Esmvaltool: large differences in resources between iris 1.13 and iris 2.0
Hey guys, @mattiarighi has noticed that the same run done with different versions of iris raises differences in effective run times. He called iris as the root cause. So I decided to run some systematic tests to see first if iris is indeed the problem and not some variation in the transition python 2.7 -> python 3.6 environment, and second, observe by how much we are losing in resources due to iris version change. Here are my results (the pdf file, 3 slides), done for different configurations of the run with either iris 1.13 or iris 2.0. To summarize:
- iris version is indeed the problem, replacing iris 2.0 in the python 3.6 environment gives the same memory and times as for iris 1.13 in a python 2.7 environment; it is actually faster (well, one test only so don't trust it 100%) to have iris 1.13 in python 3.6;
- the resources taken by using iris 2.0 (both memory and time) are much higher than the ones using iris 1.13; this is a major problem when dealing with large numbers of models and heavy operations like masking and multimodel analyses; in fact, on average, the times double for these operations and @mattiarighi has already encountered cases of running out of memory;
@bjlittle is this because of the change from biggus to dask? Have you guys at the MO noticed these issues as well compared to iris 1.XX? And most importantly, what do you recommend us to do -- eg pin iris 1.17?
Iris2_Issue.pdf
 valeriupredoi
valeriupredoi
All 31 comments
I have done another test: read two netCDF files, get the root mean square of the two cube datas and assemble a composite mask of the cubes (|=), no writing to file, just operations in memory -- with iris 1.13 and 2.0:
Repeated masked array operations: 35 times
Iris 1.13: mean 0.740 s +/- std 0.125 s
Iris 2.00: mean 0.908 s +/- std 0.191 s
So even at a relatively simple load and a couple mathematical operations we notice something of a 20% offest in real time from iris 1.13 and iris 2.0
valeriupredoi
on 30 Apr 2018
Here is the snippet I used for another timing test:
f = 'PREPROCESSOR_i113_save/namelist_20180427_102752/preproc/ta850_pp850_ta/CMIP5_bcc-csm1-1_Amon_historical_r1i1p1_T3M_ta_2000-2002/08_mask_fillvalues.nc'
g = 'PREPROCESSOR_i113_save/namelist_20180427_102752/preproc/ta850_pp850_ta/CMIP5_GFDL-ESM2G_Amon_historical_r1i1p1_T3M_ta_2000-2002/08_mask_fillvalues.nc'
c1 = iris.load_cube(f)
c2 = iris.load_cube(g)
csum = np.ma.mean(np.ma.sqrt(c1.data**2. + c2.data**2.) / (c1.data*c2.data), axis=0)
c1.data.mask |= c2.data.mask
This time around the time differences are even worse:
Repeated masked array operations: 35 times
Iris 1.13: mean 0.827 +/- std 0.173
Iris 2.00: mean 1.256 +/- std 0.254
valeriupredoi
on 30 Apr 2018
I think the main issue here is that we are not really using Dask in the backend. I made a sample test with a small cluster of 4 Dask workers and performance was awful. We need to update the code to be able to benefit from the potential of Iris 2.0 and Dask. It will probably be easier to do at the workshop, but we must decide if we can wait or if it will be too much
 jvegasbsc
on 30 Apr 2018
jvegasbsc
on 30 Apr 2018
I was under the assumption that iris 2.0 should work right out the box like iris <= 1.13 used to -- I mean, there are not too many operations we are using iris specifically for, it's mainly masked data arrays passed around and manipulated using generic numpy functions (ok - sliding window and Aggregator in masks, load/concatenate/save and that's pretty much it). Why would an extra level of optimization be needed just to optmize the workability with the new iris? Sorry, might sound like a n00b :grinning:
valeriupredoi
on 30 Apr 2018
It works out of the box, it is just using more resources. Those extra resources are something that I would expect as Dask is more complex than Biggus because of the extra features it has. the thing here is that we have just switched to a more complex option without using any of the extra features it provides, like delayed operations
jvegasbsc
on 30 Apr 2018
eugh, sounds like me going to a fancy pub instead of the dodgy ones, I can't just order my standard 'cheapest lager on tap'. OK, would it make sense to use 1.13 until we decide which fancy beer we go for? That works really nice within a python 3.6 environment and the basic changes from 1.13 to 2.0 (not the fancy Dask things) are exactly three lines in three codes: _time_area, _multimodel and _io
valeriupredoi
on 30 Apr 2018
We're in an really interesting space now that we've replaced biggus with dask.
Moving over to dask was inevitable, and a necessary change, so I don't see that as a backwards step; quite the opposite. However, leveraging the benefits of dask may require a little bit of effort and thought, as @jvegasbsc suggests in his comment above.
There are definite cases where for small data, the overhead of dask just swamps it's expected benefit - and that's just the nature of the beast.
We do need to do some analysis on the runtime behaviour changes of iris and see if there are any obvious bottlenecks or things that we just got wrong or could do better when using dask. Those wrinkles will be ironed out over time through user mileage. However, there are some obvious changes that could be made to see whether it has an impact on performance.
By default, the dask.array uses the threaded scheduler, which I believe is defaulting to using all the cores available. The number of cores and type of scheduler can be controlled easily, see http://dask.pydata.org/en/latest/scheduler-overview.html
Also, we made a best guess at the chunks size that dask uses, see iris._lazy_data._MAX_CHUNK_SIZE... this may or may not be appropriate to specific use cases.
@valeriupredoi
csum = np.ma.mean(np.ma.sqrt(c1.data2. + c2.data2.) / (c1.data*c2.data), axis=0)
You now need to be a little bit more savvy about lazy data. Each time you touch the data, iris will force dask to load the data from disk to memory. In the example above you are forcing dask to load the entire c1 data payload twice and the c2 data payload twice. Whereas, you could keep the computation lazy as long as possible with
(c1**2 + c2**2)**0.5 / (c1*c2)
then use the collapsed cube method with the iris.analysis.MEAN aggregator over the appropriate coordinate that represents axis=0... then touch the data of the resultant cube to realize the data.
I'd be interested to know if that makes a difference... :thinking:
 bjlittle
on 1 May 2018
bjlittle
on 1 May 2018
@valeriupredoi Or as an alternative approach, if you didn't want to work at the cube level, but just the data, and so keep the comparison between 1.13 and 2.0 fairer, you could opt to manipulate the dask lazy data directly e.g. something along the lines of...
import dask.array as da
csum = da.mean(da.sqrt(c1.lazy_data()**2. + c2.lazy_data()**2.) / (c1.lazy_data() * c2.lazy_data()), axis=0)
At this point csum should still be lazy, and return instantaneously. To realize the result with concrete values, simply do csum.compute()
That would also be interesting to know the processing time for this approach...
bjlittle
on 1 May 2018
Hey guys, great input here! @bjlittle cheers for your detailed explanation, man! I am as new to dask as King Kong was to New York City so I am going to get to grips with it in the following weeks. As of now, though, I'd like to ask for opinions for an immediate strategy about ESMValTool v2:
- it is obvious that without a careful tweaking iris 2 is not as nice with resources as iris 1.13; should we use 1.13 in the python3.6 environment while the tweaking is being done? @bjlittle what is the lifespan of 1.13 -- you guys gonna retire it soon?
- this 'tweaking' has to be done nonetheless, would it make sense to get the ball rolling @jvegasbsc since you obviously know much more about dask than me and work closely with Bill, or we'd want to have a chat about it soon and maybe work on it at the DLR workshop? BTW Bill you coming to that one? It would be really useful and cool if you could!
- in terms of support, as I mentioned in my previous comment, the code differences in ESMValTool are less than minor to get the transition from 1.13 to 2.0 or the other way round, so maybe for now just add a check on iris.__version__?
Cheers again for looking into this guys!
valeriupredoi
on 1 May 2018
@valeriupredoi To help you guys come to an informed decision, it is useful to know that we only intent to (at most) perform point releases on the iris 1.13.x branch i.e bugfixes only, no new features. We simply don't have the capacity to fully support development on multiple variant release branches.
So to answer your question, there is no scheduled development lifespan scheduled for 1.13 - it's pretty much as good as it's gonna get.
bjlittle
on 1 May 2018
@valeriupredoi Apologies, me again, with another random thought... it would also be interesting to know how the timings compare if you make the data payloads much bigger... Where is the tipping point where dask chunking and multi-threading starts to provide real benefits in terms of performance, given the resources that it's monopolizing...
bjlittle
on 1 May 2018
@bjlittle -- with regards to iris 1.13, thanks, man, good to know what the status of the distribution is. We don't need any new features in iris 1.13, using it should be an interim solution until the ESMValTool code tweaks are done for iris 2.0 optimal work. I'll give the floor to @mattiarighi and co. on this matter. About the testing the data payloads, I am not in the position to do this right now, but if you could explain to me how this test should be done I can try hatch something up later today or tomorrow - ie, should I run a preprocessor with a lot of models? Cheers muchly!
valeriupredoi
on 2 May 2018
Thanks @valeriupredoi for testing and @jvegasbsc + @bjlittle for the comments!
We had an internal discussion here about this issue. Our suggestion for the way forward would be the following:
- we should bring back
REFACTORING_backendto work with Iris1.13. This means reverting PR #298 and #315, and pin 1.13 in environment.yml (@valeriupredoi could you take care of this in a dedicated branch?) - parallel to that, we should create a separate branch to adapt the backend code to Iris2 and only merge it when the performance is at the level of (or better than) Iris1.13. Can we estimate how much time this will take? I have no feeling how much work this would be.
Hopefully @bjlittle can support us.
In any case, the focus of the workshop in June should be on porting the diagnostics and related issues.
This can be done also with Iris1.13. Of course, the workshop will also be an opportunity to discuss this issue, but it should not be the main focus.
@ESMValGroup/esmvaltool-coreteam
 mattiarighi
on 2 May 2018
mattiarighi
on 2 May 2018
Sounds very good to me!
@mattiarighi I will do the work right away
@bjlittle -- adapting the small test code with not calling cube.data multiple times:
f = 'PREPROCESSOR_i113_save/namelist_20180427_102752/preproc/ta850_pp850_ta/CMIP5_bcc-csm1-1_Amon_historical_r1i1p1_T3M_ta_2000-2002/08_mask_fillvalues.nc'
g = 'PREPROCESSOR_i113_save/namelist_20180427_102752/preproc/ta850_pp850_ta/CMIP5_GFDL-ESM2G_Amon_historical_r1i1p1_T3M_ta_2000-2002/08_mask_fillvalues.nc'
c1 = iris.load_cube(f)
c2 = iris.load_cube(g)
data1 = c1.data
data2 = c2.data
csum = np.ma.mean(np.ma.sqrt(data1**2. + data2**2.) / (data1*data2), axis=0)
data1.mask |= data2.mask
is not helping the time:
Iris 1.13: mean 1.135 s +/- std 0.317 s
Iris 2.00: mean 1.732 s +/- std 0.737 s
valeriupredoi
on 2 May 2018
Hi chaps @mattiarighi @bjlittle @jvegasbsc et co.
Branch created: https://github.com/ESMValGroup/ESMValTool/tree/REFACTORING_backend_iris113
Environment is python 3.6.5 and iris 1.13.0
Tested and see the performance curve for the preprocessor with only a single plev select.
To get the environment set up I recommend using a specific name for it:
conda env update --file environment.yml --name esmvaltool_iris113
BTW @mattiarighi my environment is using numba 0.38 and llvmlite 0.23 and it works fine:
(esmvaltool_iris113) [valeriu@jasmin-sci1 ESMValTool_BASIC_TEST]$ conda list numba
# packages in environment at /group_workspaces/jasmin/ncas_cms/valeriu/anaconda2_test/envs/esmvaltool_iris113:
#
# Name Version Build Channel
numba 0.38.0 <pip>
(esmvaltool_iris113) [valeriu@jasmin-sci1 ESMValTool_BASIC_TEST]$ conda list llvmlite
# packages in environment at /group_workspaces/jasmin/ncas_cms/valeriu/anaconda2_test/envs/esmvaltool_iris113:
#
# Name Version Build Channel
llvmlite 0.23.0 <pip>
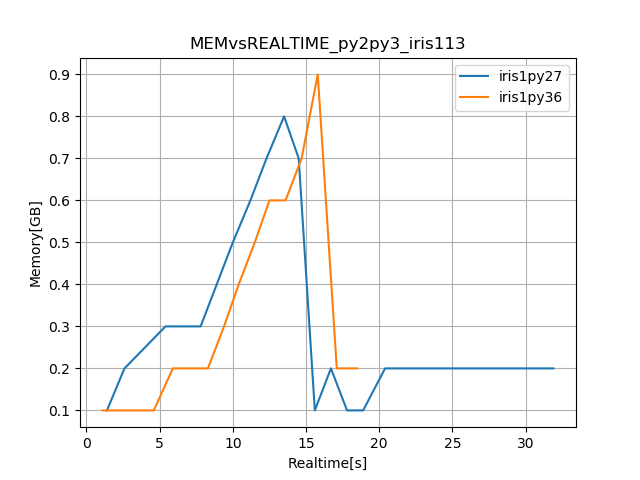
valeriupredoi
on 2 May 2018
and here is the set of memory vs time for the same environments (py3) only with different irises, for a 'full' preprocessor (select level, regridding, masking, multimodels) and no diagnostic. I will use this namelist as reference when we get iris 2 to work smoothly.
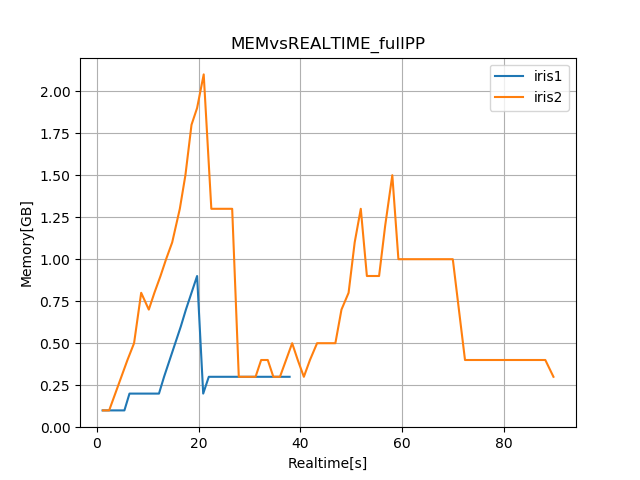
valeriupredoi
on 2 May 2018
Thanks @valeriupredoi.
Go ahead with the pull request.
mattiarighi
on 2 May 2018
@pelson These performance results are pretty curious...
bjlittle
on 2 May 2018
@pelson These performance results are pretty curious...
Yes indeed. I'd be interested in seeing the results with the (non-default) threadded scheduler, rather than the one that dask uses out of the box.
Is it easy to do the same measurements with
import dask
dask.set_options(get=dask.get)
set before running any iris code?
I've seen a number of cases where that has a huge impact on resource usage.
 pelson
on 2 May 2018
pelson
on 2 May 2018
@valeriupredoi Could you rerun the test again, but using the dask synchronous scheduler (as above - also see http://dask.pydata.org/en/latest/scheduler-overview.html#debugging-the-schedulers) for iris 2.0 ?
bjlittle
on 2 May 2018
@valeriupredoi I'd also like to recreate this issue locally myself to investigate further. Could you email me the details of your setup, cheers! :+1:
bjlittle
on 2 May 2018
Hey guys, will do this first thing today :)
Dr Valeriu Predoi.
Computational scientist
NCAS-CMS
University of Reading
Department of Meteorology
Reading RG6 6BB
United Kingdom
On Wed, 2 May 2018, 19:14 Bill Little, notifications@github.com wrote:
@valeriupredoi https://github.com/valeriupredoi I'd also like to
recreate this issue locally... Could you email me the details of your
setup, cheers! 👍—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/ESMValGroup/ESMValTool/issues/318#issuecomment-386071182,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AbpCo497uB30p4MoMymZkZkC7-2ly8Eiks5tufdugaJpZM4Tsbnp
.
valeriupredoi
on 3 May 2018
Hey guys, I have added the lines that @pelson suggested right before any iris operation, but after importing iris:
import iris
import time
import numpy as np
# dask settings
import dask
dask.set_options(get=dask.get)
print(iris.__version__)
# run some series of array operations
t1 = time.time()
f = 'PREPROCESSOR_i113_save/namelist_20180427_102752/preproc/ta850_pp850_ta/CMIP5_bcc-csm1-1_Amon_historical_r1i1p1_T3M_ta_2000-2002/08_mask_fillvalues.nc'
g = 'PREPROCESSOR_i113_save/namelist_20180427_102752/preproc/ta850_pp850_ta/CMIP5_GFDL-ESM2G_Amon_historical_r1i1p1_T3M_ta_2000-2002/08_mask_fillvalues.nc'
c1 = iris.load_cube(f)
c2 = iris.load_cube(g)
data1 = c1.data
data2 = c2.data
csum = np.ma.mean(np.ma.sqrt(data1**2. + data2**2.) / (data1*data2), axis=0)
data1.mask |= data2.mask
t2 = time.time()
print('dt = %.3f seconds' % (t2 - t1))
and called this 'dask tweak'. Within a python 3.6.4-iris 2.0.0 esmvaltool environment:
Repeated masked array operations: 35 times
within esmvaltool environment
Iris 2.0 w/o dask tweak: mean 1.314 s +/- std 0.250 s
Iris 2.0 WITH dask tweak: mean 0.899 s +/- std 0.113 s
and getting out the environment but preserving the python and iris versions
Repeated masked array operations: 35 times
Iris 2.0 w/o dask tweak: mean 1.327 s +/- std 0.252 s
Iris 2.0 WITH dask tweak: mean 1.198 s +/- std 0.223 s
and again, going back into the esmvaltool environment
Repeated masked array operations: 35 times
within esmvaltool environment
Iris 2.0 w/o dask tweak: mean 1.097 s +/- std 0.163 s
Iris 2.0 WITH dask tweak: mean 1.007 s +/- std 0.126 s
and in the same environment, comparison with iris 1.13
Repeated masked array operations: 35 times
within esmvaltool environment
Iris 1.13: mean 0.971 s +/- std 0.128 s
Iris 2.0 w/o dask tweak: mean 1.222 s +/- std 0.176 s
Iris 2.0 WITH dask tweak: mean 0.997 s +/- std 0.167 s
So it looks like the suggested dask tweak really works! iris2 times are fluctuating more severely if not with the dask tweak, but both cases for iris2 seem rather more unstable as compared to iris 113.
And I would do more testing but some pogo has just removed write persmissions to my home dir on Jasmin...so it'll do for now until that gets reverted :grimacing:
valeriupredoi
on 3 May 2018
@nielsdrost and I discussed this issue and we feel that the really important issues at the moment are the issues that prevent us from doing the v2 alpha release, see this project for a list. Even if iris 2 uses more resources, we are still much faster than ESMValTool V1. Therefore I would suggest not spending too much time on this now, but instead focus on getting our first release out.
So far we've done very little on optimizing the code for memory usage and runtime, apart from trying to write decent code. After we have the minimum required set of features implemented and a reasonable set of diagnostics working, we can go and see if we can make the implementation more efficient, because then it will also be clear where the bottlenecks are (if any). If you start optimizing too early, you run the risk of spending a lot of time optimizing something that turns out to be not important after all.
If the solution to this issue is indeed as simple as suggested by @pelson above, then I would suggest implementing that and switching back to iris v2 (i.e. revert PR #320). That way we will be encouraged to write code that works well with v2 of iris and we will benefit from new features and bugfixes as they appear.
 bouweandela
on 4 May 2018
bouweandela
on 4 May 2018
sounds good, I'll have a start on adding the dask tweak and reinstating iris 2.0 as soon as I finish rebuilding my environment on Jasmin that got completely messed up by a move of the workspaces partitions :)
valeriupredoi
on 8 May 2018
sounds good, I'll have a start on adding the dask tweak and reinstating iris 2.0 as soon as I finish rebuilding my environment on Jasmin that got completely messed up by a move of the workspaces partitions :)
valeriupredoi
on 8 May 2018
Hey guys, so I applied the fix suggested by @pelson and @bjlittle and tested by me previously (see above post, for which I actually got rather mixed results). Fix was applied to these files where iris is imported:
# modified: esmvaltool/cmor/check.py
# modified: esmvaltool/preprocessor/__init__.py
# modified: esmvaltool/preprocessor/_io.py
# modified: esmvaltool/preprocessor/_mask.py
# modified: esmvaltool/preprocessor/_multimodel.py
# modified: esmvaltool/preprocessor/_regrid.py
# modified: esmvaltool/preprocessor/_time_area.py
#
import iris
# dask settings
import dask
dask.set_options(get=dask.get)
and here are results for three identical tests. Not conclusive to say the least, and all worse than iris1. Then again, maybe (and surely actually) in a lot of the code we use cube.data instead of setting that to a variable and pass it from there on; I have NOT changed that, so possibly the performance can only improve. But I just wanted to show you how the dask setting influences the performance on its own; to note that I did not use multithreading.
I am still in favour of keeping iris 1.13 until we fix these performance issues. I can start working on them asap so we don't have to keep iris 1.13 for too long and influence our further development. Up to you, I get paid either way :grinning:
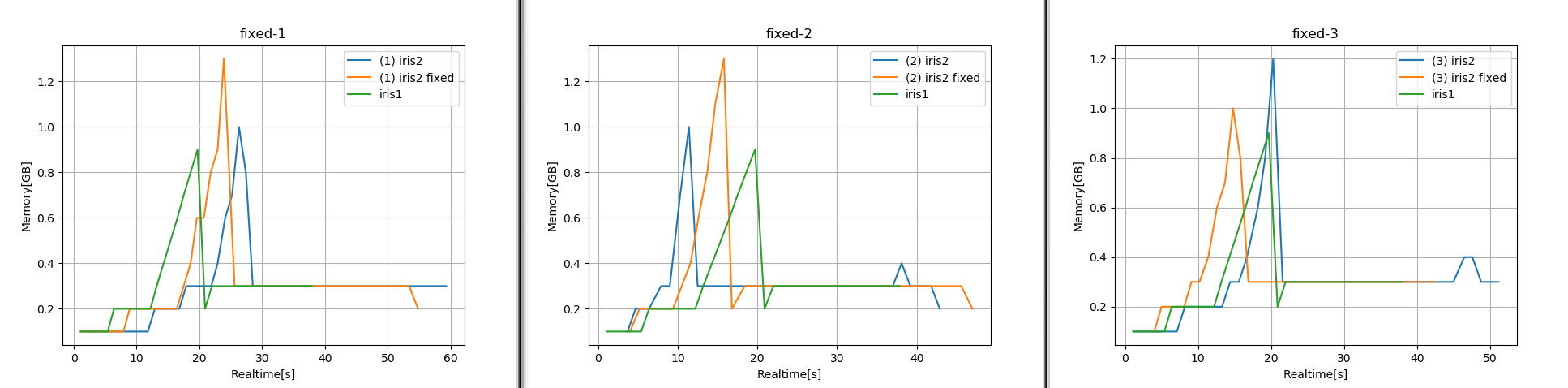
valeriupredoi
on 8 May 2018
@valeriupredoi Thanks for testing!
It looks like that we are still far from a satisfactory solution.
Supporting Bouwe's above comment, I would suggest to leave it for the moment and focus on other things at least until the workshop. We can discuss it again there and decide how to move forward.
But until then, these issues should have higher priority.
mattiarighi
on 8 May 2018
sounds like a good plan!
valeriupredoi
on 8 May 2018
This issue is duplicated in #451.
mattiarighi
on 22 Oct 2018
Related issues
 IreMav
·
4Comments
valeriupredoi
·
4Comments
valeriupredoi
·
4Comments
IreMav
·
4Comments
valeriupredoi
·
4Comments
valeriupredoi
·
4Comments
 jhardenberg
·
5Comments
valeriupredoi
·
4Comments
jhardenberg
·
5Comments
valeriupredoi
·
4Comments
Most helpful comment
@nielsdrost and I discussed this issue and we feel that the really important issues at the moment are the issues that prevent us from doing the v2 alpha release, see this project for a list. Even if iris 2 uses more resources, we are still much faster than ESMValTool V1. Therefore I would suggest not spending too much time on this now, but instead focus on getting our first release out.
So far we've done very little on optimizing the code for memory usage and runtime, apart from trying to write decent code. After we have the minimum required set of features implemented and a reasonable set of diagnostics working, we can go and see if we can make the implementation more efficient, because then it will also be clear where the bottlenecks are (if any). If you start optimizing too early, you run the risk of spending a lot of time optimizing something that turns out to be not important after all.
If the solution to this issue is indeed as simple as suggested by @pelson above, then I would suggest implementing that and switching back to iris v2 (i.e. revert PR #320). That way we will be encouraged to write code that works well with v2 of iris and we will benefit from new features and bugfixes as they appear.