Fairseq: Why change sequence order of prev_output_tokens in BART?
Hi,
In the extract_features example of BART (link to code), both src_tokens (for encoder) and prev_output_tokens (for decoder) are fed into model, but prev_output_tokens is just the src_tokens with EOS being moved to the beginning. I think during training (teacher forcing) the prev_output_tokens starts with BOS, doesn't it?
So what's the purpose of this reorder? To add some deliberate noise, or assuming there's another sentence before it?
Thanks in advance.
Rui
 memray
memray
All 16 comments
@memray
It's similar to how we do teacher_forcing during training also by rolling the src_tokens by 1 token here where we define move_eos_to_beginning.
The purpose is not for noising, just teacher forcing as you mentioned.
 ngoyal2707
on 19 Nov 2019
ngoyal2707
on 19 Nov 2019
@ngoyal2707
Is it possible to have more details ? I'm also confused, and your link lead to fairinternal, I don't have access to it 😢
From the paper it seems that BOS is used :
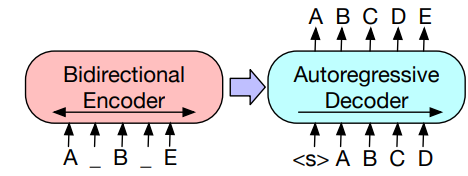
(<s> is used, and not </s>)
 astariul-colanim
on 20 Nov 2019
astariul-colanim
on 20 Nov 2019
https://github.com/pytorch/fairseq/blob/master/fairseq/data/language_pair_dataset.py#L63 is the fixed link.
Ahh I see, so actually the input format to encoder for above case is actually:
<s> A <mask> B <mask> E </s>
and Decoder input:
</s> <s> A B C D E
And target:
<s> A B C D E </s>
We will look into updating those figures. Thanks for pointing it out.
ngoyal2707
on 20 Nov 2019
Thanks for the very clear explanation !
astariul-colanim
on 20 Nov 2019
@ngoyal2707 Thank you for the response! So I guess the 1st input word to the decoder is dummy, which means we can just leave the target sequence as is (don't need to remove the heading <s>)?
memray
on 20 Nov 2019
Ahh I see, so actually the input format to encoder for above case is actually:
<s> A <mask> B <mask> E </s>and Decoder input:
</s> <s> A B C D EAnd target:
<s> A B C D E </s>
@ngoyal2707 @yinhanliu
I think your example is not completely right...
After printing sample['target'] and sample['net_input']['prev_output_tokens'], this is what I got :
sample['target'] : A B C D E </s>
sample['net_input']['prev_output_tokens'] : </s> A B C D E
I think it works perfectly (we don't actually need to use <s>) for teacher forcing, but I think it's necessary to clarify it.
<s> is not used, only </s> is used for the decoder.
astariul-colanim
on 16 Dec 2019
I think your example is not completely right...
After printing
sample['target']andsample['net_input']['prev_output_tokens'], this is what I got :
sample['target']:A B C D E </s>
sample['net_input']['prev_output_tokens']:</s> A B C D EI think it works perfectly (we don't actually need to use
<s>) for teacher forcing, but I think it's necessary to clarify it.
<s>is not used, only</s>is used for the decoder.
I think what you say is only valid during fine-tuning. In the CNN example, the bart model is fine-tuned using the translation task, which loads a LanguagePair dataset without prepending BOS.
@ngoyal2707 Could you provide a bash command that you used to pre-train BART? I assume you used the denoising task, which loads a DenoisingDataset, but first prepends BOS to any sample. See these two lines:
https://github.com/pytorch/fairseq/blob/7e4c1a4b6a40d0c6cde638dc2c7f2eeb459bc7fb/fairseq/tasks/denoising.py#L138-L139
It will then be rearranged for teacher forcing by moving the EOS token before the BOS symbol:
https://github.com/pytorch/fairseq/blob/7e4c1a4b6a40d0c6cde638dc2c7f2eeb459bc7fb/fairseq/data/denoising_dataset.py#L50-L54
So the input during pretraining is as @ngoyal2707 stated here: https://github.com/pytorch/fairseq/issues/1389#issuecomment-555798615 and during fine-tuning it is the way @Colanim described.
Can you explain why you use the BOS symbol at all? Is it really necessary or could you pretrain without it?
 villmow
on 23 Dec 2019
villmow
on 23 Dec 2019
@villmow prepend_bos is an arg that you can always set into True. We don't observe that much difference when we set that into True/False. that is said, the fine-tune process will learn the no-bos (a difference between ft and pretrain). You can set it True, you might see a repetitive tokens for the first two positions, in this case, you need to add a trick to the generation code that force the first token always to be BOS and force the second to not be BOS. We are not sure why this happens though.
 yinhanliu
on 23 Dec 2019
yinhanliu
on 23 Dec 2019
Thanks @villmow & @yinhanliu for the clarifications.
There is still something I don't understand.
Ok, the pretraining procedure and the fine-tuning procedure is different, there is no <s> at fine-tuning time.
But still, as mentioned in #1517, the hub interface always add <s> when encoding text.
Since evaluation of the downstream tasks is done through this interface, we have a discrepancy between fine-tuning _training_ and _testing_.
However, I tried to modify this behavior to be consistent (=> remove <s> at testing time) and the results were almost the same (actually a bit _lower_).
I believe the impact is minimal.
astariul-colanim
on 24 Dec 2019
@Colanim @villmow
1) our release cnn/dm model was fine-tuned with bos. But you can totally remove bos during fine-tune and it works as well. The only thing you want to make sure is that if you don't have bos in fine-tune then don't use it in test, if you do use in fine-tune, then keep it in test.
2) Pretrain doesn't need bos at all. Bos was a concept from Roberta, and turned out not necessary at all.
yinhanliu
on 24 Dec 2019
@yinhanliu How can I remove BOS at testing time ?
I tried changing this line :
https://github.com/pytorch/fairseq/blob/7e4c1a4b6a40d0c6cde638dc2c7f2eeb459bc7fb/fairseq/models/bart/hub_interface.py#L67
into this line :
bpe_sentence = tokens + ' </s>'
But as I mentioned earlier, it didn't work : results are actually a bit weaker...
astariul-colanim
on 24 Dec 2019
@villmow prepend_bos is an arg that you can always set into True. We don't observe that much difference when we set that into True/False.
Hi, thanks for your answer. I just wondered, as you can't control it with a command line argument. Did you change it manually in code during experiments?
So what your saying is, that one should not use the BOS symbol during pre-training. Results are the same, and you would not need to remove it during fine-tuning?
@Colanim :
@yinhanliu How can I remove
BOSat testing time ?
But as I mentioned earlier, it didn't work : results are actually a bit weaker...
@yinhanliu said that the model is fine-tuned using the BOS symbol, so you should not remove it during test time. If you want to fine-tune the model on your own, you can decide to remove it. It should not have any impact.
villmow
on 26 Dec 2019
@villmow Currently, BART is pretrained with BOS, but finetuned without BOS. I finetuned my own checkpoint, so at test time I need to remove BOS to be consistent with the finetuning procedure. But yes you are right, we should also keep a way to keep BOS, for checkpoints that used BOS during training.
astariul-colanim
on 27 Dec 2019
@Colanim thanks, I didn't run it myself just thought they had released the fine-tuned checkpoint. My mistake!
@ngoyal2707 @yinhanliu I have maybe found another inconsistency and just wanted to ask why you do it that way. In the DenoisingDatasets collate you default left_pad_source to False (with no option to change it via arguments).
https://github.com/pytorch/fairseq/blob/cae55599a91d6ff21544c70f9cb92544cce6c342/fairseq/data/denoising_dataset.py#L18
Does that mean you right pad the source sequence in BART? Usually translation models are trained by left padding source. Any reason you differ from that? Is it because you train on token blocks, that already have minimal amount of padding?
However, during fine-tuning when using the translation task the command you provide will per default left pad source.
villmow
on 28 Dec 2019
@villmow either left or right padding shouldn't matter in source side since there is padding mask in decoder to encoder attention. However, it is definitely something we should keep consistent in both tasks. Thanks for pointing this out to us.
yinhanliu
on 29 Dec 2019
Thanks @villmow & @yinhanliu for the clarifications.
There is still something I don't understand.
Ok, the pretraining procedure and the fine-tuning procedure is different, there is no<s>at fine-tuning time.But still, as mentioned in #1517, the hub interface always add
<s>when encoding text.Since evaluation of the downstream tasks is done through this interface, we have a discrepancy between fine-tuning _training_ and _testing_.
However, I tried to modify this behavior to be consistent (=> remove
<s>at testing time) and the results were almost the same (actually a bit _lower_).
I believe the impact is minimal.
@Colanim
do you finally solve this problem? I mean if I fine tune without using bos token, can I change the test procedure as yours to remove the bos token? Does the result perform well?
 zixiliuUSC
on 23 Apr 2020
zixiliuUSC
on 23 Apr 2020
Related issues
 kyquang97
·
3Comments
kyquang97
·
3Comments
 gaopengcuhk
·
3Comments
gaopengcuhk
·
3Comments
 ashim95
·
3Comments
ashim95
·
3Comments
 chengfx
·
3Comments
chengfx
·
3Comments
 galphag
·
3Comments
galphag
·
3Comments
Most helpful comment
@Colanim @villmow
1) our release cnn/dm model was fine-tuned with bos. But you can totally remove bos during fine-tune and it works as well. The only thing you want to make sure is that if you don't have bos in fine-tune then don't use it in test, if you do use in fine-tune, then keep it in test.
2) Pretrain doesn't need bos at all. Bos was a concept from Roberta, and turned out not necessary at all.