Fairseq: OOM while trying to train BART
🐛 Bug
To Reproduce
Tried to finetune BART using same configuration mentioned here
https://github.com/pytorch/fairseq/blob/master/examples/bart/README.cnn.md
Was using 4 11GB 2080Ti , tried 3 , 2 none helps
Realized the batch size used by you folks is 2048 (max_tokens) reduced it to 16 still getting OOM
The issue is OOM but due to optimization
It runs fine on 1 single GPU though
Environment
- fairseq Version (e.g., 1.0 or master):
- PyTorch Version (e.g., 1.0) 1.3.1 pytorchgpu
- OS (e.g., Linux):
- How you installed fairseq (
pip, source): - Build command you used (if compiling from source):
- Python version: 3.7
- CUDA/cuDNN version: 10.0
- GPU models and configuration: 4 11 GB 2080 TitanX
 tuhinjubcse
tuhinjubcse
All 5 comments
@myleott can you please help ? I literally cannot debug this
tuhinjubcse
on 24 Jan 2020
TOTAL_NUM_UPDATES=20000
WARMUP_UPDATES=500
LR=3e-05
MAX_TOKENS=256
UPDATE_FREQ=4
BART_PATH=/lfs1/tuhinc/fairseq/bart.large/model.pt
python train.py feverwiki
--restore-file $BART_PATH
--max-tokens $MAX_TOKENS
--task translation
--source-lang source --target-lang target
--truncate-source
--layernorm-embedding
--share-all-embeddings
--share-decoder-input-output-embed
--reset-optimizer --reset-dataloader --reset-meters
--required-batch-size-multiple 1
--arch bart_large
--criterion label_smoothed_cross_entropy
--label-smoothing 0.1
--dropout 0.1 --attention-dropout 0.1
--weight-decay 0.01 --optimizer adam --adam-betas "(0.9, 0.999)" --adam-eps 1e-08
--clip-norm 0.1
--lr-scheduler polynomial_decay --lr $LR --total-num-update $TOTAL_NUM_UPDATES --warmup-updates $WARMUP_UPDATES
--fp16 --update-freq $UPDATE_FREQ
--skip-invalid-size-inputs-valid-test
--find-unused-parameters;
Using this to train
tuhinjubcse
on 24 Jan 2020
2.8308e-12], device='cuda:0')
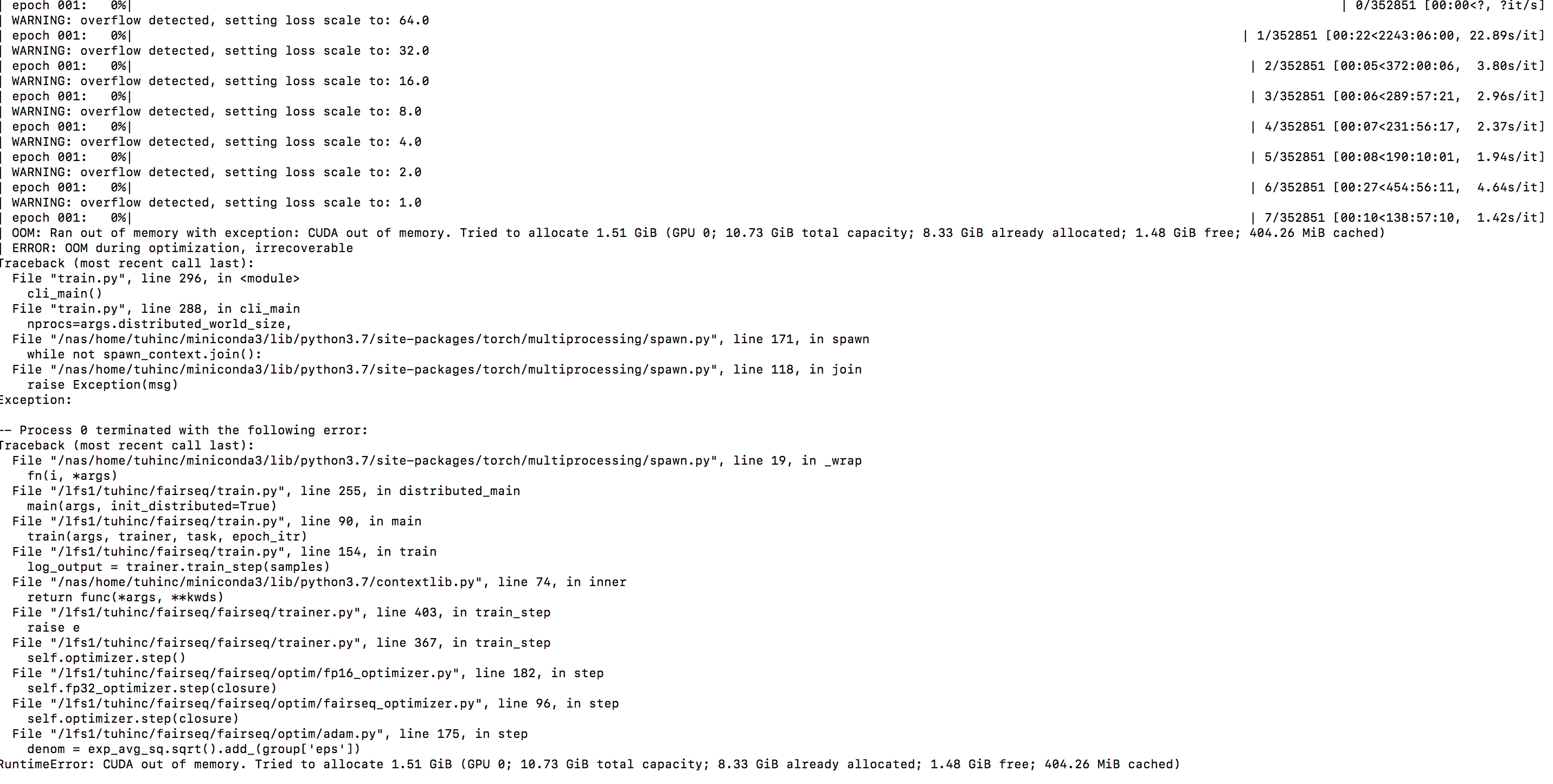
| OOM: Ran out of memory with exception: CUDA out of memory. Tried to allocate 1.51 GiB (GPU 0; 10.73 GiB total capacity; 8.33 GiB already allocated; 1.42 GiB free; 458.76 MiB cached)
| ERROR: OOM during optimization, irrecoverable
Traceback (most recent call last):
File "train.py", line 296, in
cli_main()
File "train.py", line 288, in cli_main
nprocs=args.distributed_world_size,
File "/nas/home/tuhinc/miniconda3/lib/python3.7/site-packages/torch/multiprocessing/spawn.py", line 171, in spawn
while not spawn_context.join():
File "/nas/home/tuhinc/miniconda3/lib/python3.7/site-packages/torch/multiprocessing/spawn.py", line 118, in join
raise Exception(msg)
Exception:
-- Process 0 terminated with the following error:
Traceback (most recent call last):
File "/nas/home/tuhinc/miniconda3/lib/python3.7/site-packages/torch/multiprocessing/spawn.py", line 19, in _wrap
fn(i, args)
File "/lfs1/tuhinc/fairseq/train.py", line 255, in distributed_main
main(args, init_distributed=True)
File "/lfs1/tuhinc/fairseq/train.py", line 90, in main
train(args, trainer, task, epoch_itr)
File "/lfs1/tuhinc/fairseq/train.py", line 154, in train
log_output = trainer.train_step(samples)
File "/nas/home/tuhinc/miniconda3/lib/python3.7/contextlib.py", line 74, in inner
return func(args, **kwds)
File "/lfs1/tuhinc/fairseq/fairseq/trainer.py", line 403, in train_step
raise e
File "/lfs1/tuhinc/fairseq/fairseq/trainer.py", line 367, in train_step
self.optimizer.step()
File "/lfs1/tuhinc/fairseq/fairseq/optim/fp16_optimizer.py", line 182, in step
self.fp32_optimizer.step(closure)
File "/lfs1/tuhinc/fairseq/fairseq/optim/fairseq_optimizer.py", line 96, in step
self.optimizer.step(closure)
File "/lfs1/tuhinc/fairseq/fairseq/optim/adam.py", line 177, in step
denom = exp_avg_sq.sqrt().add_(group['eps'])
RuntimeError: CUDA out of memory. Tried to allocate 1.51 GiB (GPU 0; 10.73 GiB total capacity; 8.33 GiB already allocated; 1.42 GiB free; 458.76 MiB cached)
tuhinjubcse
on 24 Jan 2020
Since you have tried reducing max_tokens, I am not sure if much can be done here to make it fit into 11GiB GPU memory.
Can you try, switching to --memory-efficient-fp16 instead of --fp16?
 ngoyal2707
on 24 Jan 2020
ngoyal2707
on 24 Jan 2020
Thanks @ngoyal2707 worked like a charm :) You guys might mention this on the BART CNNDM finetuning page
tuhinjubcse
on 24 Jan 2020
Related issues
 PhilippeMarcotte
·
3Comments
PhilippeMarcotte
·
3Comments
 yilegu
·
3Comments
yilegu
·
3Comments
 mjpost
·
3Comments
mjpost
·
3Comments
 kyquang97
·
3Comments
kyquang97
·
3Comments
 zhaoxv
·
3Comments
zhaoxv
·
3Comments
Most helpful comment
Thanks @ngoyal2707 worked like a charm :) You guys might mention this on the BART CNNDM finetuning page