Elasticsearch-dsl-py: Can't understand "word_delimeter" token filter
elasticsearch-dsl==6.2.1
elasticsearch==6.3.1
I have analyzer:
test_analyzer = analyzer(
'test_analyzer',
tokenizer=tokenizer('trigram', 'edge_ngram', min_gram=3, max_gram=10),
filter=['lowercase', 'word_delimiter']
)
This analyzer used in Document:
class TestIndex(Document):
name = Text(analyzer=test_analyzer)
id = Integer()
class Index:
name = 'test-index'
Objects in my Index have next pattern in name:
word1:word2:word3:word4
(there a lot of ":" in name)
As I understood ES docs, with this analyzer I can search my objects by sub-words (like word2 from my example), but really search works only with almost-full-name in query.
My Search request is:
search = Search(
index='test-index'
).query(
"multi_match",
query="word2",
fields=['name'],
fuzziness='AUTO'
)
(returns nothing)
 scherbakovx
scherbakovx
All 7 comments
The problem is with your tokenizer which produces just edge ngrams of length 3-10 from the original input (word1:word2:word3), in your case:
word
word1
word1:
word1:w
word1:wo
word1:wor
word1:word
which is not particularly useful I believe. I would recommend you play around with the _analyze API (0) to find an analyzer that does what you want, in this case I believe you want the simple_pattern_split tokenizer (1) instead:
es.indices.analyze(body={
'text': 'word1:word2:word3',
'tokenizer': tokenizer('split_words', 'simple_pattern_split', pattern=':').get_definition()
})
Hope this helps!
0 - https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-analyze.html
1 - https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-simplepatternsplit-tokenizer.html
 HonzaKral
on 19 Nov 2018
HonzaKral
on 19 Nov 2018
1. I created this analyzer with simple_pattern_split

2. Then I insert object with ':'
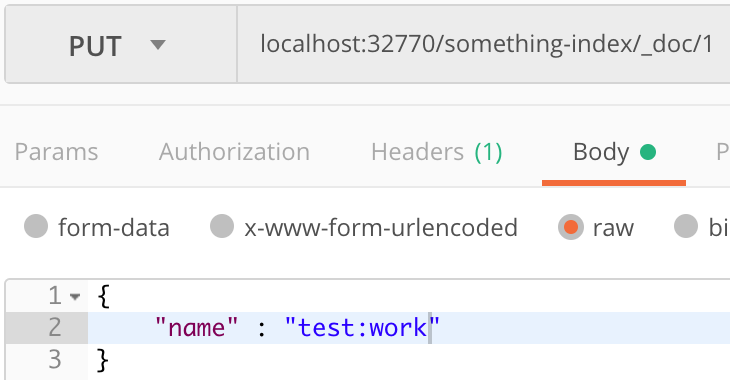
3. Try _analyze with my analyzer and, I suppose, it works.
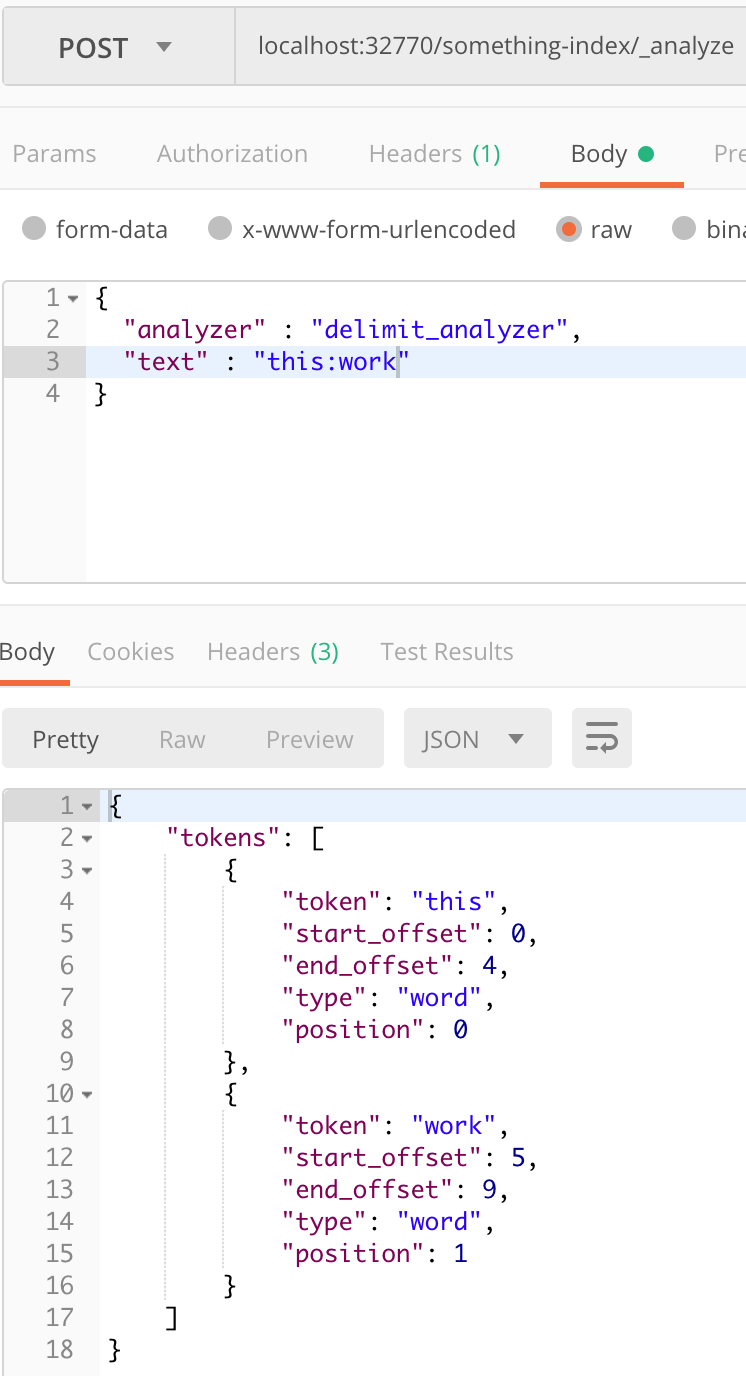
4. But when I try to search for object by its second part, I got nothing.

5. Maybe I am wrong with search part and it's impossible to combine fuziness with such analyzer?
scherbakovx
on 19 Nov 2018
It is very much possible, in fact it is impossible to use fuzziness without an analyzer.
This works just fine for me:
from elasticsearch_dsl import analyzer, tokenizer, connections, Document, Text
# connect
connections.create_connection()
test_analyzer = analyzer(
'testing-1061',
tokenizer=tokenizer('split_words', 'simple_pattern_split', pattern=':'),
filter=['lowercase']
)
class D(Document):
content = Text(analyzer=test_analyzer)
class Index:
name = 'test-1061'
# create the index
D.init()
D(content='word1:word2:word3').save(refresh=True)
assert 1 == D.search().query('match', content='word2').count()
assert 0 == D.search().query('match', content='wordX').count()
assert 1 == D.search().query('multi_match', query='wordX', fields=['content'], fuzziness=1).count()
Can you perhaps share your complete code? Are you creating your mappings and attaching the correct analyzer?
HonzaKral
on 19 Nov 2018
Oh, after posting comment I've understood that I haven't created mapping. Now it works, at least in Postman, now I'll try to use this in Python. Thank you so much, you've saved me a day! <3
scherbakovx
on 19 Nov 2018
Sorry for re-opening, but it still strange in Python...
I've fully copy-paste your code, except connection, I have connections.create_connection(hosts=['localhost:32770'], timeout=20) with ES (6.4.3) in Docker and the first test is failing... I've even deleted index with DELETE localhost:32770/test-1061*, after this I run Django and this is what I get in console AssertionError on assert 1 == D.search().query('match', content='word2').count()
scherbakovx
on 19 Nov 2018
can you just print out the result instead of the assert? My guess would be that the code is accidentally run twice so the document is duplicated. Or just print out the hits instead of just a count().
HonzaKral
on 19 Nov 2018
You are right about duplicates, sorry :( Now everything is fine in Python too.
scherbakovx
on 19 Nov 2018
Related issues
 arizhakov
·
4Comments
arizhakov
·
4Comments
 mortada
·
3Comments
mortada
·
3Comments
 amih90
·
4Comments
amih90
·
4Comments
 beanaroo
·
4Comments
beanaroo
·
4Comments
 vmogilev
·
4Comments
vmogilev
·
4Comments
Most helpful comment
The problem is with your
tokenizerwhich produces just edge ngrams of length 3-10 from the original input (word1:word2:word3), in your case:which is not particularly useful I believe. I would recommend you play around with the
_analyzeAPI (0) to find an analyzer that does what you want, in this case I believe you want thesimple_pattern_splittokenizer (1) instead:Hope this helps!
0 - https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-analyze.html
1 - https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-simplepatternsplit-tokenizer.html