Fairseq: DenoisingDataset EOS token not set properly for MultilingualDenoisingTask when --add-lang-token is set
🐛 Bug
The collater function for DenoisingDataset does not set the correct EOS token when used in the MultilingualDenoisingTask.
This is caught in this assertion.
I believe this is because the EOS token is set during the construction of the DenoisingDataset, but the call in the collater function uses self.vocab.eos(). This issue is propagated down to the call to data_utils.collate_tokens.
Even if the parameter is changed from self.vocab.eos() to self.eos, the assertion is still triggered, _e.g._, when the target language is different than the source language, as the two languages have different EOS (_i.e._, language) tokens.
Removing the assertion and changing the relevant code "fixes" the issue, but doesn't seem like the appropriate solution.
To Reproduce
Run fairseq-train using --task multilingual_denoising and --add-lang-token, with data preprocessed in a similar way as cross lingual language model training.
Expected behavior
The eos_idx variable should be set to the correct value in the call to collate.
Environment
- fairseq Version (e.g., 1.0 or master): master
- PyTorch Version (e.g., 1.0): 1.4.0
- OS (e.g., Linux): Linux
- How you installed fairseq (
pip, source): source - Build command you used (if compiling from source):
pip install -e .(in fairseq directory) - Python version: 3.7.4
- CUDA/cuDNN version: N/A
- GPU models and configuration: N/A
- Any other relevant information:
Additional context
I am attempting to train a multilingual denoising model from scratch. I could not find documentation for this in the repository (besides this, which does not contain information on how to train from scratch).
 dkavaler
dkavaler
All 6 comments
Once you have a command working for pretraining a multilingual denoising model could you post it here?
 villmow
on 6 Mar 2020
villmow
on 6 Mar 2020
This recent commit removed the assertion line, but didn't address the core issue of eos_idx being set incorrectly.
In an example vocabulary of size 16384, with --add-lang-token for two languages (adding vocabulary indices 16385 and 16386 to be EOS for each language), in the copy_tensor call prior to setting dst[0] = eos_idx, you see, for example:
dst[0] = 1
eos_idx = 2
src[-1] = 16385
So I believe setting dst[0] = eos_idx is wrong for the above commit; it should be dst[0] = src[-1] if my understanding is correct.
dkavaler
on 15 Apr 2020
I think there is indeed an inconsistency compared to what is described in the paper and how the batches are constructed. However, it is not about the eos token in the source sentences. The langid token is correctly inserted at the end of each sample. Here, the special end_token is added to every sample, _before_ the generic eos token. Maybe the issue was fixed since it was opened. However, there is an issue about the input to the decoder.
I tested the multilingual_denoising task using two small English and German corpora. I also add the --add-lang-token flag. Specifically, this is an example from a small batch.
Note: my vocabulary size is 16000 and the last 3 symbols are:
print(self.task.dictionary.symbols[-3:])
['[de]', '[en]', '<mask>']
Here is the input to the encoder.
> print(sample['net_input']['src_tokens'])
[0, 4093, 16003, 1789, 420, 4498, 15, 51, 63, 6434, 15, 5443, 39, 5475, 45, 934, 5, 16003, 16001]
[0, 1210, 344, 479, 599, 4, 145, 16003, 2249, 22, 832, 59, 796, 7582, 1423, 3567, 5, 16003, 16002]
[0, 1051, 678, 138, 8778, 142, 6461, 333, 8781, 484, 113, 13, 16003, 2002, 9, 2002, 5, 2, 16001]
[0, 1805, 811, 8, 16003, 16003, 218, 248, 13, 833, 4091, 25, 1776, 1048, 4847, 34, 5, 2, 16001]
[0, 148, 3064, 89, 729, 623, 19, 7258, 28, 115, 30, 8, 6332, 665, 16003, 16003, 2, 16001, 1]
[0, 47, 153, 2690, 11, 629, 6, 15, 6, 294, 23, 11411, 190, 18, 16003, 16003, 2, 16002, 1]
[0, 3384, 3195, 4, 8, 2384, 16003, 40, 37, 3210, 1885, 6707, 2279, 2922, 21, 16003, 2, 16001, 1]
[0, 326, 3313, 4, 45, 697, 1830, 29, 16003, 3280, 33, 10, 13395, 27, 16003, 2, 16001, 1, 1]
# devectorized batch
> [" ".join([self.task.dictionary.symbols[t] for t in s]) for s in sample['net_input']['src_tokens']]
['<s>', '▁Leider', '<mask>', '▁Russlands', '▁Er', 'wach', 'en', '▁mit', '▁dem', '▁scheinbar', 'en', '▁Niedergang', '▁des', '▁Westens', '▁ein', 'her', '.', '<mask>', '[de]']
['<s>', '▁On', '▁our', '▁current', '▁course', ',', '▁we', '<mask>', '▁reach', '▁that', '▁point', '▁by', '▁20', '40', '-20', '50', '.', '<mask>', '[en]']
['<s>', '▁Für', '▁At', 'a', 'tür', 'k', '▁gingen', '▁Ver', 'west', 'lich', 'ung', '▁und', '<mask>', '▁Hand', '▁in', '▁Hand', '.', '</s>', '[de]']
['<s>', '▁Nicht', '▁einmal', '▁die', '<mask>', '<mask>', '▁zwischen', '▁Europa', '▁und', '▁Amerika', '▁hält', '▁den', '▁russischen', '▁Einfluss', 'verlust', '▁auf', '.', '</s>', '[de]']
['<s>', '▁Der', '▁letzte', '▁„', 'G', 'am', 'e', '▁Change', 'r', '“', '▁ist', '▁die', '▁künftige', '▁Rolle', '<mask>', '<mask>', '</s>', '[de]', '<pad>']
['<s>', '▁The', '▁other', '▁source', '▁of', '▁dis', 's', 'en', 's', 'ion', '▁is', '▁disagreement', '▁over', '▁a', '<mask>', '<mask>', '</s>', '[en]', '<pad>']
['<s>', '▁Kurz', '▁gesagt', ',', '▁die', '▁wichtigsten', '<mask>', '▁für', '▁eine', '▁nachhaltige', '▁Erholung', '▁Griechenlands', '▁scheinen', '▁gegeben', '▁zu', '<mask>', '</s>', '[de]', '<pad>']
['<s>', '▁An', 'genommen', ',', '▁ein', '▁New', '▁York', 'er', '<mask>', '▁Aktien', '▁an', '▁der', '▁Börse', '▁von', '<mask>', '</s>', '[de]', '<pad>', '<pad>']
Here is the input to the decoder (prev_output_tokens). As you can see, the langid is _not_ added to the input to the decoder, unlike what is described in the paper:
> print(sample['net_input']['prev_output_tokens'])
[2, 0, 4093, 747, 1789, 420, 4498, 15, 51, 63, 6434, 15, 5443, 39, 5475, 45, 934, 5, 2]
[2, 0, 1210, 344, 479, 599, 4, 145, 68, 2249, 22, 832, 59, 796, 7582, 1423, 3567, 5, 2]
[2, 0, 1051, 678, 138, 8778, 142, 6461, 333, 8781, 484, 113, 13, 6620, 2002, 9, 2002, 5, 2]
[2, 0, 1805, 811, 8, 2583, 5633, 218, 248, 13, 833, 4091, 25, 1776, 1048, 4847, 34, 5, 2]
[2, 0, 148, 3064, 89, 729, 623, 19, 7258, 28, 115, 30, 8, 6332, 665, 10, 140, 5, 2]
[2, 0, 47, 153, 2690, 11, 629, 6, 15, 6, 294, 23, 11411, 190, 18, 1162, 593, 5, 2]
[2, 0, 3384, 3195, 4, 8, 2384, 2046, 40, 37, 3210, 1885, 6707, 2279, 2922, 21, 126, 5, 2]
[2, 0, 326, 3313, 4, 45, 697, 1830, 29, 11822, 3280, 33, 10, 13395, 27, 5109, 2248, 5, 2]
# devectorized batch
> [" ".join([self.task.dictionary.symbols[t] for t in s]) for s in sample['net_input']['prev_output_tokens']]
['</s>', '<s>', '▁Leider', '▁geht', '▁Russlands', '▁Er', 'wach', 'en', '▁mit', '▁dem', '▁scheinbar', 'en', '▁Niedergang', '▁des', '▁Westens', '▁ein', 'her', '.', '</s>']
['</s>', '<s>', '▁On', '▁our', '▁current', '▁course', ',', '▁we', '▁will', '▁reach', '▁that', '▁point', '▁by', '▁20', '40', '-20', '50', '.', '</s>']
['</s>', '<s>', '▁Für', '▁At', 'a', 'tür', 'k', '▁gingen', '▁Ver', 'west', 'lich', 'ung', '▁und', '▁Modernisierung', '▁Hand', '▁in', '▁Hand', '.', '</s>']
['</s>', '<s>', '▁Nicht', '▁einmal', '▁die', '▁wachsende', '▁Kluft', '▁zwischen', '▁Europa', '▁und', '▁Amerika', '▁hält', '▁den', '▁russischen', '▁Einfluss', 'verlust', '▁auf', '.', '</s>']
['</s>', '<s>', '▁Der', '▁letzte', '▁„', 'G', 'am', 'e', '▁Change', 'r', '“', '▁ist', '▁die', '▁künftige', '▁Rolle', '▁der', '▁USA', '.', '</s>']
['</s>', '<s>', '▁The', '▁other', '▁source', '▁of', '▁dis', 's', 'en', 's', 'ion', '▁is', '▁disagreement', '▁over', '▁a', '▁bank', '▁tax', '.', '</s>']
['</s>', '<s>', '▁Kurz', '▁gesagt', ',', '▁die', '▁wichtigsten', '▁Bedingungen', '▁für', '▁eine', '▁nachhaltige', '▁Erholung', '▁Griechenlands', '▁scheinen', '▁gegeben', '▁zu', '▁sein', '.', '</s>']
['</s>', '<s>', '▁An', 'genommen', ',', '▁ein', '▁New', '▁York', 'er', '▁kauft', '▁Aktien', '▁an', '▁der', '▁Börse', '▁von', '▁Bomb', 'ay', '.', '</s>']
In the paper, it is said that the langid token should also be included as input to the decoder:
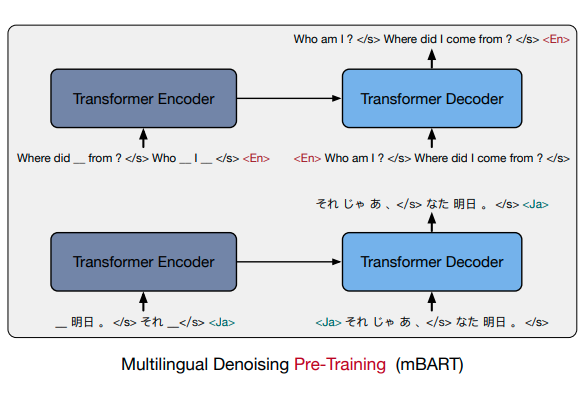
Can you please clarify whether this is a mistake in the paper or a bug in the implementation?
 cbaziotis
on 9 May 2020
cbaziotis
on 9 May 2020
I would be really glad if you found a solution to this issue.
 redionxhepa
on 11 May 2020
redionxhepa
on 11 May 2020
In practice, I am not sure whether this is important, because even in Google's latest paper about massively multilingual NMT they just prepend a target language token to every source sequence.
That being said, there is definitely a discrepancy between the current implementation in master and what is described in the paper (both in the text and in the figure). It would be nice to get a definitive answer from someone that was involved in the project and knows more...
cbaziotis
on 11 May 2020
@dkavaler @villmow Hi, Were you able to successfully pre-train the model. If so can you please explain how?
 rishab-32
on 25 Jun 2020
rishab-32
on 25 Jun 2020
Related issues
 zqs01
·
3Comments
zqs01
·
3Comments
 Ir1d
·
3Comments
Ir1d
·
3Comments
 kr-sundaram
·
3Comments
kr-sundaram
·
3Comments
 gaopengcuhk
·
3Comments
gaopengcuhk
·
3Comments
 ashim95
·
3Comments
ashim95
·
3Comments