Espnet: The utilization rate of gpu is strang when training transformer & fastspeech
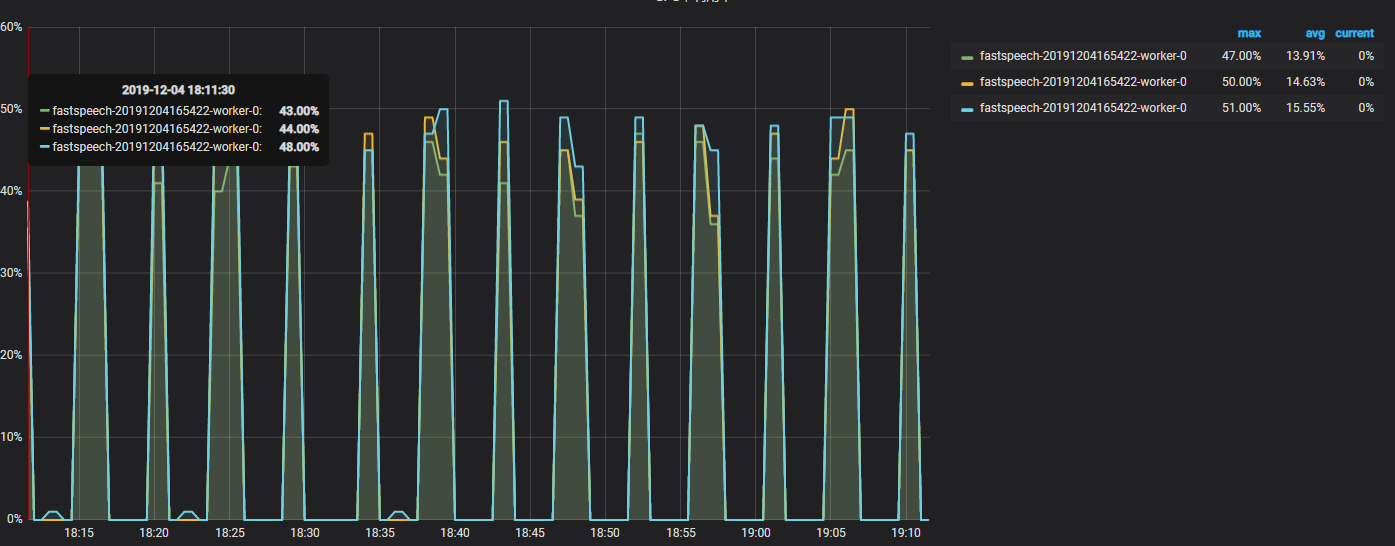
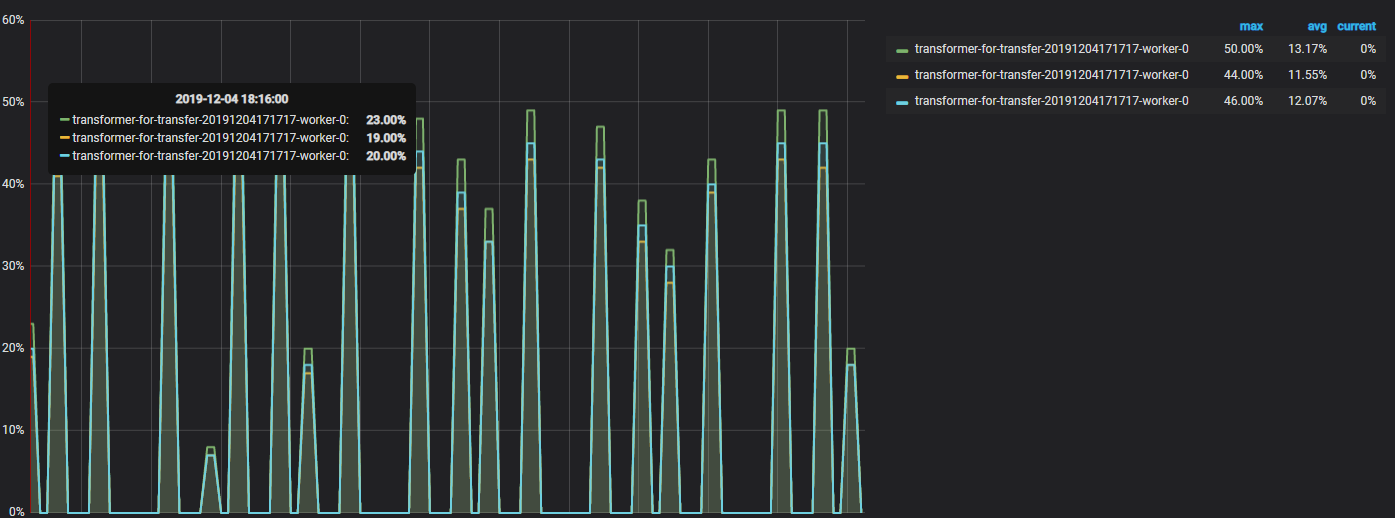
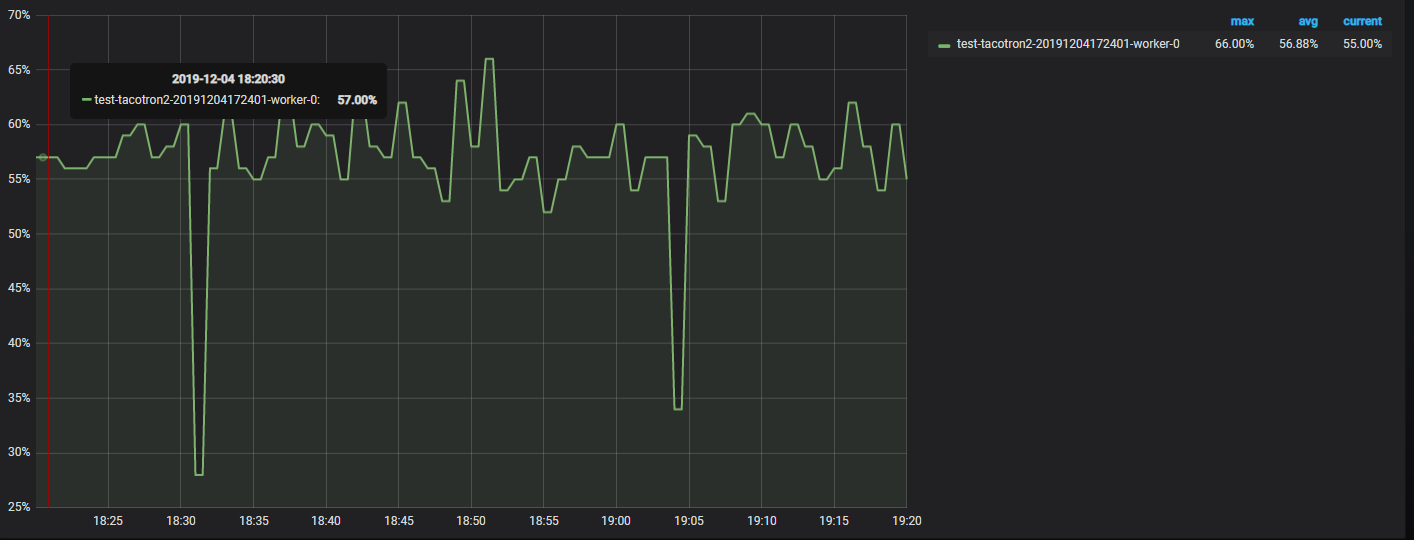
when I trained TTS model on the /csmsc/conf/tuning/fastspeech.v3&transformer.v1, the utilization rate of gpu would go to zero for a while(but the result is aceptable), but the rate of tacotron2.v3 was fine. Is there any explanation for that?
fastspeech on 3 gpu
transformer on 3 gpu
tacotron2 on 1 gpu
 JoeyHeisenberg
JoeyHeisenberg
All 3 comments
Maybe IO is bottleneck.
Try num-iter-processes > 0.
https://github.com/espnet/espnet/blob/beaef4e8c5f09cc655a6f7011f257d3800d311f8/espnet/bin/tts_train.py#L93
For example, you can add num-iter-processes: 4 in yaml config.
 kan-bayashi
on 4 Dec 2019
kan-bayashi
on 4 Dec 2019
Maybe attention plot is also bottleneck because Transformer's plot is very large. You can try num-save-attention: 0 in the training yaml
https://github.com/espnet/espnet/blob/beaef4e8c5f09cc655a6f7011f257d3800d311f8/espnet/bin/tts_train.py#L121-L122
 ShigekiKarita
on 4 Dec 2019
ShigekiKarita
on 4 Dec 2019
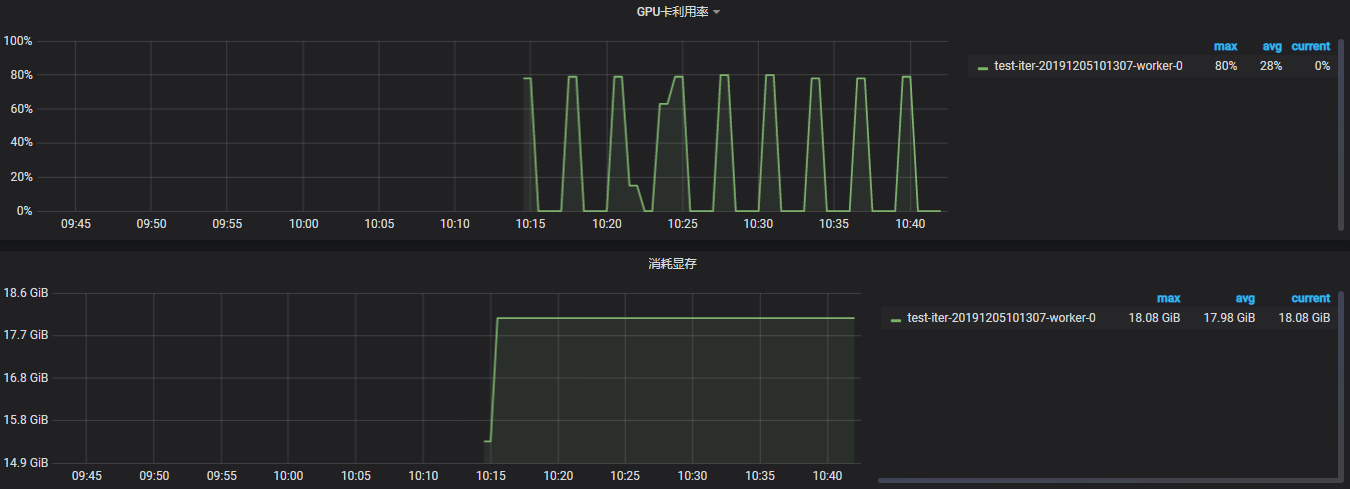
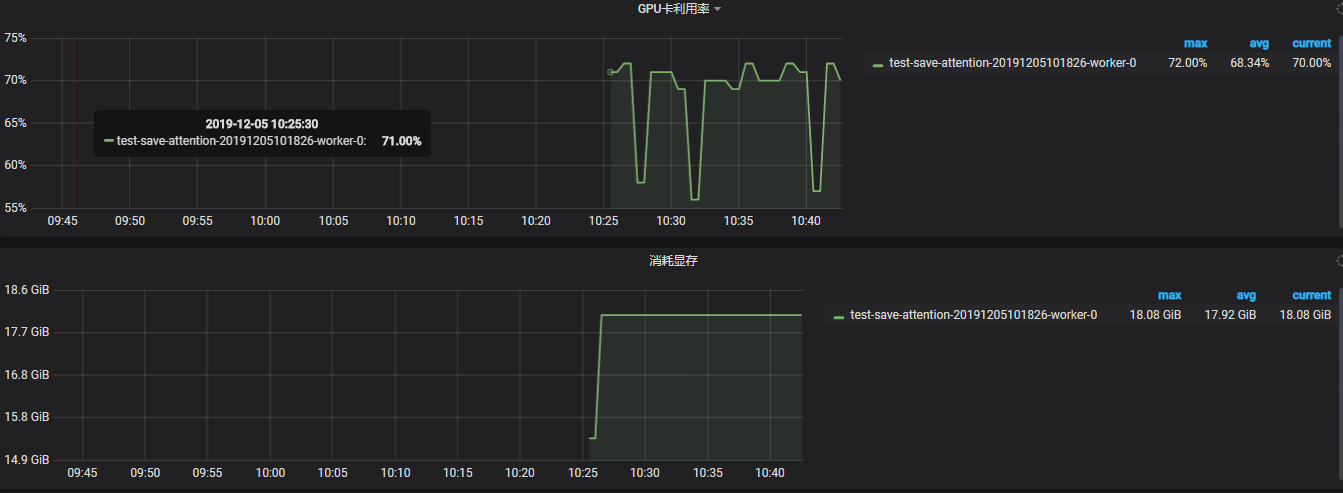
@kan-bayashi @ShigekiKarita I have tested on the experiment what you suggested, and the result support your guess @ShigekiKarita ,thx both of you :)
test on default
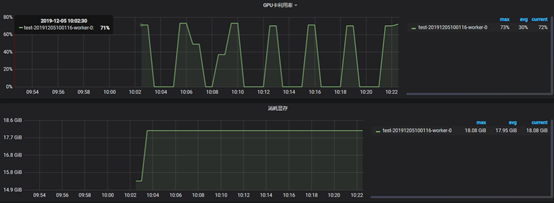
test on num-iter-porcessed = 4
test on num-save-attention = 0
JoeyHeisenberg
on 5 Dec 2019
Related issues
 mdeisher
·
4Comments
mdeisher
·
4Comments
 ymzlygw
·
4Comments
ShigekiKarita
·
5Comments
ymzlygw
·
4Comments
ShigekiKarita
·
5Comments
 ghost
·
5Comments
ghost
·
5Comments
 panademo
·
3Comments
panademo
·
3Comments
Most helpful comment
@kan-bayashi @ShigekiKarita I have tested on the experiment what you suggested, and the result support your guess @ShigekiKarita ,thx both of you :)
test on default

test on num-iter-porcessed = 4

test on num-save-attention = 0
