Fairseq: How to reproduce fine-tuning en-zh with mBART?
❓ Questions and Help
What is your question?
Similar to #1841 and #2056
In short, can you provide more detail on producing the result in table 3?
Such as what data is used for train, valid and test? How many GPUs are used for fine tuning? How are batch size, token size and update frequency set? These are not mentioned in Section 3.1 of the paper.
What have you tried?
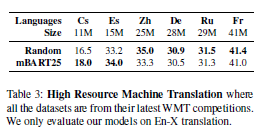
Referring to table 3 of the paper,
mBART en-zh is able to achieve 33.3 score.
And I was trying to reproduce the result.
Since I have difficulty in getting all 25M sentence pairs, I was trying with 12M only and I do expect the BLEU score to be a bit lower than the paper described.
However, I only got 29.0 after 100k updates.
I was using news-commentary-v15 and UNCorpus-v1.0 for training, newsdev2017 and newstest2018 for valid, and newstest2019 for testing.
Followed same instructions in README to preprocess the data.
Fine-tuned on en-zh with 2x V100 (32GB) and the following command:
CUDA_VISIBLE_DEVICES=0,1 fairseq-train train-data/wmt-en-zh \
--encoder-normalize-before --decoder-normalize-before \
--arch mbart_large --task translation_from_pretrained_bart \
--source-lang en_XX --target-lang zh_CN \
--criterion label_smoothed_cross_entropy \
--label-smoothing 0.2 --dataset-impl mmap \
--optimizer adam --adam-eps 1e-06 --adam-betas '(0.9, 0.98)' \
--lr-scheduler polynomial_decay --lr 3e-05 --min-lr -1 \
--warmup-updates 2500 --total-num-update 100000 \
--dropout 0.3 --attention-dropout 0.1 \
--weight-decay 0.0 --max-tokens 1024 \
--update-freq 8 --save-interval 1 --save-interval-updates 5000 \
--keep-interval-updates 10 --no-epoch-checkpoints --seed 222 \
--log-format simple --log-interval 2 \
--reset-optimizer --reset-meters --reset-dataloader --reset-lr-scheduler \
--restore-file mbart.cc25/model.pt --langs $langs \
--layernorm-embedding --ddp-backend no_c10d \
--max-update 100000 --save-dir mbart-wmt-en-zh-checkpoints --fp16 \
|& tee -a mbart-wmt-en-zh-screenlog
And generate on en-zh and compute BLEU with the following command:
MODEL=mbart-wmt-en-zh-checkpoints/checkpoint_best.pt
CUDA_VISIBLE_DEVICES=0 fairseq-generate --path=$MODEL train-data/wmt-en-zh/ \
--task translation_from_pretrained_bart --gen-subset test -t zh_CN -s en_XX \
--bpe 'sentencepiece' --sentencepiece-vocab mbart.cc25/sentence.bpe.model \
--remove-bpe 'sentencepiece' --langs $langs --sacrebleu --max-tokens 1024 \
> evaluation/mbart-wmt-en-zh
FILE=evaluation/mbart-wmt-en-zh
cat $FILE | grep -P "^D" | sort -V | cut -f 3- > $FILE.txt
cat $FILE | grep -P "^T" | sort -V | cut -f 2- > wmt-en-zh-ref.txt
sacrebleu --tok zh wmt-en-zh-ref.txt < $FILE.txt
# BLEU+case.mixed+numrefs.1+smooth.exp+tok.zh+version.1.4.9 = 29.0 62.9/38.0/24.8/16.9 (BP = 0.915 ratio = 0.919 hyp_len = 73329 ref_len = 79825)
What's your environment?
- fairseq Version (e.g., 1.0 or master): master
- PyTorch Version (e.g., 1.0):
v1.5.0 - OS (e.g., Linux):
Ubuntu 18.04 - How you installed fairseq (
pip, source): source - Build command you used (if compiling from source):
git clone https://github.com/pytorch/fairseq
cd fairseq
pip install --editable .
- Python version:
3.6.9 - CUDA version:
v10.1 - GPU models and configuration: 2x V100 (32GB)
 thpun
thpun
All 7 comments
Hi @thpun, for training, I suggest you use 16 update freqs and 0.1 label smoothing. For decoding, your generation text is too short, you should set length penalty to a much larger value. Are you forgetting to remove lang_id (sed 's/[zh_CN]//g')?
BTW, I found you use FP16 for fine-tuning, does this setting also work in other language directions? I fail to use FP16 fine-tuning on the WMT'16 En-Ro task.
 SunbowLiu
on 24 Jun 2020
SunbowLiu
on 24 Jun 2020
Thank @SunbowLiu for your advice!
After some experiments, I did find out that using more GPUs (or setting higher update frequencies) improves the performance.
| | 12M pairs, 16x | 15M pairs, 32x | 15M pairs, 64x |
|------|-------|------|------|
| BLEU | 29.0 | 32.5 | 33.0 |
But i haven't tried to use 0.1 label smoothing.
Concerning about lang_id, i was using fairseq-generate to do the inference and I didnt see any lang_id appending to the hypothesis nor the detokenized results. So I didnt put sed 's/[zh_CN]//g' to the command.
And so far I am using FP16 to do fine-tuning on both En-Zh and Zh-En without problem.
I havent yet tried on other language pairs.
Perhaps you need to open an issue if the FP16 issue persists.
thpun
on 7 Jul 2020
@thpun, thank you for sharing! I still very curious about the 0.1 label smooth result and guess it would bring additional performance boost. If you try it in the future, please share the result with me! Thank you very much!
SunbowLiu
on 7 Jul 2020
@thpun, I am currently also working on the WMT17 zh-en translation task, and wanna know how did you prepare and process the 15M training pairs.
SunbowLiu
on 29 Sep 2020
I followed what the paper stated in Section 2.1:
We do not apply additional preprocessing, such as truecasing or normalizing punctuation/characters.
For the 15M data, I was using WikiMatrix, WikiTitles, UN Corpus & news commentary.
As WikiMatrix provides language id in the file, I filtered out those pairs are not classified as "en" to "zh":
awk -F '\t' '$4=="en" && $5=="zh"' WikiMatrix.en-zh.langid.tsv | cut -f 2 > wikimatrix.en
awk -F '\t' '$4=="en" && $5=="zh"' WikiMatrix.en-zh.langid.tsv | cut -f 3 > wikimatrix.zh
For the other corpus (tsv files), I removed those pairs which either source or target is missing.
After that, just concat the corpus together and run spm_enocde on the corpus.
thpun
on 29 Sep 2020
Hey @thpun, may i max-token, you used for fine tuning?
 mani-rai
on 17 Nov 2020
mani-rai
on 17 Nov 2020
I used --max-token 1024. But you can try other value which are slightly higher without hitting OOM problem.
And not sure whether you can try some even higher values if using zero sharding & activation checkpointing in Fairseq v0.10.0
thpun
on 18 Nov 2020
Related issues
 zqs01
·
3Comments
zqs01
·
3Comments
 gaopengcuhk
·
3Comments
gaopengcuhk
·
3Comments
 PhilippeMarcotte
·
3Comments
PhilippeMarcotte
·
3Comments
 prihoda
·
3Comments
prihoda
·
3Comments
 galphag
·
3Comments
galphag
·
3Comments