Sorry if it's a very basic question.
I am a newbie experimenting with the librispeech recipe on a single gpu (GTX 1660ti).
when I use librispeech recipe with espnet / egs / librispeech / asr1 / conf / tuning / train_pytorch_transformer_lr5.0_ag8.v2.yaml, I get a cuda out of memory issue.
So I arbitrarily modified the batch-bin of that file (e.g 5,992,000-> 3,000,000),
This solved the problem.
However, there is some confusion when studying the program.
I thought batch-bin means batchsize, but in the NN training (e.g. stage 4)
I saw an 41000 iterate per epoch.
I know that epoch means learning the whole data once. ( e.g. 1 epoch = iterate * batch-size )
To say that batch-bin means batchsize, it seems that 1 epoch value is too large than librispeech data.
so can you explain more about accum-grad, ahead, batch-bin, batch-count?
 dsa934
dsa934
All 4 comments
See https://github.com/espnet/espnet#how-to-set-minibatch to understand the difference.
And ahead is the number of heads in multihead attention.
if set accum_grad=2, the network is updated once per two forward propagation.
So accum_grad=2 and batch-size=32 is theoretically equal to accum_grad=1 and batch-size=64.
This is useful to train network using a large batchsize with a single gpu.
 kan-bayashi
on 2 Sep 2019
kan-bayashi
on 2 Sep 2019
awesome thanks.
you mean batch-bin = ( batch_size * ( mean(ilen) * idim + mean(olen) * odim ) )
if
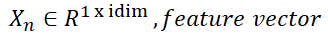 then
then
is it right ?
dsa934
on 2 Sep 2019
That’s right.
kan-bayashi
on 2 Sep 2019
Thanks a lot.
i love ESPnet
dsa934
on 2 Sep 2019
Related issues
 smolendawid
·
4Comments
smolendawid
·
4Comments
 ymzlygw
·
4Comments
ymzlygw
·
4Comments
 vjdtao
·
5Comments
vjdtao
·
5Comments
 ShigekiKarita
·
3Comments
ShigekiKarita
·
5Comments
ShigekiKarita
·
3Comments
ShigekiKarita
·
5Comments
Most helpful comment
Thanks a lot.
i love ESPnet