🚀 Feature Request
Speed up beam search ~2x by removing unnecessary reorder and merging small ops
Motivation
GPU utility is only ~40% during BART model inference. By profile, I see 2 issues in incremental generation.
- Half of time is used for transfer small data between GPU and CPU when no_repeat_ngram_size > 0. This pattern may apply to other seq2seq models, because the code cause small data transfer is in beam search part, not in model code.
- State reorder use as much time as computation in model forward, and many of these reorder are unnecessary.
Pitch
I created PR #1852 with below changes.
- Copy whole tensor from gpu to cpu once, instead of do it in for loop
- Ban ngram token in one kernel call, instead of in for loop
- Remove unnecessary reorder
In encoder_decoder_attention, reorder only need when batch size change. Because encoder state
is shared across beam size.
Additional context
Inference speed (sample/s) on CNN-DM dataset using V100
| | Before change | After change | Speed up |
|------------------------|-----------------------------------|----------------------------------|----------|
| no_repeat_ngram_size=3 | 3.6 | 6.8 | 1.9X |
| no_repeat_ngram_size=0 | 5.3 | 8.3 | 1.6X |
(beam=4, lenpen=2.0, max_len_b=140, min_len=55)
Profile data to compare before and after change.
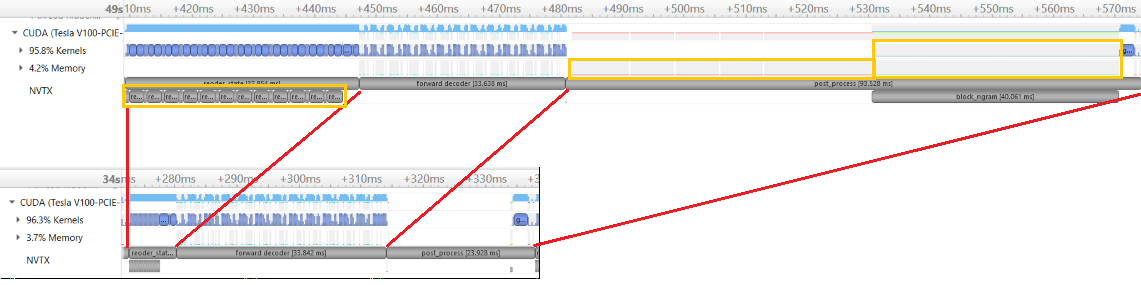
To benchmark the speed, run "CUDA_VISIBLE_DEVICES=0 python generation_speed_test.py".
benchmark code modify from here
cnndm_128.txt
generation_speed_test.py.txt
 yuyan2do
yuyan2do
>All comments
Very nice!
 myleott
on 17 Mar 2020
myleott
on 17 Mar 2020
Related issues
 AranKomat
·
3Comments
AranKomat
·
3Comments
 ashim95
·
3Comments
ashim95
·
3Comments
 Ir1d
·
3Comments
Ir1d
·
3Comments
 jordiae
·
3Comments
jordiae
·
3Comments
 mjpost
·
3Comments
mjpost
·
3Comments
Most helpful comment
Very nice!