Fairseq: Camembert config and pytorch model
❓ Questions and Help
Hi @louismartin ,
I have read your paper and huggingface library about Camembert and it is very interesting!
I'm training a new RoBERTa model with fairseq library based also on the suggestions of your paper and I obtained the following files:
- dict.txt: vocabulary coming from the sentencepiece model
- sentencepiece.bpe.model
- checkpoint_best.pt
However when I'm trying to load the model through the hugging face library CamembertModel as following:
model_path = "directory/to/checkpoints"
model = CamembertModel.from_pretrained(model_path)
I get errors related to missing config.json file and pytorch_model.bin.
How did you get these files?
Currently, using the config.json from roberta (changing the vocabulary size) and saving my file checkpoint_best.py as pytorch_model.bin I resolved the errors but I'm not sure whether this approach is correct.
Could you provide more informations about it?
Thanks in advance!
 LeoDeep
LeoDeep
All 20 comments
You probably need to use the conversion script in the transformers library: https://github.com/huggingface/transformers/blob/master/transformers/convert_roberta_original_pytorch_checkpoint_to_pytorch.py
 myleott
on 17 Dec 2019
myleott
on 17 Dec 2019
You probably need to use the conversion script in the transformers library: https://github.com/huggingface/transformers/blob/master/transformers/convert_roberta_original_pytorch_checkpoint_to_pytorch.py
Exactly, the config.json file is created with this conversion script
 louismartin
on 17 Dec 2019
louismartin
on 17 Dec 2019
Thanks for the reply. I tried the script; however when I run the assert line 81
assert(roberta_layer.self_attn.in_proj_weight.shape == torch.Size((3 * config.hidden_size, config.hidden_size)))
It gives me an attribute error: AttributeError: 'MultiheadAttention' object has no attribute 'in_proj_weight'
Should I install a specific version of transformers or fairseq?
Furthermore, in the script snippet
config = BertConfig(
vocab_size=50265,
hidden_size=roberta.args.encoder_embed_dim,
num_hidden_layers=roberta.args.encoder_layers,
num_attention_heads=roberta.args.encoder_attention_heads,
intermediate_size=roberta.args.encoder_ffn_embed_dim,
max_position_embeddings=514,
type_vocab_size=1,
layer_norm_eps=1e-5, # PyTorch default used in fairseq
)
a vocab_size of 50265 is hard coded. I changed it based on my vocab size but maybe It would be awesome to set it as a parameter.
Thanks again for everything!
LeoDeep
on 17 Dec 2019
Hi @LeoDeep and all,
There's a known issue with the huggingface/transformers converter that will be resolved soon. Will also post here when done. Cheers!
 julien-c
on 17 Dec 2019
julien-c
on 17 Dec 2019
Thanks for your reply @julien-c . I will keep looking at the issue in order to stay updated on the topic. Cheers to all and thanks for what you are doing
LeoDeep
on 17 Dec 2019
Hi @LeoDeep this is now fixed on master by https://github.com/huggingface/transformers/pull/1959
julien-c
on 18 Dec 2019
Hi @julien-c thanks for the update!
The script now is working like a charm.
Then I successfully loaded the model with the standard procedure as follow:
model = RobertaModel.from_pretrained("/content/model_folder")
I just have a concern when using the model RobertaForMaskedLM with
modelMaskedLM = RobertaForMaskedLM.from_pretrained('/content/pytorch_dump_folder')
The config files is loaded correctly but I receive some Info warnings about weights not initialized and used:
INFO:transformers.modeling_utils:loading weights file /content/pytorch_dump_folder/pytorch_model.bin
INFO:transformers.modeling_utils:Weights of RobertaForMaskedLM not initialized from pretrained model: ["lm_head.decoder.weight"]
INFO:transformers.modeling_utils:Weights from pretrained model not used in RobertaForMaskedLM: ["lm_head.weight"]
Reading https://github.com/huggingface/transformers/blob/master/transformers/modeling_utils.py (line 67) it makes sense not having some initialized weights for example if I'm loading the model for a SequenceClassificationTask. However, since the conversion script initializes a RobertaMaskedLM (I didn't use the classification head parameter) does it comes already with this weights? Should they be already availble from my saved pytorch_model.bin file?
Additional Info: I have the same behaviour when loading the standard roberta-base model.
Thanks again!
LeoDeep
on 18 Dec 2019
Which checkpoint exactly are you loading?
[If you want, you can share the checkpoint using our newly released [upload CLI](https://github.com/huggingface/transformers#Quick-tour-of-model-sharing)]
julien-c
on 18 Dec 2019
The process that I'm using is:
- Taking checkpoint_best.pt from Roberta training (trained using the standard procedure fairseq-train https://github.com/pytorch/fairseq/blob/master/examples/roberta/README.pretraining.md
- Convert it in config.json and pytorch_model.bin through the new updated scripts
- Loading with
modelMaskedLM = RobertaForMaskedLM.from_pretrained("pytorch_dump_folder")
Then I receive the INFO warning described. I also checked the lines (138 to 143) here where weights from roberta are passed to hugging face model and it looks everything correct.
I don't know if this strange behaviour is related to my checkpoint but I received the warning even if I'm running your default roberta-base files:
modelTest = RobertaForMaskedLM.from_pretrained("roberta-base")
This is the output:
INFO:transformers.modeling_utils:loading weights file https://s3.amazonaws.com/models.huggingface.co/bert/roberta-base-pytorch_model.bin from cache at /root/.cache/torch/transformers/228756ed15b6d200d7cb45aaef08c087e2706f54cb912863d2efe07c89584eb7.49b88ba7ec2c26a7558dda98ca3884c3b80fa31cf43a1b1f23aef3ff81ba344e
INFO:transformers.modeling_utils:Weights of RobertaForMaskedLM not initialized from pretrained model: ['lm_head.decoder.weight']
INFO:transformers.modeling_utils:Weights from pretrained model not used in RobertaForMaskedLM: ['lm_head.weight']
I just have found also another issue here https://github.com/huggingface/transformers/issues/2202 that is reporting the same behaviour.
LeoDeep
on 18 Dec 2019
Thanks for investigating! This is now fixed, cf. https://github.com/huggingface/transformers/issues/2202
julien-c
on 19 Dec 2019
Tested and It works perfectly. I think it's time to close this issue!
Thanks again for your everything. Cheers to all!
LeoDeep
on 20 Dec 2019
Is there a way to convert from a PyTorch bin (obtained with Huggin Face) to a Roberta model? When I run this script:
from fairseq.models.roberta import RobertaModel
roberta= RortaModel.from_pretrained('/path/to/checkpoint/folder/',checkpoint_file='pytorch_model.bin')
I got this error:
File "/usr/local/lib/python3.6/dist-packages/fairseq/checkpoint_utils.py", line 162, in load_checkpoint_to_cpu
args = state["args"]
KeyError: 'args'
I think I have the opposite problem
 paulthemagno
on 20 Dec 2019
paulthemagno
on 20 Dec 2019
Indeed there's no conversion script in the opposite direction.
It should be pretty easy to do it yourself though.
julien-c
on 20 Dec 2019
@julien-c great thread this has come out to be.
What I want to do is pretrain Roberta from scratch using G-Cloud tpu with fairseq.
Then convert those .pt weights to pytorch.bin
What I want is I am using tensorflow or inference.
I convert pytorch.bin weights to tf_model.h5 right ?
OR can I directly convert .pt model to tensorflow_model.h5 etc ?
Thanks
 muhammadfahid51
on 22 Apr 2020
muhammadfahid51
on 22 Apr 2020
Hi, I try to use the camembert-base model in order to fine tune it on my data. But I'm facing the same issue.
I downloaded camembert-base and in the folder I had the following files : dict.txt, model.pt and sentencepiece.bpe.model.
But When I launched this line :
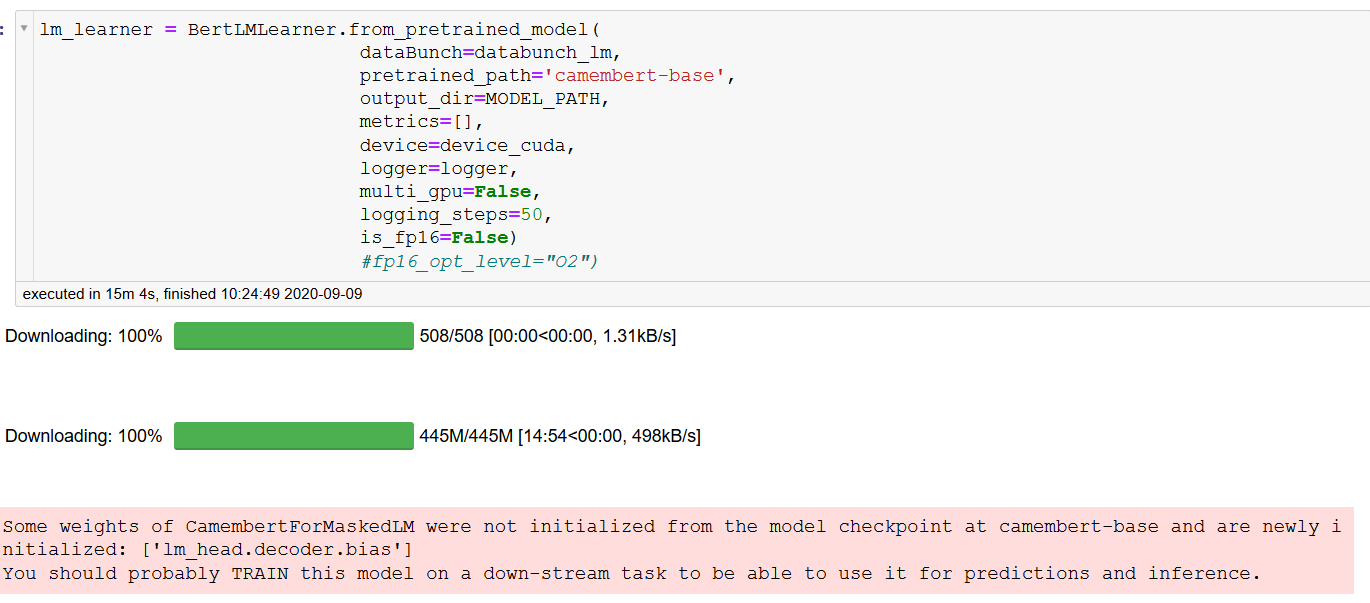
lm_learner = BertLMLearner.from_pretrained_model(
dataBunch=databunch_lm,
pretrained_path='model/camembert-base',
output_dir=MODEL_PATH,
metrics=[],
device=device_cuda,
logger=logger,
multi_gpu=False,
logging_steps=50,
is_fp16=False)
An error occured telling me that the config.json and pytorch_model.bin are missing. So I went to the git repo and I found the file configuration_camembert.py and found the following link : "camembert-base": "https://s3.amazonaws.com/models.huggingface.co/bert/camembert-base-config.json" where I got the config.json. And for the pytorch.bin model as I didn't find the file convert_camembert_to_pytorch I just went on this link "https://s3.amazonaws.com/models.huggingface.co/bert/camembert-base-pytorch_model.bin" and I found it. Why the convert file is missing for camembert-base but available for the other models (bert, roberta ...)
After I've done that I could launch the previous code but I faced this warning :
Some weights of CamembertForMaskedLM were not initialized from the model checkpoint at model/camembert-base and are newly initialized: ['lm_head.decoder.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Any suggestions, please ?
Thanks in advance for your answers :)
 Yasminabouzbiba
on 8 Sep 2020
Yasminabouzbiba
on 8 Sep 2020
Did you try using the default 'camembert-base' shortcut instead of downloading the model manually and providing the full path 'model/camembert-base'?
lm_learner = BertLMLearner.from_pretrained_model( dataBunch=databunch_lm, pretrained_path='camembert-base', output_dir=MODEL_PATH, metrics=[], device=device_cuda, logger=logger, multi_gpu=False, logging_steps=50, is_fp16=False)
The warning is not a problem I think, it only says that the bias of the decoder of the lm head is initialized at random but it's not a problem if you are going to finetune it on your own data.
louismartin
on 9 Sep 2020
Yes I tried the default "camembert-base" shortcut and I face the same warning.
I'm just a bit worried that the model would be less performant with this warning, don't you think ?
Yasminabouzbiba
on 9 Sep 2020
The lm_head.decoder.bias is probably composed of very few weights so I don't think it's a problem.
louismartin
on 9 Sep 2020
@paulthemagno did you end up writing code for a conversion in the opposite direction? If so, it would be great if you could share it :)
 manueltonneau
on 5 Oct 2020
manueltonneau
on 5 Oct 2020
@paulthemagno same here. I also need a script in the opposite direction.
 ajmeraji
on 5 Nov 2020
ajmeraji
on 5 Nov 2020
Related issues
 galphag
·
3Comments
galphag
·
3Comments
 kr-sundaram
·
3Comments
kr-sundaram
·
3Comments
 mjpost
·
3Comments
mjpost
·
3Comments
 ajesujoba
·
3Comments
ajesujoba
·
3Comments
 kyquang97
·
3Comments
kyquang97
·
3Comments
Most helpful comment
Thanks for investigating! This is now fixed, cf. https://github.com/huggingface/transformers/issues/2202