Flair: Pretrained Embeddings for multiple languages.
Hello. I have been looking around to figure out the usage of pretrained embeddings for multiple languages. What I am trying to achieve is to have pretrained embeddings for multiple languages so that my ML model knows similar words across multiple languages. For example, "Good" in English is the same as "Gut" in German. Any help in this regard would be highly appreciated
 nawabhussain
nawabhussain
All 5 comments
I think you should check the relevant papers from Mikel Artetxe:
- A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings
- Generalizing and improving bilingual word embedding mappings with a multi-step framework of linear transformations
- Learning bilingual word embeddings with (almost) no bilingual data
- Learning principled bilingual mappings of word embeddings while preserving monolingual invariance
And their implementation in the vecmap library :)
 stefan-it
on 16 Mar 2019
stefan-it
on 16 Mar 2019
And the MUSE library contains several pretrained word embeddings for English-X :)
stefan-it
on 16 Mar 2019
@stefan-it Thank you very much for replying so quickly. I will check the papers and vecmap library as you pointed out. I have a question about MUSE though. For instance, German-English there is an entry "mit with", would that mean that I can use the embeddings of with for mit, or vice versa, so that the similar words can be clustered?
nawabhussain
on 16 Mar 2019
I haven't tried it yet, but there's a nice Notebook that shows how to get nearest neighbors and even visualize bilingual embeddings:
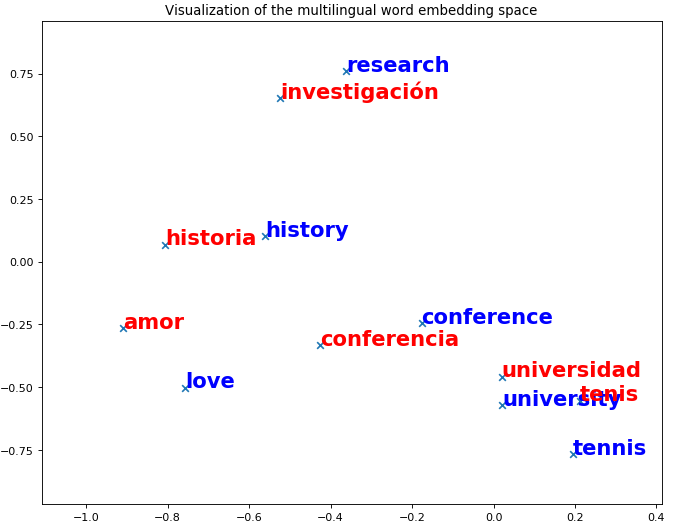
See here:
https://github.com/facebookresearch/MUSE/blob/master/demo.ipynb
stefan-it
on 16 Mar 2019
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
![stale[bot] picture](https://avatars.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 30 Apr 2020
stale[bot]
on 30 Apr 2020
Related issues
 alanakbik
·
3Comments
alanakbik
·
3Comments
 ciaochiaociao
·
3Comments
ciaochiaociao
·
3Comments
 isanvicente
·
3Comments
isanvicente
·
3Comments
 inyukwo1
·
3Comments
inyukwo1
·
3Comments
 happypanda5
·
3Comments
happypanda5
·
3Comments