Elasticsearch: Query timeout ignored
Hi again,
I have a timeout specified in all of my queries to prevent some slow queries from backing up the queue, but it doesn't seem to be working at the moment. I have many, many entries in my slowlog anywhere from 2s to 22s for queries with a timeout of 1500ms specified. Here's a snippet of one.
[2013-09-05 13:35:32,967][WARN ][index.search.slowlog.query] [qdave] [quizlet][0] took[6.3s], took_millis[6311], types[], stats[], search_type[QUERY_THEN_FETCH], total_shards[10], source[{"fields":[],"from":0,"size":"50","timeout":"1500ms", ...
As always, anything else I can provide which will help debug this?
 rdeaton
rdeaton
All 11 comments
Perhaps I am actually misunderstanding and the timeout bound forces the hits to be returned, but does not stop the execution of the query, in which case I suppose my question is, how difficult is it to add functionality to do the latter?
rdeaton
on 5 Sep 2013
Indeed the timeout doesn't kill the running query, but that doesn't mean it is ignored. Perhaps you were looking for something like #2929, adding the ability for actually killing a query when the timeout expires? What do you think @rdeaton?
 javanna
on 11 Sep 2013
javanna
on 11 Sep 2013
Closing this one. The current timeout mechanism is a best effort, which might not work with all the queries. The idea behind #2929 is to try and improve this. I'd suggest to watch that issue if you are interested, or reopen this one if you meant something else.
javanna
on 5 Oct 2013
 markharwood
on 1 Aug 2014
markharwood
on 1 Aug 2014
Does Elasticsearch kill a long running query if you set the timeout in the client? Here I'm not talking about killing the TCP connection but actually stopping the long running query from bringing down the node.
Is there a way to set the timeout globally for the cluster (for example in /etc/elasticsearch/elasticsearch.yml)?
If any of these features exist please specify the version in which they have been introduced.
 aalexgabi
on 6 Jun 2016
aalexgabi
on 6 Jun 2016
Does Elasticsearch kill a long running query if you set the timeout in the client?
Timeouts are achieved on a best-effort basis. Timeouts are pushed down to the shard and impact the query phase. Certain things like highlighting and rewriting are not impacted by the timeout.
Is there a way to set the timeout globally for the cluster (for example in /etc/elasticsearch/elasticsearch.yml)?
Yes. There is search.default_search_timeout which is available starting in 2.0.0. This has the same caveat as above, it is best-effort.
 jasontedor
on 6 Jun 2016
jasontedor
on 6 Jun 2016
Having this feature work more accurately is useful beyond #2929. We are trying to use this to stop a query after a certain amount of time so that our search product can always return in a given amount of time. We could make a hacky solution that runs the query async, and then we would stop waiting after a certain amount of time, but the query would then continue to use resources on the elasticsearch server.
Our feature request would be basically an equivalent to mysql's MAX_EXECUTION_TIME. Unfortunately, right now Elasticsearch's timeout parameter can be inaccurate by several orders of magnitude, rendering it useless for our purpose. Our tests have been run against Elasticsearch 5.3
 dylanwenzlau
on 22 Jun 2017
dylanwenzlau
on 22 Jun 2017
Elasticsearch's timeout parameter can be inaccurate by several orders of magnitude
Ensuring timely timeouts is a case of weaving timer checks into all the "hot loops". We've done this for many e.g. the loop for collecting the next doc in a result set. Can you give an example of the problem query that overruns so we can see what un-checked loop might be involved?
markharwood
on 23 Jun 2017
Makes sense.
Here is an example where I specify a 10ms timeout, and the query finishes in 1361ms.
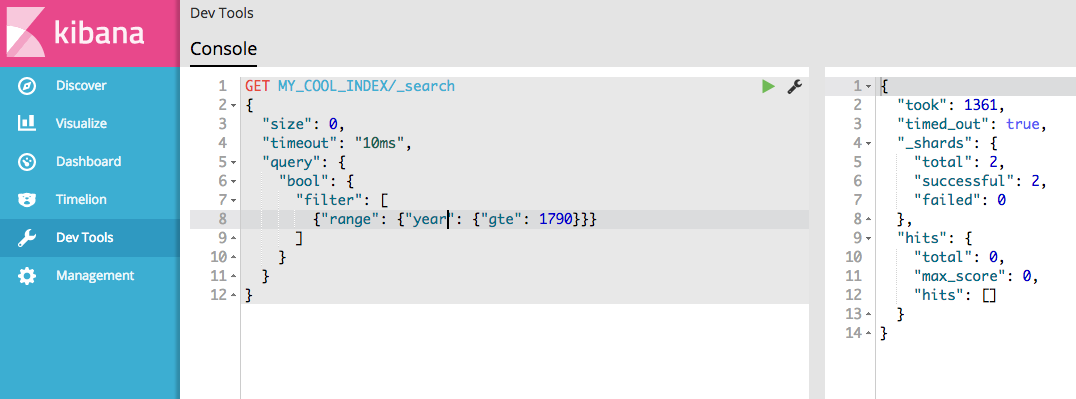
dylanwenzlau
on 23 Jun 2017
Note there is a node-level setting thread_pool.estimated_time_interval that dictates the resolution of the timer used to estimate current time for these sorts of checks (it avoids making timer checks too expensive in hot loops). The default resolution of this is 200ms meaning you can expect overruns of this magnitude but obviously your example is still greater than this.
markharwood
on 24 Jun 2017
any updates on this ?
 vipul-mykaarma
on 23 Nov 2020
vipul-mykaarma
on 23 Nov 2020
Related issues
jasontedor
·
3Comments
 ttaranov
·
3Comments
ttaranov
·
3Comments
 ppf2
·
3Comments
ppf2
·
3Comments
 Praveen82
·
3Comments
Praveen82
·
3Comments
 DhairyashilBhosale
·
3Comments
DhairyashilBhosale
·
3Comments
Most helpful comment
Does Elasticsearch kill a long running query if you set the timeout in the client? Here I'm not talking about killing the TCP connection but actually stopping the long running query from bringing down the node.
Is there a way to set the timeout globally for the cluster (for example in /etc/elasticsearch/elasticsearch.yml)?
If any of these features exist please specify the version in which they have been introduced.