Fairseq: In fairseq Version 0.7.1, whether multiple GPUs can only share one copy of data in memory
 dongdaoking
dongdaoking
All 4 comments
Is your goal to improve memory usage and/or train on larger datasets?
If you use --dataset-impl lazy --fix-batches-to-gpus then each process should only load the data it needs.
Alternatively you should also try --dataset-impl mmap. That will require preprocessing your dataset again (with fairseq-preprocess --dataset-impl mmap (...)), but will significantly reduce memory usage and maybe also storage requirements.
Finally you can simply split your data and pass a colon-separated list of dataset as the data argument. Fairseq will cycle over each split as if it were an epoch. For example fairseq-train data-dir1:data-dir2:data-dir3 (...)
 myleott
on 17 Jul 2019
myleott
on 17 Jul 2019
Yes, i need to load larger datasets for multiple GPUs. Your ideas help a lot and thanks for your reply.
dongdaoking
on 18 Jul 2019
Hi @myleott, I was having memory problems and able to use --dataset-impl lazy --fix-batches-to-gpus successfully on a 7-gpu server w/ 24GB of memory.
The problem I have now is that training is very slow (24 hours per half an epoch). What is the difference between the two arguments? Do you have any suggestions?
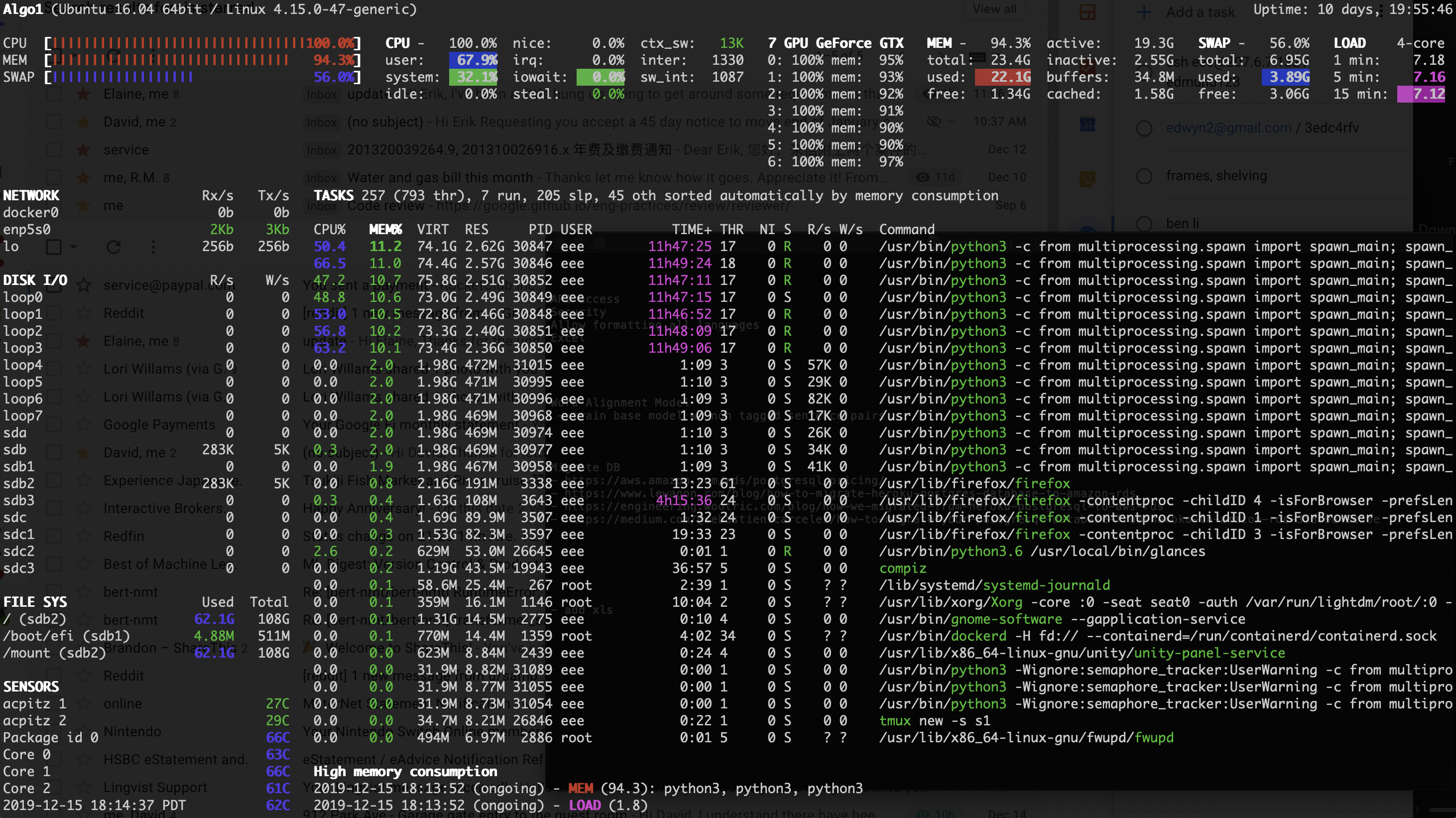
Including a screenshot of my server resources during this slow training:
 echan00
on 16 Dec 2019
echan00
on 16 Dec 2019
This is quite stale. We've since introduced --dataset-impl=mmap, which is the default. Please preprocess your data using the latest fairseq and it should scale much better with large datasets.
myleott
on 16 Dec 2019
Related issues
 jordiae
·
3Comments
jordiae
·
3Comments
 zhaoxv
·
3Comments
zhaoxv
·
3Comments
 mjpost
·
3Comments
mjpost
·
3Comments
 ajesujoba
·
3Comments
ajesujoba
·
3Comments
 Raghava14
·
3Comments
Raghava14
·
3Comments
Most helpful comment
Is your goal to improve memory usage and/or train on larger datasets?
If you use
--dataset-impl lazy --fix-batches-to-gpusthen each process should only load the data it needs.Alternatively you should also try
--dataset-impl mmap. That will require preprocessing your dataset again (withfairseq-preprocess --dataset-impl mmap (...)), but will significantly reduce memory usage and maybe also storage requirements.Finally you can simply split your data and pass a colon-separated list of dataset as the
dataargument. Fairseq will cycle over each split as if it were an epoch. For examplefairseq-train data-dir1:data-dir2:data-dir3 (...)