Fairseq: Is there any comparison experiments with "Sparse Transformers"
Recently, there is a new tech named Sparse Transformers, is there anyone who wanna design the comparison studies? i.e., Dynamic Conv vs. Sparse Transformers
 alphadl
alphadl
All 4 comments
BTW, I am conducting the experiment on newstest-2018-fi-en test set by using WMT2019 fi-en processed parallel dataset (I participated in the WMT2019 fi-en task this year). I wanna validate the superiority of DynamicConv compared with standard Transformer on the same dataset under same pre-processing settings, due to the limitations of computing power(I have only 2*2080ti), I choose the configuration below:
#training
MODEL="./models/dynamic_conv_wmt19fi2en"
mkdir -p $MODEL
python -m torch.distributed.launch --nproc_per_node 2 $(which fairseq-train) \
wmt19-bin/wmt19.bpe.fien \
--fp16 --log-interval 100 --log-format tqdm --tensorboard-logdir ./runs/ \
--max-tokens 50 --max-tokens 4000 --max-update 100000 --optimizer adam \
--adam-betas '(0.9,0.98)' --lr-scheduler inverse_sqrt \
--clip-norm 0.0 --weight-decay 0.0 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--min-lr 1e-09 --update-freq 16 --attention-dropout 0.1 --keep-last-epochs 10 \
--ddp-backend=no_c10d --lr-scheduler cosine --warmup-init-lr 1e-7 --warmup-updates 10000 \
--lr-shrink 1 --max-lr 0.001 --lr 1e-7 --min-lr 1e-9 \
--t-mult 1 --lr-period-updates 20000 \
--arch lightconv_iwslt_de_en --save-dir $MODEL \
--dropout 0.3 --attention-dropout 0.1 --weight-dropout 0.1 \
--encoder-glu 1 --decoder-glu 1
and the training process seems good, like below~
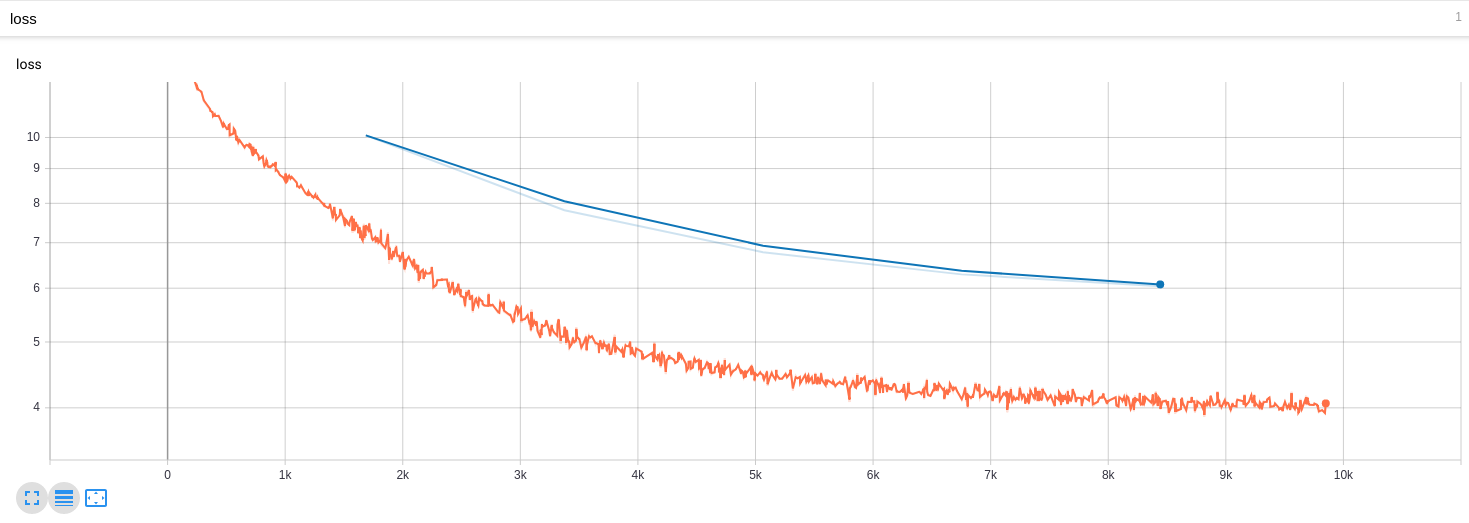
And finally, I use the best single model to evaluate, the BLEU score=18.86, 52.2/ 25.1/ 13.9/ 7.9
However, my own baseline system trained with standard Transformer with the same dataset, pre-processing settings, I evaluate this model with a single model, in which I got BLEU socre=22.97, 56.7/ 29.9/ 18.0/ 11.2.
There exists a big gap in BLEU score, So I am wondering if there are any misconducts in my simple comparison experiment with vanilla Transformer model.
alphadl
on 24 Apr 2019
Will the author or other staffs response my doubt? : (
alphadl
on 6 May 2019
Can you try the dynamic conv architecture instead of "lightconv_iwslt_de_en"? Also, this is a small architecture- are you training Transformer base? The IWSLT lightconv has a lot less parameters.
 huihuifan
on 13 May 2019
huihuifan
on 13 May 2019
As the limitation of computation resources, I only trained lightconv and compared with the transformer_base model, they were fed the same data~ Although lightconv is reported lower than dynamic in the paper, I think it still should outperform the Transformer_base model~ but in my experiments, it isn't
alphadl
on 14 May 2019
Related issues
 AranKomat
·
3Comments
AranKomat
·
3Comments
 ajesujoba
·
3Comments
ajesujoba
·
3Comments
 mali-nuist
·
3Comments
mali-nuist
·
3Comments
 PhilippeMarcotte
·
3Comments
PhilippeMarcotte
·
3Comments
 tyoc213
·
3Comments
tyoc213
·
3Comments
Most helpful comment
BTW, I am conducting the experiment on newstest-2018-fi-en test set by using WMT2019 fi-en processed parallel dataset (I participated in the WMT2019 fi-en task this year). I wanna validate the superiority of DynamicConv compared with standard Transformer on the same dataset under same pre-processing settings, due to the limitations of computing power(I have only 2*2080ti), I choose the configuration below:
and the training process seems good, like below~
And finally, I use the best single model to evaluate, the BLEU score=18.86, 52.2/ 25.1/ 13.9/ 7.9
However, my own baseline system trained with standard Transformer with the same dataset, pre-processing settings, I evaluate this model with a single model, in which I got BLEU socre=22.97, 56.7/ 29.9/ 18.0/ 11.2.
There exists a big gap in BLEU score, So I am wondering if there are any misconducts in my simple comparison experiment with vanilla Transformer model.