Facenet: triplet training did not converged
Hi, @davidsandberg
I just run two experiment:
- facenet_train_classifier.py version, with around 2M images and 100 thousand person identity
- facenet_train.py version, with around 10M images and 500 thousand person identity.
all the other parameters are same, bellow is the result:

I found that the triplet version (facenet_train.py) has some problems:
- it did not converged, and the result is poor.
- when run Validate-on-lfw use the model saved before, it failed.
- I found that the evaluation on lfw in facenet_train.py is complicated, there is no tensors named 'input'.
why did those happened? please help me. 3x
 mgy89
mgy89
All 33 comments
Hi,
For the first bullet I'm afraid I can't help you much. It looks similar to the performance that I used to get using facenet_train.py. Did you run inception-resnet-v1 in both cases?
For the second and third bullets those should be easy to solve by introducing an identity op as is done in facenet_train_classifier.py:
eval_image_batch = tf.identity(eval_image_batch, name='input')
 davidsandberg
on 19 Jan 2017
davidsandberg
on 19 Jan 2017
3x
your first question:
they both use inception-resnet-v1 model.
facenet_train.py use this config, which is same as facenet_train_classify.py except --center_loss_factor 2e-4:
--weight_decay 2e-4 --optimizer RMSPROP --learning_rate -1 --max_nrof_epochs 1500 --keep_probability 0.8 --random_crop --random_flip --learning_rate_schedule_file ../data/learning_rate_schedule_classifier_long.txt --gpu_memory_fraction 0.95
things changed after 65 epoch, the result became better, and the VAL is increased to 0.70 around.
I check the learning_rate_schedule, found that learning rate decreased after epoch 65, 77,etc..
This may be the reason why it converged.
Also, I check the google's facenet paper, they use initial learning rate 0.05 and adagrad, beside their dataset is very large, like 100M-200M picture.
So, my conclusion is, triplet loss is suitable for large dataset, and we also should use ada/rms but not scheduler learning rate(maybe carefully design also works).
I also run a new training program according above configuration. we can compare the results tomorrow.
your second question:
Actually, I tried to change your code, but I did not know how to get the weights of this laryer:
pre_embeddings = slim.fully_connected(prelogits, args.embedding_size, activation_fn=None, scope='Embeddings', reuse=False)
I check the document of slim, find that reuse config is the key point, and I successfully changed your code.
Maybe you can fix this too for new users, LOL
mgy89
on 19 Jan 2017
I think the main difference is that the facenet paper uses huge batch size (1800 examples) and that allows them to use low learning rate as well. And they are running on CPUs and not GPUs and I guess that makes it possible to use that large batch size.
I don't think the optimizer has any major impact on this, but I could be wrong. But the learning rates in the learning rate schedule file is optimized for classifier training, so that can probably be improved significantly when training with triplet loss.
davidsandberg
on 19 Jan 2017
Closing this. Reopen if needed.
davidsandberg
on 28 Jan 2017
Hi, @davidsandberg
I chose these parameters carefully, and run a new experiment (20 days).
The result is pretty good. Bellow is the val_rate curve:

the main parameter is:
--learning_rate_decay_factor 0.98 --learning_rate_decay_epochs 4 --people_per_batch 720 --images_per_person 5 --weight_decay 2e-4 --optimizer ADAGRAD --learning_rate 0.05
As your mentioned above, I think that, their are two key point:
- set large
people_per_batchwhen sampling triplet - learning rate should decay in several epochs
Thank you very much
mgy89
on 10 Feb 2017
Hi @mgy89!
This looks like an excellent result!! What is the resulting LFW accuracy?
If I understand it correctly from the image the training actually converges and achieves good performance.
If that is the case it would be really nice to update the wiki page about triplet loss training and maybe also supply a pretrained model based on that. Would you like to work with me on that?
I will try your parameters when I get some time. Did you have to modify the code anything?
davidsandberg
on 10 Feb 2017
Hi @davidsandberg
Yes, it achieves amazing result!
The accuracy is around 0.998, bellow is the accuracy curve:

The result above is based on my dataset(sorry for that I can not public it).
I only modify the evaluating part of your code, the main(training) code is remain the same.
So, I think that using that parameters, facescrub&casia dataset can improve performance too.
I am glad to work with you. what should I do?
mgy89
on 16 Feb 2017
@mgy89,
Incredible achievement! Congratulations.
Could you also tell us some properties of the dataset you used? Such as how many identities/images are in your dataset. Is the dataset clean or noisy? Thanks.
 ugtony
on 17 Feb 2017
ugtony
on 17 Feb 2017
@mgy89
Could you plot your loss function values? I'm trying to reproduce your approach on a cleaned up version of VGG dataset (~650k images with 300 images per identity), my loss function values drop below 0.2 but the lfw/accuracy stays under 94% and lfw/validation is below 55%.
 antoniosimunovic
on 1 Mar 2017
antoniosimunovic
on 1 Mar 2017
Hi @mgy89,
It would be really nice to have a description of how to get decent performance when training using triplet loss. I have done some test, both training from scratch and starting from a pretrained model with the settings you proposed (people_per_batch=720 & images_per_person=5, Adagrad and your learning rate decay scheme) but I can't find a setting that gets even close to the ones trained as a classifier. If you can help out to find some settings that works well with e.g. casia that would be excellent.
davidsandberg
on 9 Mar 2017
@davidsandberg, when @mgy89 said "I chose these parameters carefully, and run a new experiment (20 days).", do you think s/he meant 20 days to train? Is it feasible to take this long to converge? Idk, I am just wondering.
In the first post, s/he meant 2M-10M datasets. Maybe triplet loss needs this much of data indeed. I also have a theory (just my thoughts) that noise has a severe impact on triplet loss, as selecting wrong triplets (the anchor and positive anchor example are different people, for example) would have severe negative impact preventing the training to converge.
 dougsouza
on 22 Mar 2017
dougsouza
on 22 Mar 2017
@antoniosimunovic would you please tell me how to get the cleaned up version of VGG dataset,thanks to the extreme!
 yekeping
on 27 Mar 2017
yekeping
on 27 Mar 2017
@yekeping
First I ran face detection on VGG images, after that I've projected extracted faces to a feature space using a model provided by @davidsandberg . Then in that feature space I've used k-NN clustering to group similar faces, using only the ones in largest group.
antoniosimunovic
on 27 Mar 2017
Hi,
I have been struggling to get triplet loss for face verification running as well. I use a Resnet arch to train a classification problem (about 10000 ids) first, which works fine. Afterwards I store the 256 dim feature vectors in an LMDB (in order to avoid the process of forwarding a huge net in each batch, of course I lose the option of updating the rest of the net before the embedding by this) and try to train a triplet embedding using this implementation:
https://github.com/luhaofang/tripletloss
The database I use for the triplet embedding training currently is VGG (as provided by the authors, not cleaned). I fix the anchor, randomly sample positives and negatives for each batch iteration. So far I see only lots of loss oscillation, the old (not embedded) features still work best...
There are many factors of uncertainty:
- learning rate (started with 0.05, also tried 0.001,0.0001... nothing worked)
- margin (fixed to 0.2 at the moment. Is this always a reasonable choice for an L2 normalized feature vector?)
- solver (chose AdaGrad as suggested)
- people per batch
- images per person
- triplet selection strategy
- training from scratch/using pretrained classification model with SoftMax loss
My question: Lots of papers claim that their triplet loss is the "holy grail", but in my opinion the practical implementation problems are not covered enough in these research papers. I am also uncertain if the training method itself is responsible for the good results or the underlying database. I.e. does the triplet method trained on 2M images beat classification loss on 200M images?
Perhaps someone can elaborate on all of the issues and share more experiences. In particular I would be interested if someone has experiences with the above mentioned implementation or triplet loss in Caffe in general. I will also further comment on this if I should improve my training success.
Kind regards,
Christian
 commanderka
on 7 Apr 2017
commanderka
on 7 Apr 2017
Hey guys, as mentioned here:
a stagnating loss curve by no means indicates stagnating progress. As the network learns to solve some hard cases, it will be presented with other hard cases and hence still keep a high loss. We recommend observing the fraction of active triplets in a batch, as well as the norms of the embeddings and all pairwise distances.
Hope this helps, and thank you @davidsandberg for providing your implementation. Till now I always tried to implement everything in the TensorFlow environment, but I realized implementing i.e. the triplet selection algorithm entirely in this environment is a hard task to accomplish.
Cheers, Kris
 krisjobs
on 25 May 2017
krisjobs
on 25 May 2017
@davidsandberg really good work.
@mgy89 thank you very much for parameters.
I have followed procedure for triplet training using following parameters.
python src/train_tripletloss.py --logs_base_dir ~/workspace/logs/facenet/ --models_base_dir ~/workspace/models/facenet/ --data_dir ~/workspace/datasets/lfw/lfw_mtcnnpy_182 --image_size 182 --model_def models.inception_resnet_v1 --lfw_dir ~/workspace/datasets/lfw/lfw_mtcnnpy_182 --optimizer ADAGRAD --learning_rate 0.05 --learning_rate_decay_factor 0.98 --learning_rate_decay_epochs 4 --weight_decay 2e-4 --max_nrof_epochs 500 --people_per_batch 720 --images_per_person 5
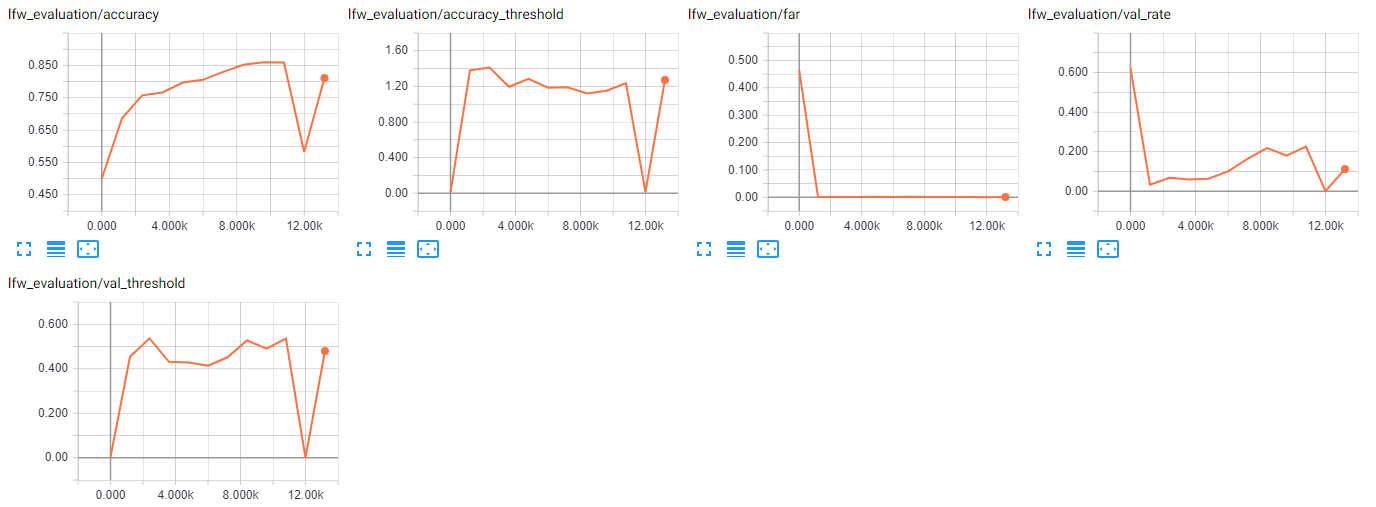
and got following results as follows.

It seems that it is conversing.
Now I will tray on VGG images.
 look4pritam
on 5 Jun 2017
look4pritam
on 5 Jun 2017
Hi @look4pritam,
Yes, it looks like it is converging. Interested to hear about your results...
It also looks like the training is collapsing a number of times, like at time step ~13k. Will be interesting to see if you get that also when training on VGG images. Maybe some tuning of the learning rate will be needed then.
davidsandberg
on 5 Jun 2017
Hi @davidsandberg
I am downloading VGG dataset and once VGG training is done I will let you know.
I can put LFW trained model on google drive, if you want it.
So that others can used it.
look4pritam
on 5 Jun 2017
@look4pritam: i'm interested to hear about ur results afterwards. What is your accuracy on LFW datasetsets?
 vudung45
on 8 Jun 2017
vudung45
on 8 Jun 2017
I am outside. Next week (27-05-2017) I will be there. On Wednesday 07-06-2017 LFW accuracy was 94-99%. It was fluctuating. Learning rate needs to be adjusted. I have kept it running on server. I will collect results on 27-05-2017 or may be before.
look4pritam
on 19 Jun 2017
LFW accuracy

Model link is
https://drive.google.com/file/d/0B3E187MXEXQ6WjkzNlV4WFRnOU0/view?usp=sharing
look4pritam
on 1 Jul 2017
Hi,@look4pritam
and how about the val rate on lfw please?
 troyzhaoyue
on 14 Aug 2017
troyzhaoyue
on 14 Aug 2017
Hi @look4pritam My network speed is too slow to download the VGGDataset, is it possible for you to upload the dataset and give me a link? Thanks!
 LiuC425
on 20 Sep 2017
LiuC425
on 20 Sep 2017
Hi,@look4pritam:I have tested the model you released, I found that the input is 182x182,and I used the aligned LFW 182x182 images for the test , but I only got 0.77 accuracy and 0.09 validation rate, is there some wrong to use your model?
 Erdos001
on 18 Oct 2017
Erdos001
on 18 Oct 2017
I have used 160x160 aligned images using mtcnn. I will check again for
aligned images size. I have uploaded the model just to indicate that it is
conversing and currently working on dataset derived from Ms 1m challenge.
On Oct 18, 2017 12:36, "Erdos001" notifications@github.com wrote:
Hi,@look4pritam https://github.com/look4pritam:I have tested the model
you released, I found that the input is 182x182,and I used the aligned LFW
182x182 images for the test , but I only got 0.77 accuracy and 0.09
validation rate, is there some wrong to use your model?—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/davidsandberg/facenet/issues/124#issuecomment-337479757,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AFLq4mSt1SP_5pU1SlO_EH3-j8A8x1Wxks5staNZgaJpZM4LnpRK
.
look4pritam
on 18 Oct 2017
Hi @davidsandberg and @look4pritam.
It would be nice if you can provide an example of using the triplet loss pre-trained model in order to compare two photos.
Repo already contains a compare.py but this is suitable only for the classifier model.
Thank you.
 spantazi
on 25 Oct 2017
spantazi
on 25 Oct 2017
@davidsandberg thank you for your perfect project, I have learned a lot.
@look4pritam thank you for you parameters, I followed your parameters ,and the result is not as good as yours. So I checked your command, and found that ,your training dataset path is the same as validation dataset path.
--data_dir ~/workspace/datasets/lfw/lfw_mtcnnpy_182
--lfw_dir ~/workspace/datasets/lfw/lfw_mtcnnpy_182
And here is my accuracy curve , does anyone knows why my accuracy remain steady at 97%-98%?
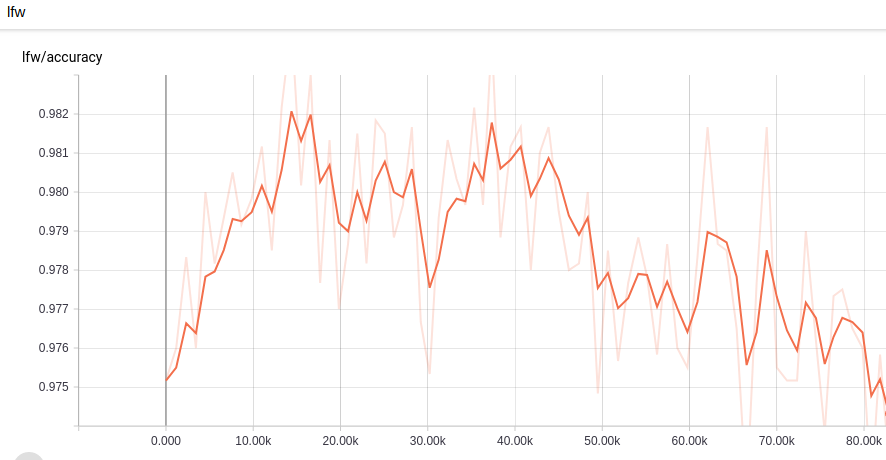
My parameters are as follows:
--batch_size 90 --image_size 160 --people_per_batch 720 --images_per_person 5 --keep_probability 0.4
--weight_decay 0.0004 --optimizer ADAGRAD --learning_rate 0.01 --learning_rate_decay_factor 0.1
--learning_rate_decay_epochs 100 --pretrained_model ../pretrian/20170511-185253/model-20170511-185253.ckpt-80000
I found that it is easy to overfit,accuracy decrease from the beginning , so I changed keep_probability and weight_decay.
I also notice that ,triplet sample selection are applied offline instead of every batch, and semi-hard selection is replaced by random selection.What's more,data augmentation wasn't applied in most command.
Are these the reasons why I can't achieve good results ?
Thank you.
 szlbiubiubiu
on 18 Jan 2018
szlbiubiubiu
on 18 Jan 2018
@look4pritam I am having trouble recreating your model results on the VGG Faces2 dataset. Specifically, I am a bit confused how your model converges so incredibly quickly with only those given parameters. Did you start out with a pre-trained model, or did the model actually converge to 90% accuracy in less than 10k training steps? I am trying to train a model from scratch, so any tips would be greatly appreciated.
 Supermaxman
on 7 Mar 2018
Supermaxman
on 7 Mar 2018
Here batch size is the key. With larger batch size model converges fast.
Try to get larger batch size, depending upon your graphics card.
I have trained tensorflow slim models, there also batch size plays imp
role.
With larger batch size models get trained faster as well as they achieve
better accuracy.
But in case of tensorflow slim also I was not getting 90% in 10k iterations.
It may be because of centre loss for facenet. But I am not sure about it.
I have not tried centre loss in tensorflow slim. Once that is done, I can
comment.
On Mar 7, 2018 22:57, "Max Weinzierl" notifications@github.com wrote:
@look4pritam https://github.com/look4pritam I am having trouble
recreating your model results on the VGG Faces2 dataset. Specifically, I am
a bit confused how your model converges so incredibly quickly with only
those given parameters. Did you start out with a pre-trained model, or did
the model actually converge to 90% in less than 10k training steps?—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/davidsandberg/facenet/issues/124#issuecomment-371215836,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AFLq4mQy49X5TAZG4hHlqr8mHf-p_nfBks5tcBhogaJpZM4LnpRK
.
look4pritam
on 8 Mar 2018
@look4pritam thanks a lot for the insight!
@davidsandberg I think I might have a theory about why the training often seems to collapse. I was very interested in logging different training statistics, and after setting up some different metrics I noticed an interesting pattern:
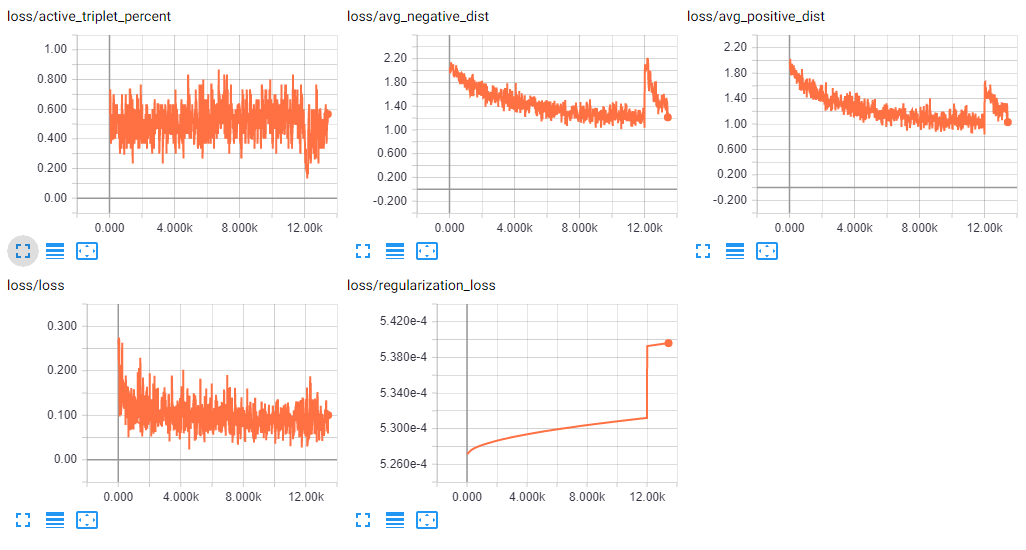
I define active_triplet_percent as
triplet_loss = tf.maximum(pos_dist + margin - neg_dist, 0.0)
active_triplet_percent = tf.reduce_mean(tf.cast(tf.greater(triplet_loss, 0), tf.float32))
Even with the pos_dist_sqr + alpha > neg_dists_sqr triplet selection criteria (along with pos_dist_sqr < neg_dists_sqr for semi-hard) we see that there is consistently a decent percentage of inactive triplets.
Some of this I theorize can be attributed to batch normalization changing the batch statistics, but something interesting occurs where the model's accuracy and loss collapse at around iteration 12k. We see a massive spike of inactive triplets, down to only 13% of the minibatch triplets being used for that iteration.
For my training configuration, 12k is the exact iteration where new triplets are selected. It is not clear to me the direct cause, but it is clear that the problem arises from poor triplet selection. A few poor iterations can essentially torpedo the accuracy, and from this damage there are very few active triplets remaining within the batch. The model's recovery therefore takes some time, since it may suddenly be working with 10%-30% of the minibatch triplets. It seems like the damage was done at the tail end of the previous triplet selection (from 10.8k), and then the next triplet selection at 12k was based off this damaged state.
I would love to hear any other thoughts on this. I am specifically really interested in why my active triplet percent seems so low on average, considering the forward pass which is supposed to only select triplets which satisfy pos_dist_sqr + alpha > neg_dists_sqr. Is this entirely due to batch normalization statistics, or is something else going on here? I don't understand why there are so few active triplets on average (~50%). I could understand if it reduced through a batch and jumped back up at the start of the next batch, but this behavior confuses me.
I am going to continue to test with different batch sizes, and if I find a configuration which reduces this model collapse I will post it here.
Supermaxman
on 8 Mar 2018
Clean the dataset before training. It is also important. David has given
procedure for it. Basically it starts with dry run, train your model till
you get 50-70 % accuracy. Then remove top 10-20% images with more error.
Then train it again. It works, I am doing it for Microsoft 100K dataset.
On Mar 9, 2018 00:55, "Max Weinzierl" notifications@github.com wrote:
@look4pritam https://github.com/look4pritam thanks a lot for the
insight!
@davidsandberg https://github.com/davidsandberg I think I might have a
theory about why the training often seems to collapse. I was very
interested in logging different training statistics, and after setting up
some different metrics I noticed an interesting pattern:[image: g1]
https://user-images.githubusercontent.com/1005359/37170195-ccd4948e-22cf-11e8-9ae6-d4cb7c058b0d.PNG[image: g2]
https://user-images.githubusercontent.com/1005359/37170200-cffa6f08-22cf-11e8-9b31-776778e27135.PNGI define active_triplet_percent as
triplet_loss = tf.maximum(pos_dist + margin - neg_dist, 0.0)
active_triplet_percent= tf.reduce_mean(tf.cast(tf.greater(triplet_loss, 0), tf.float32))Even with the pos_dist_sqr + alpha > neg_dists_sqr triplet selection
criteria (along with pos_dist_sqr < neg_dists_sqr for semi-hard) we see
that there is consistently a decent percentage of inactive triplets.Some of this I theorize can be attributed to batch normalization changing
the batch statistics, but something interesting occurs where the model's
accuracy and loss collapse at around iteration 12k. We see a massive spike
of inactive triplets, down to only 13% of the minibatch triplets being used
for that iteration.For my training configuration, 12k is the exact iteration where new
triplets are selected. It is not clear to me the direct cause, but it is
clear that the problem arises from poor triplet selection. A few poor
iterations can essentially torpedo the accuracy, and from this damage there
are very few active triplets remaining within the batch. The model's
recovery therefore takes some time, since it may suddenly be working with
10%-30% of the minibatch triplets. It seems like the damage was done at the
tail end of the previous triplet selection (from 10.8k), and then the next
triplet selection at 12k was based off this damaged state.I would love to hear any other thoughts on this. I am specifically really
interested in why my active triplet percent seems so low on average,
considering the forward pass which is supposed to only select triplets
which satisfy pos_dist_sqr + alpha > neg_dists_sqr. Is this entirely due
to batch normalization statistics, or is something else going on here? I
don't understand why there are so few active triplets on average (~50%). I
could understand if it reduced through a batch and jumped back up at the
start of the next batch, but this behavior confuses me.I am going to continue to test with different batch sizes, and if I find a
configuration which reduces this model collapse I will post it here.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/davidsandberg/facenet/issues/124#issuecomment-371595586,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AFLq4oXY9-8MMGu2Nv5KuARh5vBOTiGwks5tcYWkgaJpZM4LnpRK
.
look4pritam
on 10 Mar 2018
@look4pritam hi, how can I train a VGG dataset by using a triplet loss. Currently, I am using the
train_tripletloss.py --lfw_dir ./datasets/lfw --optimizer ADAGRAD --learning_rate 0.01 --weight_decay 1e-4 --max_nrof_epochs 150 --learning_rate_schedule_file_data/learning_rate_schedule_classifier_vggface2.txt --people_per_batch 720 --images_per_person 5
but the program is crashed when saving a checkpoint model.
 thuoctran
on 12 Jun 2018
thuoctran
on 12 Jun 2018
Hi, can someone please tell me how to use a pretrained model for classifying unknown images using triplet loss? And where can I find the pretrained model for the same?
 vibhuti19
on 13 Jul 2018
vibhuti19
on 13 Jul 2018
Related issues
 mayank26saxena
·
4Comments
mayank26saxena
·
4Comments
 Zumbalamambo
·
3Comments
Zumbalamambo
·
3Comments
 Feynman27
·
3Comments
Feynman27
·
3Comments
 Leedonggeon
·
3Comments
Leedonggeon
·
3Comments
 scotthong
·
3Comments
scotthong
·
3Comments
Most helpful comment
Hi, @davidsandberg

I chose these parameters carefully, and run a new experiment (20 days).
The result is pretty good. Bellow is the val_rate curve:
the main parameter is:
--learning_rate_decay_factor 0.98 --learning_rate_decay_epochs 4 --people_per_batch 720 --images_per_person 5 --weight_decay 2e-4 --optimizer ADAGRAD --learning_rate 0.05As your mentioned above, I think that, their are two key point:
people_per_batchwhen sampling tripletThank you very much