequenceTagger(hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type=tag_type,
use_crf=True)
# 6. initialize trainer
trainer: ModelTrainer = ModelTrainer(tagger, corpus)
checkpoint = 'resources/taggers/p-ner/checkpoint.pt'
# trainer = ModelTrainer.load_checkpoint(checkpoint, corpus)
trainer.train('resources/taggers/p-ner',
learning_rate=0.1,
mini_batch_size=32,
max_epochs=150,
checkpoint=True)
Changing embeddings_storage_model to 'none' seems to fix the problem, but I'm not entirely sure as this isn't consistent (I was able to run it previously with embeddings_storage_model = 'cpu')
 omri374
on 11 Nov 2019
omri374
on 11 Nov 2019
An additional insight: Time between epochs is relatively long. This is when trained with embeddings_storage_model = 'none':
2019-11-12 16:08:45,434 epoch 1 - iter 1750/1756 - loss 1.31937953 - samples/sec: 23.21
2019-11-12 16:08:53,262 ----------------------------------------------------------------------------------------------------
2019-11-12 16:08:53,262 EPOCH 1 done: loss 1.3178 - lr 0.1000
2019-11-12 16:18:40,493 DEV : loss 0.4822116792201996 - score 0.9509
2019-11-12 16:18:40,647 BAD EPOCHS (no improvement): 0
2019-11-12 16:18:47,263 ----------------------------------------------------------------------------------------------------
2019-11-12 16:18:48,485 epoch 2 - iter 0/1756 - loss 0.73820901 - samples/sec: 4590.47
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
![stale[bot] picture](https://avatars.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 29 Apr 2020
stale[bot]
on 29 Apr 2020
Same problem here. Impossible to pass first epoch when training a TARS model.
# TARS classifier
tars = TARSClassifier(task_name='XGLUE_DE', label_dictionary=corpus_xglue.make_label_dictionary())
trainer = ModelTrainer(tars, corpus_xglue)
trainer.train(base_path="RESOURCES/XGLUE",
learning_rate=0.02,
mini_batch_size=16,
mini_batch_chunk_size=4,
train_with_dev=False,
#monitor_train=True,
#monitor_test=True,
embeddings_storage_mode='cpu',
max_epochs=20)
Logs are the following:
2021-03-11 14:55:50,153 Model training base path: "RESOURCES/XGLUE"
2021-03-11 14:55:50,153 ----------------------------------------------------------------------------------------------------
2021-03-11 14:55:50,154 Device: cuda:0
2021-03-11 14:55:50,154 ----------------------------------------------------------------------------------------------------
2021-03-11 14:55:50,155 Embeddings storage mode: cpu
2021-03-11 14:55:50,307 ----------------------------------------------------------------------------------------------------
2021-03-11 14:57:38,198 epoch 1 - iter 62/625 - loss 0.70070819 - samples/sec: 9.21 - lr: 0.020000
2021-03-11 14:59:32,125 epoch 1 - iter 124/625 - loss 0.67006618 - samples/sec: 8.71 - lr: 0.020000
2021-03-11 15:01:20,601 epoch 1 - iter 186/625 - loss 0.64827384 - samples/sec: 9.15 - lr: 0.020000
2021-03-11 15:03:16,799 epoch 1 - iter 248/625 - loss 0.60804691 - samples/sec: 8.54 - lr: 0.020000
2021-03-11 15:05:04,798 epoch 1 - iter 310/625 - loss 0.57808056 - samples/sec: 9.19 - lr: 0.020000
2021-03-11 15:06:59,523 epoch 1 - iter 372/625 - loss 0.54129447 - samples/sec: 8.65 - lr: 0.020000
2021-03-11 15:08:46,966 epoch 1 - iter 434/625 - loss 0.50331229 - samples/sec: 9.23 - lr: 0.020000
2021-03-11 15:10:41,997 epoch 1 - iter 496/625 - loss 0.47642022 - samples/sec: 8.62 - lr: 0.020000
2021-03-11 15:12:37,954 epoch 1 - iter 558/625 - loss 0.45534322 - samples/sec: 8.56 - lr: 0.020000
2021-03-11 15:14:26,824 epoch 1 - iter 620/625 - loss 0.43260887 - samples/sec: 9.11 - lr: 0.020000
2021-03-11 15:14:35,498 ----------------------------------------------------------------------------------------------------
2021-03-11 15:14:35,499 EPOCH 1 done: loss 0.4301 - lr 0.0200000
To overcome this problem, I have removed arguments monitor_train and monitor_test and also set embeddings_storage_mode=cpu.
 RBeaudet
on 11 Mar 2021
RBeaudet
on 11 Mar 2021
Related issues
 Aditya715
·
3Comments
Aditya715
·
3Comments
 mnishant2
·
3Comments
mnishant2
·
3Comments
 frtacoa
·
3Comments
frtacoa
·
3Comments
 davidsbatista
·
3Comments
davidsbatista
·
3Comments
 aschmu
·
3Comments
aschmu
·
3Comments
Most helpful comment
Hello @tsu3010 thanks for sharing the details. We have memory optimizations in the master branch that will be part of the next release. You can already use them by installing master branch like this:
Then, you can adapt your script like this to optimize memory usage:
Note the two in_memory parameters that are both set to False. This will stream the data from disk and discard embeddings after each use, so it will store nothing in memory. However, this comes at the price of speed since this means that
FlairEmbeddingsneed to be generated each epoch. Because of this, I've setuse_cachetoTruefor theFlairEmbeddings, but you should only set this option if you have a fast disk drive and a lot of storage space available, otherwise set it toFalse.An incremental Flair release is also upcoming, so this feature will be available to all very soon.