Fasttext: Can we do grid search on fasttext trained model ?
i have trained model in python using
model = fastText.train_supervised(input=filename, lr=1.0, wordNgrams=2, epoch=25).
i want to do cross validation and grid search for fine tuning the parameters.
 seemamishra33
seemamishra33
All 6 comments
yes, it's available bash script from Fasttext Quickstart Guide book which does it hyperparameter optimisation . otherwise i tried with a wrapper in sklearn. malloc
 riemann85
on 23 Nov 2018
riemann85
on 23 Nov 2018
I wrote a rough draft like this, please tell me if something seems wrong.
In the code below, I assume the train and validation data is in a "dataAddr" folder. I also save each of the models & it's associated information in a separate directory i.e. outRootAddr/i (where i is the model number)
Also, rename the file to gridSearch.sh, and chmod +x to run it, I couldn't add a .sh file here.
Correct me if I'm wrong, the parameters I've listed are the only ones I can optimize for text classification right?
I'd appreciate any suggestions
 abeer-khan
on 23 Nov 2018
abeer-khan
on 23 Nov 2018
Missing params to explore:
minCount min number of word occurrences, like in TF-IDF to avoid noise
lrUpdateRate rate of update for the Learning rate
min maxn min-max length of char ngram
negs is a parameter which is used for Negative Sampling , number of
negative samples in order not to update ALL weights , taking only #negs
observations
ws is the Window Size , expect that model capacity increases as it is
greater
malloc
On Fri, 23 Nov 2018 at 21:54, abeerunscore96 notifications@github.com
wrote:
I wrote a rough draft like this, please tell me if something seems wrong.
In the code below, I assume the train and validation data is in a
"dataAddr" folder. I also save each of the models & it's associated
information in a separate directory i.e. outRootAddr/i (where i is the
model number)`lrs=(0.05 0.1 0.25 0.5 0.7 1.0)
dims=(100 150 200 250 300)
wss=(2 4 5 7 10 15 20) #dont really know what this is
wordNgramss=(1 2 3 4 5)
epochs=(1 5 10 20 25 30 50 100 200 300)
negs=(1 5 10 20) #dont really know what this is
losses=("ns" "hs" "softmax")
saveOutputs=(1)i=0
dataAddr='' #something that contains "train.txt" and "validation.txt"
outRootAddr='' #something to which you will save the models, their
metrics, the parameters they were trained on
for lr in "${lrs[@]}"
do
for dim in "${dims[@]}"
do
for ws in "${wss[@]}"
do
for wordNgrams in "${wordNgramss[@]}"
do
for epoch in "${epochs[@]}"
do
for neg in "${negs[@]}"
do
for loss in "${losses[@]}"
do
for saveOutput in "${saveOutputs[@]}"
do
let "i += 1"
echo "At model parameter combo i = $i"
outAddr="$outRootAddr/$i"
echo "Saving the model stuff at $outAddr"
if [ ! -d $outAddr ];
then
mkdir $outAddr
fi#save some notes about parameters pars="[lr: $lr\ndim: $dim\nws: $ws\nwordNgrams: $wordNgrams\nepoch: $epoch\nneg: $neg\nloss: $loss\nsaveOutput: $saveOutput\n]" parFile="parList.txt" echo $pars > "$outAddr/$parFile" #train model, save cerr, save cout ./fasttext supervised -input $dataAddr/train.txt -output $outAddr/model -lr $lr -lrUpdateRate 100 -dim $dim -ws $ws -epoch $epoch -neg $neg -loss $loss -thread 12 -wordNgrams $wordNgrams -saveOutput $saveOutput 1>>$outAddr/$i.cout 2>>$outAddr/$i.cerr #also save a test output at various at K's ./fasttext test $outAddr/model.bin $dataAddr/validation.txt 1 > $outAddr/At1.test ./fasttext test $outAddr/model.bin $dataAddr/validation.txt 2 > $outAddr/At2.test ./fasttext test $outAddr/model.bin $dataAddr/validation.txt 3 > $outAddr/At3.test ./fasttext test $outAddr/model.bin $dataAddr/validation.txt 4 > $outAddr/At4.test ./fasttext test $outAddr/model.bin $dataAddr/validation.txt 5 > $outAddr/At5.test ./fasttext test $outAddr/model.bin $dataAddr/validation.txt 6 > $outAddr/At6.test ./fasttext test $outAddr/model.bin $dataAddr/validation.txt 7 > $outAddr/At7.test ./fasttext test $outAddr/model.bin $dataAddr/validation.txt 8 > $outAddr/At8.test ./fasttext test $outAddr/model.bin $dataAddr/validation.txt 9 > $outAddr/At9.test ./fasttext test $outAddr/model.bin $dataAddr/validation.txt 10 > $outAddr/At10.test done done done donedone
donedone
`
Correct me if I'm wrong, the parameters I've listed are the only ones I
can optimize for text classification right?
I'd appreciate any suggestions—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/facebookresearch/fastText/issues/425#issuecomment-441316594,
or mute the thread
https://github.com/notifications/unsubscribe-auth/ALCQ25LUw7GME3pm-ExfajbaeQoc9PGxks5uyGCTgaJpZM4R2lxw
.
riemann85
on 24 Nov 2018
What combinations of lr and lrUpdateRate would you recommend? I imagine a higher lr should be combined with a lower lrUpdateRate
abeer-khan
on 26 Nov 2018
The answer is specific to your problem,
Lower learning rate in optimization guarantees reliable estimates in loss
minimization, limiting the problem of minima overshooting. However with low
lr, loss Can decrease too slowly.
On Monday, 26 November 2018, abeerunscore96 notifications@github.com
wrote:
What combinations of lr and lrUpdateRate would you recommend? I imagine a
higher lr should be combined with a lower lrUpdateRate—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/facebookresearch/fastText/issues/425#issuecomment-441496418,
or mute the thread
https://github.com/notifications/unsubscribe-auth/ALCQ20ycqDrDoJjtNeU-BnOg2gxAA6WZks5uy0nggaJpZM4R2lxw
.
riemann85
on 29 Nov 2018
@seemamishra33
A follow up to the grid search script.
The grid search bash file I sent before results in several folders being created in the directory in variable "outRootAddr" , where each folder stands for a model, and each model's folder contains it's parameter files, scores, binary file of model, and debugging files.
But to get a quick view of which parameter combinations had good precisions / recalls, we would have to open each model's folder which is a drag. I also prefer working in python. I wrote the below python script to grab all the precision/recall values, and corresponding parameters from each of the folders, and to arrange it in a neat little dataframe which I store as the csv file scoresDatabase.csv
#get all model's folders
addr =outRootAddr
modelsFolders = list(os.listdir(addr))
modelsFolders.sort()
print (modelsFolders)
modelsFolders = [ str(mf) for mf in modelsFolders ]
def parseScores(fileaddr):
scores = {}
with open(fileaddr, 'r') as f:
content = list(f.readlines())
for line in content:
temp = line.split('\t')
scores[temp[0].strip()] = float(temp[1].strip())
#change it so key is mf, value is another dict without intermediate keys
def removeSecondLevelIndirectionFromDict(d):
ret = {}
for key1 in d: #keep this one
ret[key1] = {}
for key2 in d[key1]:
for key3 in d[key1][key2]:
ret[key1][key3] = d[key1][key2][key3]
scores = removeSecondLevelIndirectionFromDict(scores)
return scores
def parsePars(fileaddr):
pars = {}
with open(fileaddr, 'r') as f:
content = list(f.readlines())
for line in content:
temp = line[1:-2]
temp = temp.split('\\n')
temp = [ t.strip() for t in temp if t.strip() != '' ]
for t in temp:
split = t.split(':')
pars[split[0].strip()] = split[1].strip()
try:
pars[split[0].strip()] = float(pars[split[0].strip()])
except:
continue
return pars
scores = {} #key: mf (string), value, another dict of scores and their values
pars = {}
for mf in modelsFolders:
print (mf)
modelFiles = os.listdir(addr+mf)
scoreFiles = [ mf for mf in modelFiles if 'At1' in mf and 'test' in mf ] #isolate the test files produced by fasttext which contain the scores, using precisions @1 for now
scoreFiles.sort()
# print (scoreFiles)
parFile = 'parList.txt'
#read scores
scores[mf] = {}
for scoreFile in scoreFiles:
scores[mf][scoreFile] = parseScores(addr+mf+'/'+scoreFile)
#read parameters
pars[mf] = parsePars(addr+mf+'/'+parFile)
parsDf = pd.DataFrame.from_dict(pars, orient='index')
parsDf['mf'] = parsDf.index
parsDf['mf'] = parsDf['mf'].astype(int)
print (parsDf.head())
scoresDf = pd.DataFrame.from_dict(scores, orient='index')
scoresDf['mf'] = scoresDf.index
scoresDf['mf'] = scoresDf['mf'].astype(int)
print (scoresDf.head())
scoresDatabase = pd.merge(parsDf, scoresDf, on="mf")
scoresDatabase.to_csv(addr+'scoresDatabase.csv')
The kind of output you can expect:
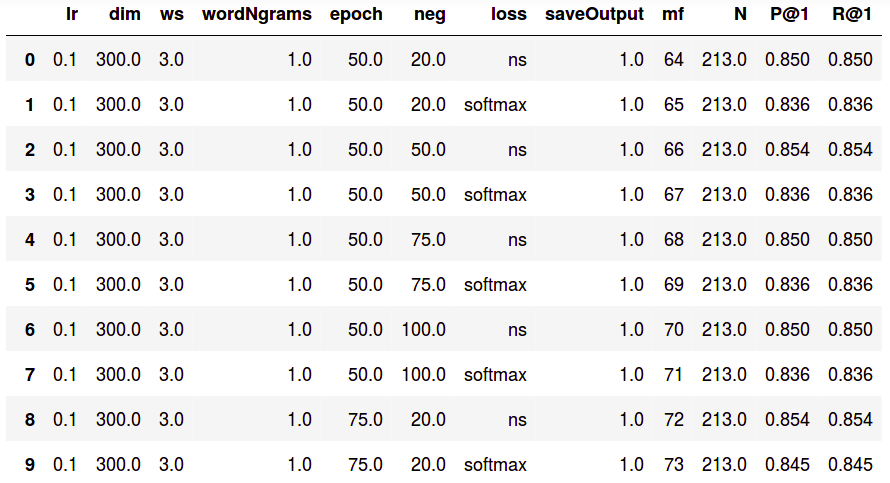
Suggestions for improvement / questions are welcome
abeer-khan
on 10 Dec 2018
Related issues
 PGryllos
·
4Comments
PGryllos
·
4Comments
 kurtjanssensai
·
3Comments
kurtjanssensai
·
3Comments
 yasonk
·
3Comments
yasonk
·
3Comments
 shriiitk
·
3Comments
shriiitk
·
3Comments
 a11apurva
·
3Comments
a11apurva
·
3Comments
Most helpful comment
The answer is specific to your problem,
Lower learning rate in optimization guarantees reliable estimates in loss
minimization, limiting the problem of minima overshooting. However with low
lr, loss Can decrease too slowly.
On Monday, 26 November 2018, abeerunscore96 notifications@github.com
wrote: