dvc push is extremely slow if you don't specify a particular thing to push
I'm so used to just doing git push that I sometimes mistakenly do dvc push, but it is incredibly slow because of cache querying. It would be great if it could be made faster so that you didn't have to always be careful to just push the last thing you added.
 greaber
greaber
All 5 comments
Hi @greaber, what DVC version are you currently using?
Remote cache query performance has been significantly improved in the DVC 1.0 pre-release: https://dvc.org/blog/dvc-3-years-and-1-0-release#data-transfer-optimizations. I would suggest trying out the pre-release and seeing if the new optimizations work for you.
 pmrowla
on 7 May 2020
pmrowla
on 7 May 2020
Also we've released 0.94.0 with those changes, so users don't have to use a 1.0 alpha release.
 efiop
on 7 May 2020
efiop
on 7 May 2020
Thanks! It is four times faster with these changes. But it still takes almost three minutes to do a push on a repo that has nothing that needs pushing. Isn't there some way to make such pushes instantaneous? Like dvc could just know what you have added or changed and not yet pushed. And similarly for pulls, it seems like there could be some heuristics that could make huge speed increases in many common cases. I admit, though, I haven't thought through the details.
greaber
on 7 May 2020
Isn't there some way to make such pushes instantaneous? Like dvc could just know what you have added or changed and not yet pushed.
There are some considerations we need to take into account for DVC, such as the possibility that another user has run gc -c on a remote since the last time you pushed (and potentially removed data that now needs to be re-pushed). But in general yes, we will continue to optimize this case as much as possible.
Could you share a bit of information about your use case/dataset? In particular, does your dataset have a lot of standalone files (i.e. individually dvc add <filename>-ed files, or directories that you add using dvc add --recursive <dirname>?
Also, one other minor question, when you tested 0.94.0 or 1.0 alpha, did you try running dvc push (with no data that needs to be pushed) more than once?
This only applies to directories added without the --recursive option, but we now do some indexing of the remote. But when you first upgrade to 0.94.0 or 1.0a, there will be no pre-existing index for your remote. So the first time you run dvc push after upgrading, DVC has to do roughly the equivalent of querying the remote for your entire dataset (even with unchanged data). But after that, any time you run dvc push or status -c, DVC should do a much better job of only querying for the changed parts of your dataset.
pmrowla
on 8 May 2020
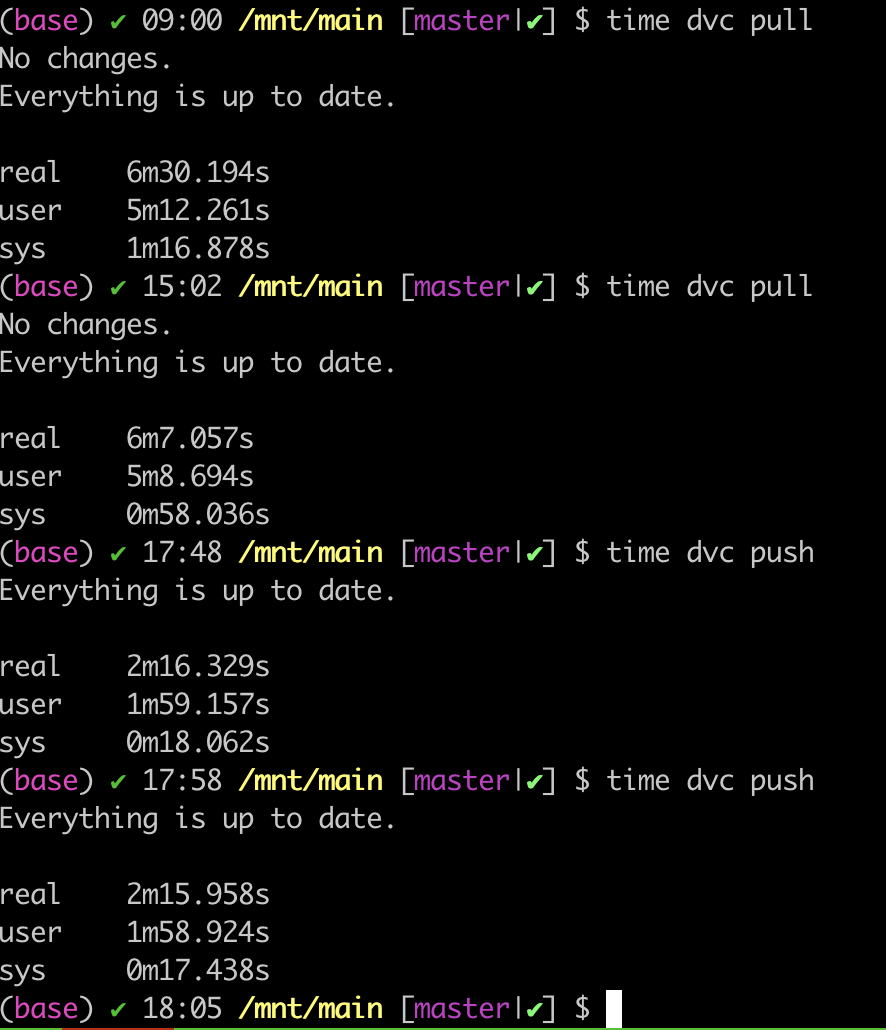
Multiple pulls and pushes make no difference, as the image shows.
There is not a large number of dvc files, but there are a lot of directories with many files that I add. Probably it would be a lot faster if I used archive files, but I know you suggest adding the unpacked directory structures directly, rather than archive files.
greaber
on 9 May 2020
Related issues
 robguinness
·
3Comments
robguinness
·
3Comments
 dnabanita7
·
3Comments
dnabanita7
·
3Comments
 mfrata
·
3Comments
mfrata
·
3Comments
 nik123
·
3Comments
nik123
·
3Comments
 tc-ying
·
3Comments
tc-ying
·
3Comments
Most helpful comment
Multiple pulls and pushes make no difference, as the image shows.
There is not a large number of dvc files, but there are a lot of directories with many files that I add. Probably it would be a lot faster if I used archive files, but I know you suggest adding the unpacked directory structures directly, rather than archive files.