Esmvaltool: vertical level select interpolation errors
This commit (read the commit message as well, please): https://github.com/ESMValGroup/ESMValTool/commit/39fb0e3c460ddc42a7103112b1f0a3de90012c3e patches a behavior that is seen in cases where a lot of data is missing from a model file: namely, vinterp with interpolate returns values order O(1e19) for interpolated data points (the selected level is inbetween two preexisting le
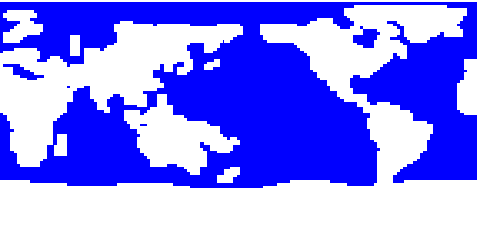
vels). I 'believe' the data masks are not correctly handled by stratify; thresholding the interpolated data is just a kludge, preferably this should be taken up with the stratify developers and discussed. I am attaching a 2D plot of the GFDL model that had a lot of missing data and where this behavior has been noticed.
 valeriupredoi
valeriupredoi
All 31 comments
@valeriupredoi Good to hear from you!
Okay, so to investigate this further we need some simple, sample data that reproduces this issue.
If you think the problem is isolated completely within python-stratify, then I'd raise the issue on https://github.com/SciTools-incubator/python-stratify and we can take it from there.
Is it possible for you to do that?
We can come to some arrangement on sharing the sample data e.g. via google drive or whatever. But to make progress we'd really need sample data and a python script that uses python-stratify to recreate the problem and understand what's going on.
Thanks!
 bjlittle
on 30 Jan 2018
bjlittle
on 30 Jan 2018
@bjlittle thanks for your prompt reply!
I will prepare a test case and mail you the link to download the data.
@valeriupredoi could you create a simple python script that reproduces the problem?
 mattiarighi
on 30 Jan 2018
mattiarighi
on 30 Jan 2018
hey @bjlittle @mattiarighi guys, the problem is that vinterp's interpolator can not handle masked arrays when it has to interpolate while extracting a level that is not present in the nc file ie it treats the missing data as fillvalues (here 1e+20) and it will spit valid data points of orders O(18) or O(19) when dealing with temperatures so order O(100). Example data NOAA-GFDL/GFDL-ESM2G/historical/mon/atmos/Amon/r1i1p1/latest/ta/ta_Amon_GFDL-ESM2G_historical_r1i1p1_200101-200512.nc level 97500 that is not there. @bjlittle could you have a look at python stratify and tell us what you reckon before we start contacting the stratify guys plss? Cheers,
V
valeriupredoi
on 30 Jan 2018
@mattiarighi will do!
valeriupredoi
on 30 Jan 2018
@valeriupredoi I am one of the python-stratify guys 😜 , so I suspect it will be me that looks into this issue.
But I think that I now understand the issue ... it's not behaving correctly when it has to interpolate between two known values, but where one of those known values is actually masked. Is that right?
bjlittle
on 30 Jan 2018
Correct.
mattiarighi
on 30 Jan 2018
Crap, sorry, Bill, didnt know you were. Yes, that's right about the masked
business
On 30 Jan 2018 5:46 pm, "Mattia Righi" notifications@github.com wrote:
Correct.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/ESMValGroup/ESMValTool/issues/205#issuecomment-361655820,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AbpCo0SVdys0GIRVTECiETLCyIJtcHCeks5tP0dFgaJpZM4RyVxU
.
valeriupredoi
on 30 Jan 2018
Just sent you a link to download GFDL-ESM2G model data: it's a temperature field on 17 pressure levels (from 1000 to 10 hPa).
You will notice that the lowermost level (1000 hPa) contains a lot of missing values (due to the orography) and that the number of missing values decreases as you move up (i.e., as pressure decreases).
When we try to interpolate to a different set of vertical levels, the missing value pattern (mask) of the 1000 hPa level propagates to all target levels.
mattiarighi
on 30 Jan 2018
hey @bjlittle @mattiarighi here is a temporary script that you can just run it (provided you put the data nc file in there line 426 ncfile = ...); this does the vertical level selection and you will see the behavior of this issue in the resulting extract_levels_GFDL.nc file https://github.com/ESMValGroup/ESMValTool/commit/ebc95cd804461b92caca3fbf2e1819fe48d92133 -- let me know how I can help fix things :)
valeriupredoi
on 31 Jan 2018
Okay, so I downloaded the data, thanks for that. Just what I needed.
For the first time-step of the air-temperature cube, I've found a single lat/lon column through the atmosphere where the data is masked for the first few (high pressure) ground levels e.g.
>>> data[0, :, 0, 0]
masked_array(data = [-- -- -- -- 243.7404022216797 235.41590881347656 225.4407501220703
218.1466522216797 219.07557678222656 222.51141357421875 226.17079162597656
230.38467407226562 233.05519104003906 235.46205139160156
238.46755981445312 241.10867309570312 252.08206176757812],
mask = [ True True True True False False False False False False False False
False False False False False],
fill_value = 1e+20)
>>> data[0, :, 0, 0].data
array([ 1.00000002e+20, 1.00000002e+20, 1.00000002e+20,
1.00000002e+20, 2.43740402e+02, 2.35415909e+02,
2.25440750e+02, 2.18146652e+02, 2.19075577e+02,
2.22511414e+02, 2.26170792e+02, 2.30384674e+02,
2.33055191e+02, 2.35462051e+02, 2.38467560e+02,
2.41108673e+02, 2.52082062e+02], dtype=float32)
>>> cube.coord('air_pressure')
DimCoord(array([ 100000., 92500., 85000., 70000., 60000., 50000.,
40000., 30000., 25000., 20000., 15000., 10000.,
7000., 5000., 3000., 2000., 1000.]), standard_name=u'air_pressure', units=Unit('Pa'), long_name=u'pressure', var_name='plev', attributes={'positive': 'down'})
So the bottom 4 levels are masked, so let's see if I can recreate the behaviour that you mentioned ...
>>> sample = data[0, :, 0, 0]
>>> z_src = cube.coord('air_pressure').points
>>> z_tgt = np.array([65000, 55000, 45000], dtype=z_src.dtype)
>>> import stratify
>>> stratify.interpolate(z_tgt, z_src, sample)
array([ 5.00000010e+19, 2.39578156e+02, 2.30428329e+02], dtype=float32)
Bingo! The 1st element is the culprit. The python-stratify interpolation is ignoring masks and just using the underlying data, which happens to be 1.00000002e+20, from which it interpolates between that and the next non-masked value 2.43740402e+02
As a strategy, I'd simply recommend that we fill the masked values with NaN's, perform vertical interpolation, and then fill the NaN's in the result with MDI, or turn the result array into a masked array.
Just ensure that this is working as I expect, let's see ...
>>> fsample = sample.filled(fill_value=np.nan)
>>> fsample
array([ nan, nan, nan, nan,
243.74040222, 235.41590881, 225.44075012, 218.14665222,
219.07557678, 222.51141357, 226.17079163, 230.38467407,
233.05519104, 235.46205139, 238.46755981, 241.1086731 ,
252.08206177], dtype=float32)
>>> stratify.interpolate(z_tgt, z_src, fsample)
array([ nan, 239.57815552, 230.42832947], dtype=float32)
Does this sound like an acceptable approach to take?
bjlittle
on 31 Jan 2018
Hi @bjlittle cheers for the investigation! cool that the problem is indeed pinpointed. Have a look at the latest regrid code I pushed yesterday on the zonalmeans branch https://github.com/ESMValGroup/ESMValTool/blob/REFACTORING_zonalmeans/esmvaltool/preprocessor/_regrid.py -- it does what you suggest BUT there's still the need to apply a hardcoded threshold on the large interpolated values that strangely enough live only on the lat-lon borders between existing and missing data. Have a look and let me know, I'll owe you a beer if this will get fixed easily :D
valeriupredoi
on 31 Jan 2018
lines 363 - 396 :)
valeriupredoi
on 31 Jan 2018
@bjlittle I tried reproducing your example using the NCL-based method in the old backend. I get exactly the same numbers, I would say it is correct.
@valeriupredoi is the current version of _regrid.py taking exactly the same approach?
mattiarighi
on 31 Jan 2018
@valeriupredoi Could the large interpolated values that you are seeing be a result of the extrapolation performing linear interpolation? I originally set the stratify extrapolation mode to be nan, see https://github.com/ESMValGroup/ESMValTool/commit/39fb0e3c460ddc42a7103112b1f0a3de90012c3e#diff-ac696e627fac6e38dec3934ffdd38010L366
bjlittle
on 31 Jan 2018
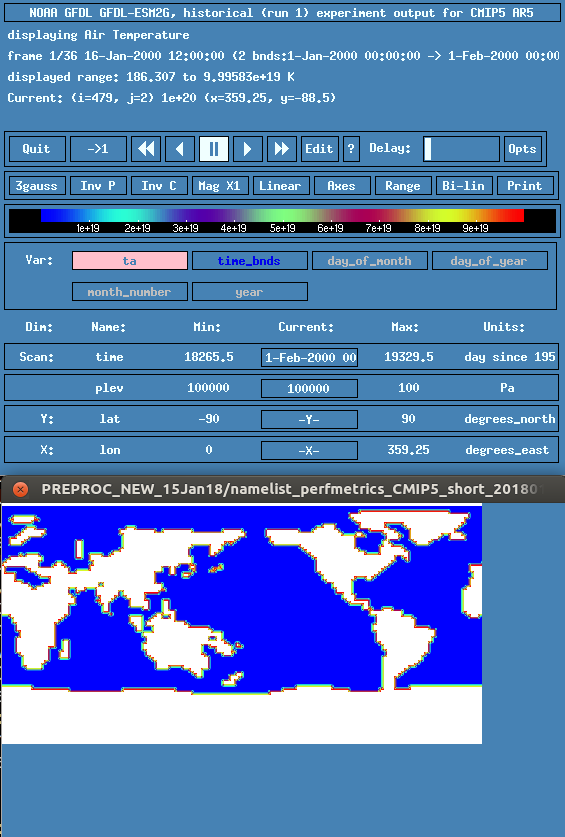
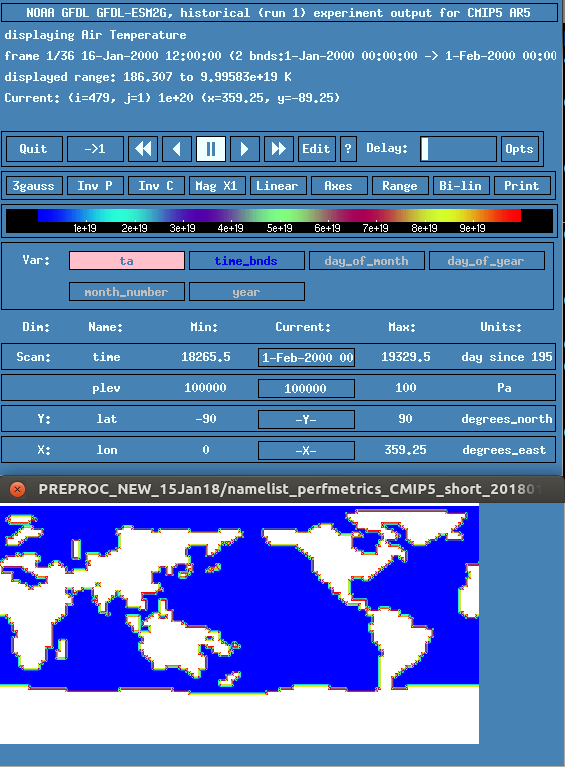
@bjlittle unfortunately I am not seeing any differences in terms of large border values when switching from extrapolation='linear' to 'nan' - see pics :(
valeriupredoi
on 31 Jan 2018
@mattiarighi
is the current version of _regrid.py taking exactly the same approach?
should be, @bjlittle what say you?
valeriupredoi
on 31 Jan 2018
just got on gitter if you guys have time to talk about this there
valeriupredoi
on 31 Jan 2018
OK guys, this should fix it: https://github.com/ESMValGroup/ESMValTool/commit/f1ae1c4c79fc6de18f19393bae30105899a43dad (once and goodly), I have tested relatively throughly, but @mattiarighi we need the a-ok from you and from @bjlittle before I close this
valeriupredoi
on 31 Jan 2018
@valeriupredoi and @mattiarighi
Okay, I remember the need to apply that slicing code that you removed, but wasn't very convinced on the need for it at the time.
The reason that you can safely remove it now is because of my suggestion to clobber the cube data that is masked with NaNs i.e. lines 364-365, before passing it to stratify. Doing this now causes stratify to do the right thing (and honour the land mask) and yield the correct result.
I would suggest that you now replace lines +376 to +384 with the following:
# Calculate the mask based on the any NaN values in the interpolated data.
mask = np.isnan(new_data)
if np.any(mask):
# Ensure that the data is masked appropriately.
new_data = ma.array(new_data, mask=mask, fill_value=_MDI)
Can you make the above change and re-test?
bjlittle
on 31 Jan 2018
Hey Bill, that's awesome, cheers for the explanation and code suggestion,
it'll work fine, on the train now but will commit tomorrow in the morning.
Great team work on this one, we dodged a bullet there :D
On 31 Jan 2018 4:13 pm, "Bill Little" notifications@github.com wrote:
@valeriupredoi https://github.com/valeriupredoi Okay, I remember the need
to apply that slicing code that you removed, but wasn't very convinced on
the need for it at the time.
The reason that you can safely remove it now is because of my suggestion to
clobber the cube data that is masked with NaNs i.e. lines 364-365, before
passing it to stratify. Doing this now causes stratify to do the right
thing (and honour the land mask) and yield the correct result.
I would suggest that you now replace lines +376 to +384 with the following:
Calculate the mask based on the any NaN values in the interpolated data.
mask = np.isnan(new_data)
if np.any(mask):
# Ensure that the data is masked appropriately.
new_data = ma.array(new_data, mask=mask, fill_value=_MDI)
Can you make the above change and re-test?
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/ESMValGroup/ESMValTool/issues/205#issuecomment-361962269,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AbpCo9qSZUpz1CaUWXHGrxDgFbUAkbb7ks5tQIMhgaJpZM4RyVxU
.
valeriupredoi
on 31 Jan 2018
I've made the suggested change (not commited yet) and tested on 1 model (GFDL): there are some tiny differences. It's probably just numerical noise, since ncdiff does not spot them, only ncdump and cdo do.
mattiarighi
on 31 Jan 2018
@mattiarighi But it appears to address the major issue? No more 1e+20 range numbers in the output?
bjlittle
on 31 Jan 2018
@mattiarighi I'd also expect the above change to perhaps also make some of the unit/integration tests for the regridder fail?
bjlittle
on 31 Jan 2018
Yes, it seems to address the major issue (although I need to do some additional test before giving you a final answer, hopefully today).
I would suggest that you now replace lines +376 to +384 with the following:
This does not seem to have any significant effect, so I'll let you guys decide.
mattiarighi
on 31 Jan 2018
That code replacement of Bill fixes an error in my commit that assumes all
cubes have masks, but there is no functional difference from my last commit
for those cubes with masks :)
On 31 Jan 2018 5:20 pm, "Mattia Righi" notifications@github.com wrote:
Yes, it seems to be address the major issue (although I need to do some
additional test before giving you a final answer, hopefully today).I would suggest that you now replace lines +376 to +384 with the following:
This does not seem to have any significant effect, so I'll let you guys
decide.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/ESMValGroup/ESMValTool/issues/205#issuecomment-361985160,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AbpCoyBdttqS7FvzVzszAh65lw4a2PS5ks5tQJLcgaJpZM4RyVxU
.
valeriupredoi
on 31 Jan 2018
Alright, I'll commit Bill's fix and start testing the whole thing asap.
Stay tuned 📺
mattiarighi
on 31 Jan 2018
Personally, I think it's good code hygiene to make the suggested change (but I'm bias).
Also, previously with @valeriupredoi change, masking was being applied regardless, even if there was no mask.
bjlittle
on 31 Jan 2018
Aha, exactly, because bug fixing excitement blinded me :)) awesome,
@mattiarighi
On 31 Jan 2018 5:28 pm, "Bill Little" notifications@github.com wrote:
Personally, I think it's good code hygiene to make the suggested change
(but I'm bias).Also, previously with @valeriupredoi https://github.com/valeriupredoi
change, masking was being applied regardless, even if there was no mask.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/ESMValGroup/ESMValTool/issues/205#issuecomment-361987748,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AbpCo_BvaaoeujnE_qFDfOP5cbFztgggks5tQJSZgaJpZM4RyVxU
.
valeriupredoi
on 31 Jan 2018
The proposed solution indeed breaks the unit tests, as mentioned by @bjlittle . I think the issue can only be closed once those have been fixed too.
 bouweandela
on 22 Feb 2018
bouweandela
on 22 Feb 2018
Question: are we sure we will only ever use vertical interpolation on floating point data? If yes, I can fix the now broken unit test, but if not, I think the vertical interpolation function will need more work (e.g. because np.nan is a floating point number that cannot be converted to an integer, so the proposed solution for this issue only works for floating point data).
bouweandela
on 22 Feb 2018
According to the CMIP5/CMIP6, variables are always of type float/real, while coordinates are double.
I did a quick grep through the CMOR tables and could not find any variable of type integer.
I'm pretty sure that the CMOR tables from other projects stick to this standard as well (e.g. PRIMAVERA, @jvegasbsc ?).
mattiarighi
on 22 Feb 2018
Related issues
bouweandela
·
3Comments
 jvegasbsc
·
4Comments
jvegasbsc
·
4Comments
 lukasbrunner
·
4Comments
lukasbrunner
·
4Comments
 jhardenberg
·
5Comments
jhardenberg
·
5Comments
 jonnyhtw
·
4Comments
jonnyhtw
·
4Comments
Most helpful comment
Personally, I think it's good code hygiene to make the suggested change (but I'm bias).
Also, previously with @valeriupredoi change, masking was being applied regardless, even if there was no mask.