Fairseq: The accuracy that I have done for RoBERTa-large fine-tuning on RACE has a big gap with the paper proposed
🐛 Bug
Hi,
I have tried to use 2 Tesla V100 GPU with 32 GB memory to fine-tuning the RoBERTa-large model with RACE dataset. Here is the part of the result. Now I have finished the running with 5 epochs, but the loss and accuracy look like nearly no change. Does anyone have met the problem before? I just use the exact same parameters from that website for the fine-tuning on RACE dataset(https://github.com/pytorch/fairseq/blob/master/examples/roberta/README.race.md). Will be great to have any suggestions from you.
Many thanks.
Here is the command and parameters that I used.
MAX_EPOCH=5 # Number of training epochs.
LR=1e-05 # Peak LR for fixed LR scheduler.
NUM_CLASSES=4
MAX_SENTENCES=1 # Batch size per GPU.
UPDATE_FREQ=8 # Accumulate gradients to simulate training on 8 GPUs.
DATA_DIR=/path/to/race-output-dir
ROBERTA_PATH=/path/to/roberta/model.pt
CUDA_VISIBLE_DEVICES=0,1 fairseq-train $DATA_DIR --ddp-backend=no_c10d \
--restore-file $ROBERTA_PATH \
--reset-optimizer --reset-dataloader --reset-meters \
--best-checkpoint-metric accuracy --maximize-best-checkpoint-metric \
--task sentence_ranking \
--num-classes $NUM_CLASSES \
--init-token 0 --separator-token 2 \
--max-option-length 128 \
--max-positions 512 \
--truncate-sequence \
--arch roberta_large \
--dropout 0.1 --attention-dropout 0.1 --weight-decay 0.01 \
--criterion sentence_ranking \
--optimizer adam --adam-betas '(0.9, 0.98)' --adam-eps 1e-06 \
--clip-norm 0.0 \
--lr-scheduler fixed --lr $LR \
--fp16 --fp16-init-scale 4 --threshold-loss-scale 1 --fp16-scale-window 128 \
--max-sentences $MAX_SENTENCES \
--required-batch-size-multiple 1 \
--update-freq $UPDATE_FREQ \
--max-epoch $MAX_EPOCH
Here is the final training result after 5 epoch. The best accuracy is only 0.261661.
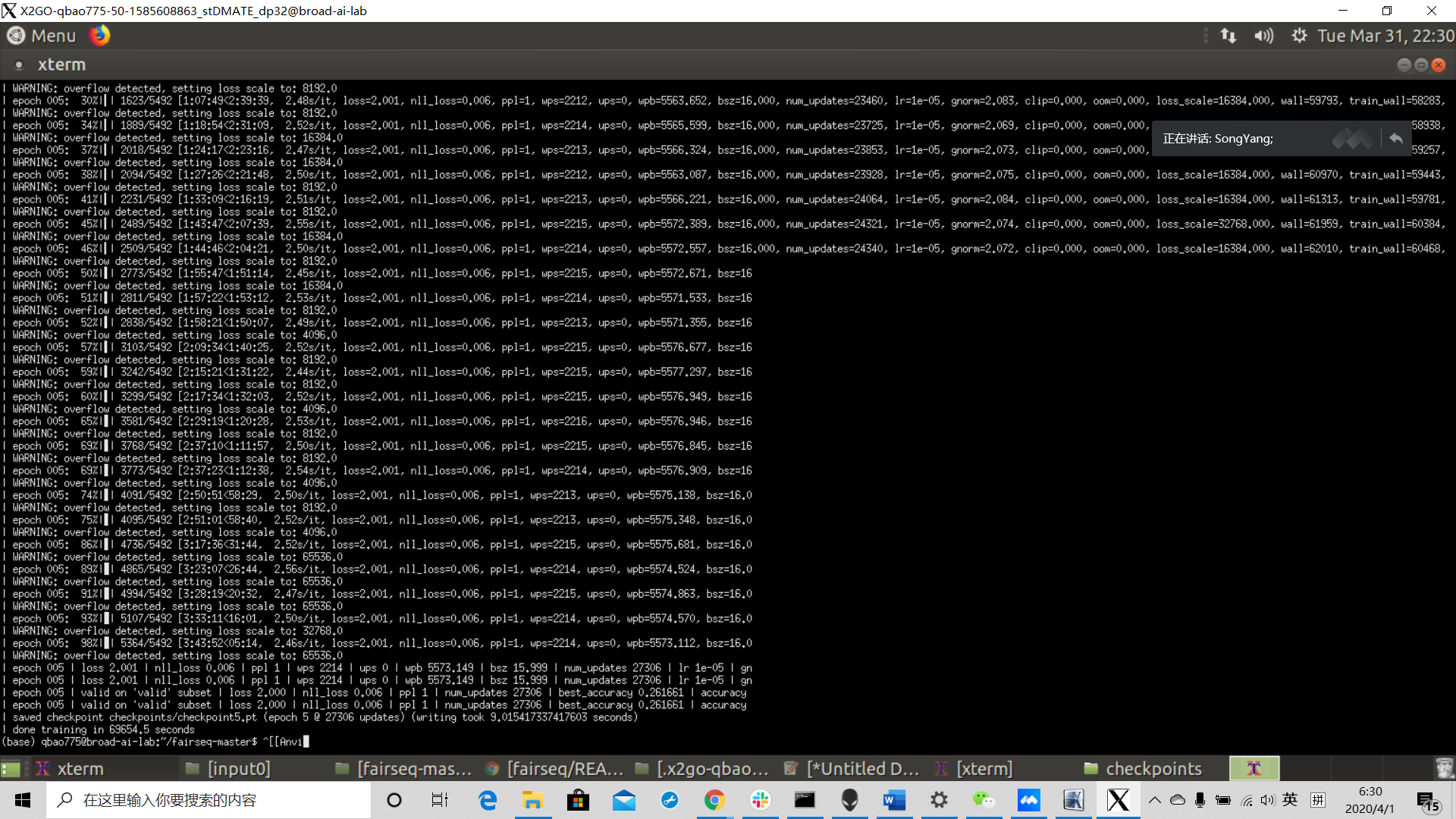
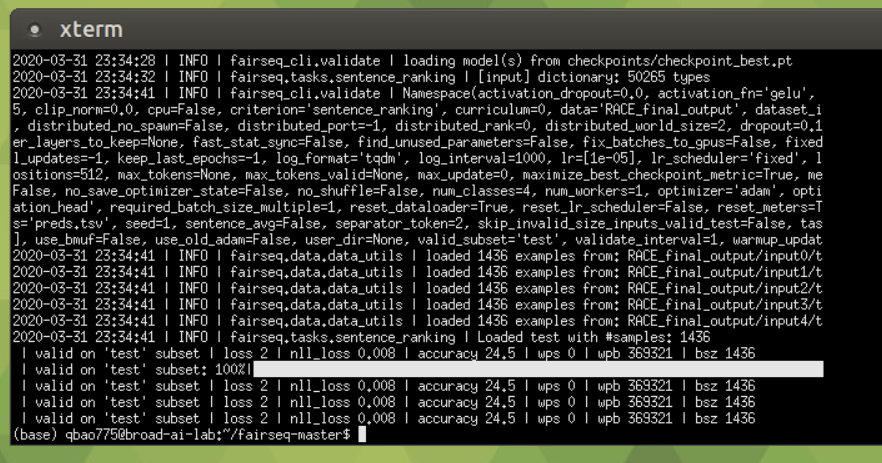
Here is the evaluation result and the accuracy is only 0.245.
 14H034160212
14H034160212
>All comments
I seem to find the solution from that link. https://github.com/pytorch/fairseq/issues/1114
It worth to have a try.
It is working when I set the UPDATE_FREQ=16. The training accuracy is going to 0.83 after the first epoch and the loss is doing gradient descent.
Here is the training and validation result in the end. The average training accuracy is 0.96072 and the average validation accuracy is 0.833231.
| epoch 005 | loss 0.158 | nll_loss 0.000 | ppl 1 | wps 770 | ups 0 | wpb 5574.176 | bsz 15.999 | num_updates 27301 | lr 1e-05 | gnorm 25.694 | clip 0.000 | oom 0.000 | loss_scale 128.000 | wall 248855 | train_wall 110662 | accuracy 0.96072
| epoch 005 | valid on 'valid' subset | loss 1.066 | nll_loss 0.003 | ppl 1 | num_updates 27301 | best_accuracy 0.843871 | accuracy 0.833231
| saved checkpoint checkpoints/checkpoint5.pt (epoch 5 @ 27301 updates) (writing took 12.924743890762329 seconds)
| done training in 249225.2 seconds
Here is the test result in the end. The average test accuracy is 86.8.
| valid on 'test' subset | loss 0.659 | nll_loss 0.003 | accuracy 86.8 | wps 0 | wpb 369321 | bsz 1436
| valid on 'test' subset | loss 0.659 | nll_loss 0.003 | accuracy 86.8 | wps 0 | wpb 369321 | bsz 1436
| valid on 'test' subset | loss 0.659 | nll_loss 0.003 | accuracy 86.8 | wps 0 | wpb 369321 | bsz 1436
| valid on 'test' subset | loss 0.659 | nll_loss 0.003 | accuracy 86.8 | wps 0 | wpb 369321 | bsz 1436
Related issues
 PhilippeMarcotte
·
3Comments
PhilippeMarcotte
·
3Comments
 jmatak
·
3Comments
jmatak
·
3Comments
 AranKomat
·
3Comments
AranKomat
·
3Comments
 galphag
·
3Comments
galphag
·
3Comments
 zqs01
·
3Comments
zqs01
·
3Comments
Most helpful comment
I seem to find the solution from that link. https://github.com/pytorch/fairseq/issues/1114
It worth to have a try.
It is working when I set the
UPDATE_FREQ=16. The training accuracy is going to 0.83 after the first epoch and the loss is doing gradient descent.Here is the training and validation result in the end. The average training accuracy is 0.96072 and the average validation accuracy is 0.833231.
Here is the test result in the end. The average test accuracy is 86.8.