Fairseq: fine-tuning mBART for monolingual summarization
I was wondering whether it'd be possible to fine-tune mBART for summarization on one of the languages used during pre-training. Judging from the way mBART (cc25) was pre-trained (language to same language instead of cross-language) I suppose it's doable?
My idea is to fine-tune by simply taking the text as input to the encoder and the summary as input/output of the decoder.
Do you have any tips or in general something I should be worried about?
Thanks!
 blackcat84
blackcat84
All 9 comments
+1
It seems like the code doesn't allow for this. The input and output language need to be different, since they are used to differentiate input and output data in the code. This leaves me wondering: Is there any reason this shouldn't be done using the normal translation script?
Anyways, I got it to work by changing lines 46, 66 and 77 of the following file
https://github.com/pytorch/fairseq/blob/master/fairseq/tasks/translation.py
to allow for input and output to have the same language in their filename.
 maruker
on 13 Apr 2020
maruker
on 13 Apr 2020
Are you sure the languages need to be different? I was able to run the code by simply naming source and target language as src and tgt (in argument parsing), but having in reality the same language in input and output
blackcat84
on 17 Apr 2020
Ok that is interesting. So you just ran
train.py --source-lang src --target-lang tgt ..
I initially thought that these command line arguments are used for more things than just loading the dataset, but maybe this is in fact the intended way to use them. For mBART, the dictionary is the same anyways for all languages.
maruker
on 17 Apr 2020
Yes I think that should be fine, this is similar to what is suggested for the monolingual BART here
https://github.com/pytorch/fairseq/blob/master/examples/bart/README.summarization.md
except I had to change the task from translation to translation from pretrained
blackcat84
on 17 Apr 2020
I can run the train cli code with --source-lang src --target-lang tgt. but in this case, how language id works? (like ko_KR, en_XX, ro_RO, etc...) for mBART training, I should add the languaged code as eos token.
 hyunwoongko
on 9 Sep 2020
hyunwoongko
on 9 Sep 2020
I'm not sure what you mean by
I should add the languaged code as eos token.
but as long as you are using a language that was included during pre-training I don't think you need to worry, if I remember correctly the vocabulary is the same for all languages and the language id in your case would simply be src and tgt
blackcat84
on 10 Sep 2020
Yesterday, I studied this problem all day. When mBART is pre-learning, it is learned that the decoder must receive [ko_KR] as bos to output Korean, and the decoder must receive [ar_AR] as bos to output in Arabic. And learned that to receive Korean as the source, Encoder must receive [ko_KR] as the eos of the source document, and to receive Arabic as the source, Encoder must receive [ar_AR] as the eos of the source document.
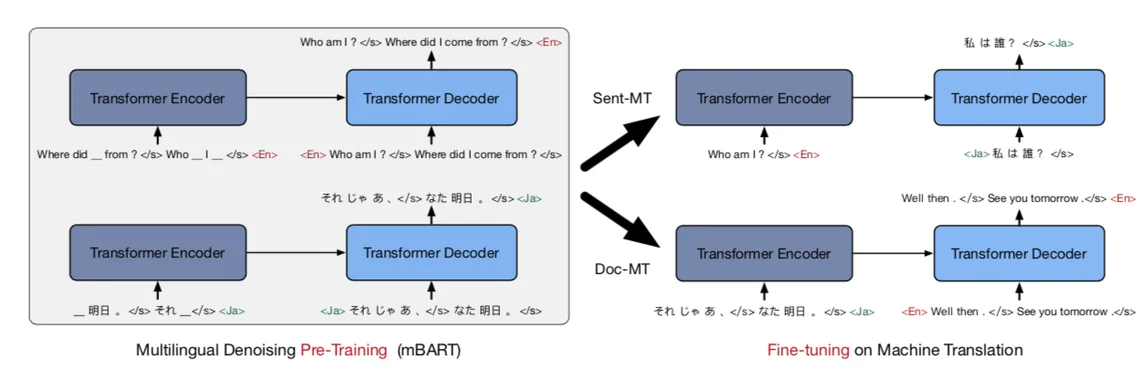
However, if we set something like "tgt" or "src" to language, <unk> token is entered as the encoder's eos and decoder's bos (see code for this). <unk> is returned if there is no such language in the dictionary.
The extension of the file must be specified in language, and for monolingual, the file name must be duplicated because the same extension must be made under the same name. (The source must also be train.ko_KR and the target must also be train.ko_KR.) Although mBART is made for mulitilingual training, it is thought that it is not flexible design that implements monolingual fine tuning impossible.
dict.index(language) -> <unk> -> eos
- append_source_id=True here
- eos set as dictionary.index here
- but [tgt] is not contains in vocab. so
<unk>is returned here
This is not a problem because BART (not mBART) uses tokens such as <s> and </s> as bos and eos, but in mBART, It is a problem because it uses language token like [ko_KR], [ar_AR] as bos and eos. To solve this problem I am implementing mBART monolingaul Seq2Seq task. I'll share it when it's done.
hyunwoongko
on 10 Sep 2020
Right, I see what you mean.
Yes using src and tgt and therefore unk is far from ideal. I'm wondering how much this hurts the performance. Considering also that the
Another solution would be using the same <LID> for both source and target, e.g. [ko_KR]. If I remember correctly there's a check that doesn't allow this, but it can be easily commented out. However I'm not sure if this choice influences other sections or if in general constitutes a problem.
blackcat84
on 10 Sep 2020
The biggest problem is the decoder's bos. [ko_KR] must be entered as initial token (= bos token) for mBART Decoders to properly output Korean. (Because the model learned that way) But when an <unk> token is put into the decoder's bos, the output is very weird. This has a profound effect on performance. When I used the same LID (ko_KR) for both eos and bos using Huggingface's transformers, the NLL loss reached 0.9 for one epoch and output's quaility is very good. but the NLL loss stayed at about 3 to 4 and output is very weird when I used src, tgt as language id with Fairseq
Originally, I was implementing it using a Huggingface transformers, but I have to solve this problem because I am migrating the work to Fairseq in the project that I am currently working with my team members.
hyunwoongko
on 10 Sep 2020
Related issues
 Ir1d
·
3Comments
Ir1d
·
3Comments
 Raghava14
·
3Comments
Raghava14
·
3Comments
 yilegu
·
3Comments
yilegu
·
3Comments
 zqs01
·
3Comments
zqs01
·
3Comments
 galphag
·
3Comments
galphag
·
3Comments
Most helpful comment
The biggest problem is the decoder's bos. [ko_KR] must be entered as initial token (= bos token) for mBART Decoders to properly output Korean. (Because the model learned that way) But when an
<unk>token is put into the decoder's bos, the output is very weird. This has a profound effect on performance. When I used the same LID (ko_KR) for both eos and bos using Huggingface's transformers, the NLL loss reached 0.9 for one epoch and output's quaility is very good. but the NLL loss stayed at about 3 to 4 and output is very weird when I used src, tgt as language id with FairseqOriginally, I was implementing it using a Huggingface transformers, but I have to solve this problem because I am migrating the work to Fairseq in the project that I am currently working with my team members.