Efcore: Long Load Times For Large Datasets - Possible Solution?
I'm a relative novice to EF and EF Core, but one of the things that has been really bothering me is the amount of time it takes me to load a large dataset. Googling this, it seems to bother quite a few people. It may be clear to everyone developing the project what's causing this slowdown, but I wanted to start a discussion in case it isn't, and hopefully work towards a solution that makes the project better.
Reading about common frustrations with EF Core, you'll find that most people suggest that to decrease load time for large datasets that you don't intend on changing, you should set:
Context.ChangeTracker.AutoDetectChangesEnabled = false;
Context.ChangeTracker.QueryTrackingBehavior = QueryTrackingBehavior.NoTracking;
After trying to load a dataset 1.6M rows deep with these options set as listed, I still found the performance to be less than stellar. SQL Server Express will return these rows to me in a mere 20 seconds, but the total time to load them using EF was 428 seconds.
So, I cloned the most current version of the code and added it to my project. After stepping through everything, I found that there is a reason: a relatively hidden function in EFCore, Microsoft.EntityFrameworkCore.Query.Internal.WeakReferenceIdentityMap
Since I've not been around this project for a while, I can't speak to this function's necessity. But because I did load up the code, I was able to gather some empirical statistics surrounding my particular dataset with and without this function call. Below, you'll find two images illustrating the cumulative and incremental time taken inside the entity framework code to load the entire dataset into memory. Each image shows two series: one with CollectGarbage() enabled, and one with the call to CollectGarbage() commented out.
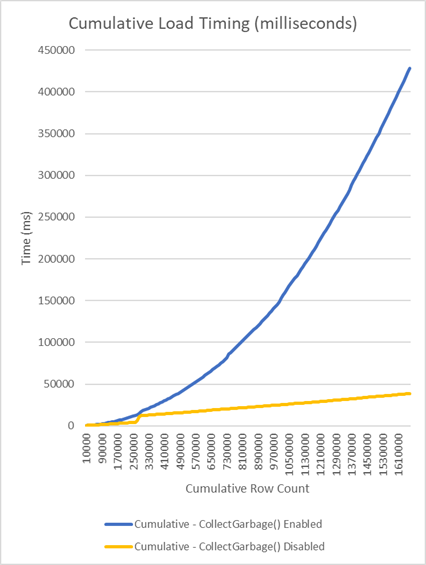
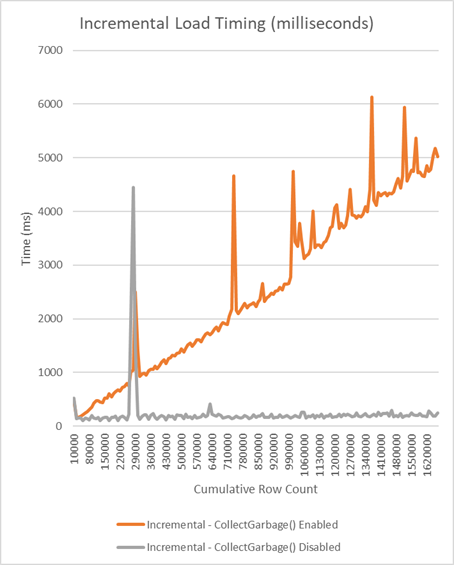
As you can plainly see, this function seems to be adding O(N^2) complexity to basic loading of entities. An inspection of the offending function yields a little insight. Every 500 rows loaded will cause an inspection of the full array of already-loaded objects.
private const int IdentityMapGarbageCollectionThreshold = 500;
...
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public void CollectGarbage()
{
if (++_identityMapGarbageCollectionIterations == IdentityMapGarbageCollectionThreshold)
{
var deadEntries = new List<TKey>();
foreach (var entry in _identityMap)
{
if (!entry.Value.TryGetTarget(out _))
{
deadEntries.Add(entry.Key);
}
}
foreach (var keyValue in deadEntries)
{
_identityMap.Remove(keyValue);
}
_identityMapGarbageCollectionIterations = 0;
}
}
That's basically my report. I don't know if anything can be done about this, because simply I don't understand the ramifications of removing it or disabling it. If there are few ramifications and we could have the option to disable this feature at the very least, I am certain many users would appreciate it.
Further technical details
EF Core version: 2.2.0-preview2-35143
Database Provider: Microsoft.EntityFrameworkCore.SqlServer
Operating system: Win 10 Pro
IDE: (e.g. Visual Studio 2017 15.9.0 Preview 3.0)
 cculver
cculver
All 16 comments
Decision from triage: this is the weak map that is used to do identity resolution with no-tracking queries. For 3.0, we will stop doing identity resolution for no-tracking queries.
 ajcvickers
on 5 Oct 2018
ajcvickers
on 5 Oct 2018
@cculver Also, thanks for the epic filing. The graphs are compelling. :clap:
ajcvickers
on 6 Oct 2018
Thanks for your time and hard work on such a worthy project - all of you.
cculver
on 6 Oct 2018
@ajcvickers I have a question regarding your statement _"For 3.0, we will stop doing identity resolution for no-tracking queries."_.
Does this mean that you plan to completely remove identity resolution in combination with AsNotTracking in 3.0, without an option to enable it?
I would not be happy if this will be removed without an option to enable it.
The documentation of QueryTrackingBehavior.NoTracking clearly states that:
Identity resolution will still be performed to ensure that all occurrences of an entity with a given key in the result set are represented by the same entity instance.
Please consider adding a new Option to QueryTrackingBehavior.NoTrackingNoIdentityTracking instead of changing the behavior.
Benefits:
- No breaking change, usage of NoTracking and identity resolution is a good thing for some scenarios
- Still allows users to disable identity tracking, if they see a performance improvements.
- Can reduce memory usage + GC-Time if specific instances are very common in a query (ex. a company query where most companies reference the same country). With IdentityResolution=Off, this would lead to multiple duplicates instances of the same logical entity.
 davidroth
on 10 Oct 2018
davidroth
on 10 Oct 2018
@davidroth Tracking queries will still do full identity resolution. In essence, no tracking queries were trying to behave like tracking queries in this respect, since normally the tracking is what provides the identity resolution.
ajcvickers
on 10 Oct 2018
@ajcvickers So to recap, NoTracking in EF 3.0 will not perform any identity resolution, right? Will we have at least identity resolution within each materialisation phase (per query) when using NoTracking?
davidroth
on 10 Oct 2018
@davidroth Current plan is to go back to the EF6 way of doing things for this, so no.
ajcvickers
on 10 Oct 2018
@davidroth after this change is effective, if you want a query to execute with identity resolution within its results, but without interfering with the context’s state, you can still do so by executing the query on a separate DbContext instance. I wonder if we can make that easier than it is now. I am also curious what kind of queries you are concerned about returning duplicate instances.
 divega
on 10 Oct 2018
divega
on 10 Oct 2018
@divega Nothing specific in my mind. I was just thinking, that there might be usages in disconnected scenarios, where one would like to have the combination of "NoChangeTracking + IdentityTracking" (Better query performance because no ChangeTracking is involved but still have unique instances in the resulting graph).
Sure, spinning up a new context with Tracking enabled, will give you Identity tracking. But this always comes with the price of populating EntityEntries with Old/NewValues etc.
davidroth
on 11 Oct 2018
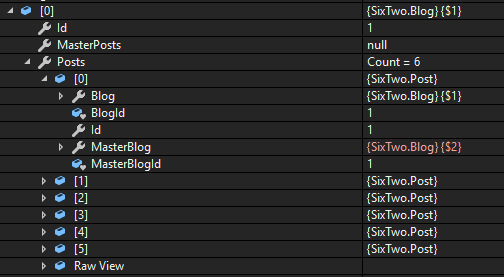
Note from planning: I re-tested the behavior in EF6 and confirmed that it does not do any identity resolution beyond a single navigation. For example, with this model:
```C#
public class Blog
{
public int Id { get; set; }
public ICollection<Post> Posts { get; set; }
public ICollection<Post> MasterPosts { get; set; }
}
public class Post
{
public int Id { get; set; }
public int? BlogId { get; set; }
public Blog Blog { get; set; }
public int? MasterBlogId { get; set; }
public Blog MasterBlog { get; set; }
}
And this query:
```C#
var blogs = context.Blogs
.AsNoTracking()
.Include(e => e.Posts.Select(p => p.MasterBlog))
.ToList();
Note that:
- Fixup between Blog and Posts is correct in both directions
- Fixup between Post and MasterBlog is correct in both directions
- But, there are two different instances of Blog for the two relationships, even though these are the same entity.
ajcvickers
on 31 Jan 2019
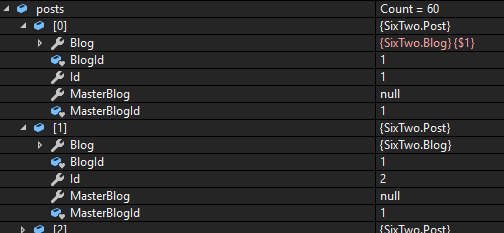
@ajcvickers - For query like context.Posts.AsNoTracking().Include(p => p.Blog) are all the posts of single blog refers to same blog in their navigation?
 smitpatel
on 31 Jan 2019
smitpatel
on 31 Jan 2019
@smitpatel Nope.
ajcvickers
on 31 Jan 2019
@ajcvickers @smitpatel
Like I mentioned in my previous comment, I think it would be more natural, if all the posts of a single blog would refer to the same blog in their navigation.
I would describe this as a "lightweight navigation property fixup strategy".
Given the AsNoTracking() has been applied, EFCore would perform entity resolution within a specific query. Of course, no State-Tracking (EntityEntries+Values) would be performed, because the intention is not to perform a subsequent SaveChanges() when using AsNoTracking().
Also, a subsequent query would not re-use the entities of a previous query, even when in the same context. This would avoid keeping around a weak reference list forever (with all the associated problems, as described https://github.com/aspnet/EntityFrameworkCore/issues/13518#issue-367301875)
Ex.:
var list1 = context.Posts.AsNoTracking().Include(p => p.Blog).ToList() // Returns distinct blogs/post instances
var list2 = context.Posts.AsNoTracking().Include(p => p.Blog).ToList() // Not the same instances as in "list1", but still distinct in list2
This would return different blogs/post instances per ToList() but non-duplicates within a ToList().
I think this behavior could reduce GC pressure when loading large lists, because entities would not have to be materialized multiple times. By not tracking entities beyond a given materialization (.ToList()), it would not lead into problems of huge weak-reference lists.
What do you think about this suggestion? :-)
davidroth
on 1 Feb 2019
@davidroth That's essentially what we try to do now. But it's added complexity, which leads to bugs like this one, for something that we don't think is especially useful. We could always revisit this in the future, but for now we think it's more pragmatic to go back to very simple semantics and implementation.
ajcvickers
on 1 Feb 2019
The query pipeline no longer does identity resolution for no-tracking queries, so closing this.
ajcvickers
on 12 May 2019
Re-opening: breaking change documentation is missing.
ajcvickers
on 5 Aug 2019
Related issues
 miguelhrocha
·
3Comments
miguelhrocha
·
3Comments
 ghost
·
3Comments
ghost
·
3Comments
 ryanwinter
·
3Comments
ryanwinter
·
3Comments
 leak
·
3Comments
leak
·
3Comments
 ra0o0f
·
3Comments
ra0o0f
·
3Comments
Most helpful comment
@cculver Also, thanks for the epic filing. The graphs are compelling. :clap: