Opening this issue to start the discussion on how should we approach the implementation of the DVC performance tests (aka time testing, aka benchmarking, etc).
Motivation:
As we go we should see performance degradation. For example, someone made a heavy import that affects CLI time to show something (this dvc help that should run in ms). Or, we implemented some dvc checkout logic that affects performance. Now, we have to run every time manually some additional checks. It's fragile, people tend to forget to run it, etc.
Requirements:
- [ ] Cross-platform - Windows, Max, Linux. There are some system-specific scenarios we would like to monitor and catch (100K+ files in NTFS dir). https://github.com/iterative/dvc-bench/issues/14
- [ ] Supports automation - run at least nightly on more or less same stack of machines to being able to compare to previous runs. https://github.com/iterative/dvc-bench/issues/15
- [ ] Ideally, creates a ticket with p1/p0 automatically to investigate on a certain threshold.
- [ ] Ideally, can try binary search to figure which commit affected this. https://github.com/iterative/dvc-bench/issues/8
- [ ] At least nightly reports to see changes. https://github.com/iterative/dvc-bench/issues/15
- [x]
Support for bash/python scripts to run.using python for now because bash is hard to run on windows. And it is easier to profile with python. - [x] Easy to run a specific test/all tests locally with a specific DVC installation.
- [x] Easy way to add new tests.
Implementations:
- We should definitely take a look at other projects (cpython? databases?), available cloud solutions for this?
- How do we implement this: separate repo
dvc-testvs a directory in the main repotests/timeortests/benchor whatnot.
dvc-testseems to be more flexible to my mind, I don't see any downsides if it's implemented rightdirectoryapproach: @Suor could you put a comment - what specific advantages do you see here that could not implemented in thedirectoryone?
@iterative/engineering any thoughts? any comments are welcome - I'll be editing this ticket to come up with a good summary.
 shcheklein
shcheklein
All 30 comments
Sharing some of my thoughts
Reproducibility
We need to make sure tests are run at machines with +/- constant computation power, so that ourt tests will not be affected by hardware upgrades. Probably we should consider caching info about benchmark system hardware, to be able to notice if change in performance happend due to hardware, or even rerun test (for example for major versions) when test machine has change, so that we have some context.
Monitoring
At least nightly reports to see changes.
We should probably be storing somewhere our tests results for different revisions and visualise them so that we have easy to read chart performance(time). Something like grafana/kibana, or even just pyplot chart embedded in html would be nice indicator that could let us know that some change introduced major slowdown.
 pared
on 18 Sep 2019
pared
on 18 Sep 2019
We can take as an example the pyperformance benchmark suite.
--affinityoption to force running the commands on a given CPU list. (We can leveragecgroupsin Linux)- Real examples
I don't find any problem with having this benchmarks under the DVC repository.
Django also has their own benchmarks.
 ghost
on 18 Sep 2019
ghost
on 18 Sep 2019
Re separate repo dvc-test vs a directory in the main repo tests/time...
@Suor brought a good point - people will need the tests in the development stage. So, keeping test in dvc repro will make the tests more useful. However, for the automation (running tests periodically, creates a ticket etc) a separate system and repo might be needed.
It looks like it makes sense to start developing the perf-tests in dvc repo.
 dmpetrov
on 18 Sep 2019
dmpetrov
on 18 Sep 2019
I don't see a connection between "needed in the development stage" and one repo vs two repos. I've seen this organized very well, and I don't remember any problems with running the test harness from a separate repo - the difference should be - cd ../tests vs cd bench.
On the other hand It's clear how creating it in the same repo limits the flexibility and overcomplicates the repo.
- One travis config when you need two.
- Different requirements in terms of flake, black, other linters.
- Will have to always remember to exclude it from different analyzers.
- If it grows beyond just perf testing and will include integration tests (that can and should serve as perf tests as well).
- if we decide to save results via DVC (and we should), save data that is used to test it (and again we should!) it means that dvc core repo will handle all of this, will potentially have a branch to run and save results - not nice.
Also, it feels natural - because it should be decoupled from a specific DVC installation it is testing - it should be one of the core functions to test any of the provided DVC packages (pip, deb, etc) and this logic is a higher level.
shcheklein
on 18 Sep 2019
I see it completely differently. @shcheklein brought a long list of things that are potentially desirable, it is however a big question whether we really need all of them or will need at some point. Even if we will decide that we do need all of those then it's non-obvious when it will be implemented, it might easily turn into another dead horse like dvc-test repo is.
I am proposing to start from something, which can benefit us immediately and which could be started written right away, - bench scenarios to be run manually to reproduce performance issues. And that makes little sense to separate those into some other repo. If in the future we will implement the sophisticated system proposed by Ivan we can reuse these bench scenarios either moving them out or not.
 Suor
on 19 Sep 2019
Suor
on 19 Sep 2019
@Suor I can agree that some things are advanced and it'll take a while to build them. Some of the things in that list should be done day zero/day one (e.g. automation, reporting on a nightly basis from the same environment, handling data to run these tests, etc). They will already require creating a proper framework.
Also, I still don't any reasonable downsides starting it as a separate repo. No one mentioned it to me still. All the arguments (easy to run, benefit immediately, etc) don't contradict starting with a separate project.
shcheklein
on 19 Sep 2019
I would like to support @shcheklein on this one.
Some tests might require us to create dvc repo, first real-use case scenario that comes to my mind is timing adding some well known dataset (CIFAR, MNIST or even ImageNet). Do we really want to keep sample repos under main repo?
If we want simple benchmark that starts benefiting us immediately, why not create sub-repos under
dvc-test and just time -ing dvc repro each one?
I also don't see how would we store performance tests results in main dvc repo in a way that would be easily accessible. dvc-test would be our playground, so we could even embed pyplot charts in README.
pared
on 19 Sep 2019
Why don't we start right away with a separate directory (looks like almost everyone is in favor) and then move it to this repository if needed (or if it turns out as a simpler solution)?
ghost
on 19 Sep 2019
+1 for separate iterative/dvcbench repo
Side note: If we could figure out a way to extract the time stats from each passed build in https://travis-ci.com/iterative/dvc/pull_requests. E.g.
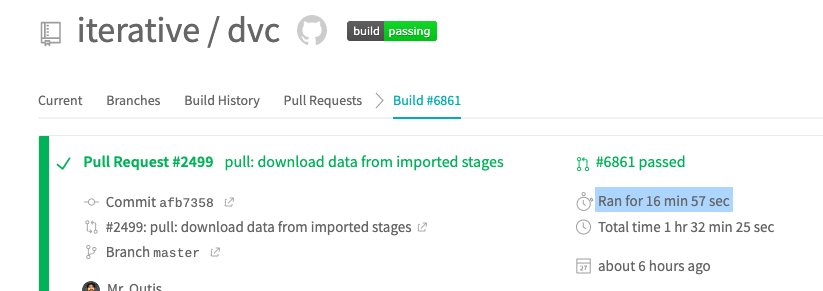
could that give us an idea of how the performance of dvc has evolved so far?
 jorgeorpinel
on 19 Sep 2019
jorgeorpinel
on 19 Sep 2019
@jorgeorpinel Hmm, that could be something that we should be monitoring, but main problem with build time (so far) was setup of environment as I recall, and @efiop was handling that in few pull requests. (#2361) I would agree that monitoring build time is important, but I would not consider it performance metric. We could try to extract tests run time, thought (pytest reports that in log), that is something that could be performance metric.
pared
on 20 Sep 2019
@pared @jorgeorpinel yep, also, it's not a good metric since number of tests is changing.
shcheklein
on 20 Sep 2019
@iterative/engineering is there an agreement that we can commit to on this one?
ghost
on 30 Sep 2019
Looks like mercurial had same problem:
Mercurial code change fast and we must detect and prevent performances regressions as soon as possible.
After trying out different tools, they went with asv (their benchmarks).
Their plan for performance tracking is documented.
Here's the presentation regarding asv [2014]:

 skshetry
on 6 Apr 2020
skshetry
on 6 Apr 2020
@shcheklein this sounds like a big task; but I think actually reasonably straightforward. I'd recommend just using asv in a daily travis/circleci/gha cron job. Some notes:
- I'd suggest doing this in
dvc-test
- basically requires creating
asv.conf.json, a directory containing benchmark scripts, adding 3 lines to.gitignore, and adding a few lines to a new CI job
- basically requires creating
- also can post the rendered results to dvc-test@gh-pages so visible at https://iterative.github.io/dvc-test (would look like https://pv.github.io/numpy-bench or as @skshetry posted http://perf.octobus.net)
- can easily use github api to open an issue at certain thresholds. Could also maybe do some sort of badge thing.
- can run on different platforms via the chosen cloud CI
- asv plots the entire history of commits so it's easy to zoom in on a performance regression
- can support testing CLI via
subprocess.call
Yes, there are issues with cloud CI jobs running on different machines under different load thus affecting tests but there are work-arounds for this too.
Also you'd be able to run benchmarks locally on a range of commits using
pip install asv
gh clone iterative/dvc-test && cd dvc-test
asv run <dvc_commit_1>..<dvc_commit_2> && asv publish && asv preview
Feel free to open issue(s) and assign any of these tasks to me :)
 casperdcl
on 16 Apr 2020
casperdcl
on 16 Apr 2020
also potential options: pytest-benchmark as well as buildkite (click on images to go to the sites):


casperdcl
on 13 May 2020
What do we need?
A set of tests that will be able to show differences in performance
of DVC across the development timeline.
Some more precise expectations:
By default we should run our tests on releases, so we need somehow
to specify “target” revisionsSooner or later we will find a release that introduces considerable
downgrade in performance. In that case, we should have a tool
that would allow us to pinpoint which commit introduced
“the biggest” downgrade.Thinkgit bisect, but with a visual
aid that would let us see the performance throughout history.Handling error-ed tests: we need to store failed test logs, to be
able to verify whether it was some error and we can rerun, or
for example, this particular revision does not “support” the testNeed to be able to specify which tests can be excluded from running
for given revision. We don’t want to run tests for previously not
existing functionality and fail each time we run the tests.Visualization: we need to process benchmarks results and display
them.Need to store information on execution machine setup,
it would be nice to rerun particular revisions when the machine changes.
(eg our machine provider changed it, and we cannot rely on previous
tests)
What can we try to work with?
cProfile, hyperfine (https://github.com/sharkdp/hyperfine) or even
timeThe main problem is that those tools only provide a way to benchmark
particular pieces of code. All points {1-6} would need to be developed in one
or another way by us.https://github.com/wesm/vbench - from description looks like
something that might be of use for us, seems abandoned,
no documentation, links are leading to 404, I would need to
spend more time on that to see the functionalitycodespeed (https://github.com/tobami/codespeed) is a Django
application
• supports execution machine info
• sending run data through API, so this is more of an
visualization tool rather than benchmarking, we will
need to handle points {1-4}
• is a web-app, so will require productionized setup and maintenance
• data stored in Django databaseairspeed velocity (https://github.com/airspeed-velocity/asv) - command-line tool
• promotes writing test-like benchmarks
• has visualization support
• can specify python versions in configuration
• machine information storing
• running benchmarks is commit-centered, eg supports running
benchmarks from..to commits, ALL, EXISTING (benchmark all commits
tested on other machines), can specify required commits in a file
and use asv run HASHFILE:hash_file.txt (in this case I tried also
specifying tags, and they seem to run, though there are some
warnings when I try to display them)
• results stored in JSON files
• has asv profile command for profiling, can specify GUI, eg SnakeViz
• I am not yet sure about points {3, 4}
• visualization tool is a web app, but it works on
run results that are json's so we are not bound byasvhere, and can produce
our own, though some processing will be inevitable
It seems to me that asv is the best competitor so far.
As @casperdcl pointed out we should probably put our benchmarks in a separate
repository, as some of our tests might be heavy. For those tests,
it would be good to store the results using DVC, and don’t run
them again if it's not absolutely necessary (eg. test machine changed).
Storing results will require us to create “asv run commits”, and that
is the reason why we should not include benchmarking suite in main DVC
repo. It will clutter our git history.
pared
on 13 May 2020
@pared one more reason to decouple (just to reiterate) that I think important:
because it should be decoupled from a specific DVC installation it is testing - it should be one of the core functions to test any of the provided DVC packages (pip, deb, etc) and this logic is a higher level.
comes down to being able to test different versions of DVC w/o affecting the test suite.
shcheklein
on 13 May 2020
to be even more explicit, tests should be in dvc-test but there'll also be an entry in the main repo's travis.yml to trigger testing on master commits. This may simply pull dvc-test and run an entrypoint, though there are other options. Historical logs (i.e. asv json outputs) should be DVC-controlled and cached in some could storage.
casperdcl
on 14 May 2020
Looking at https://github.com/iterative/dvc-test/pull/9 , makes total sense to me to create a separate git repo for that. Like dvc-benchmark or something. Current dvc-test is more about testing that packages are installable, no need to bother with it in the benchmark for now. Also asv provides built-in profiler reports, which won't be usable for non-python packages, so there is even less reasons to put it into the current dvc-test. If we will end up investing the time to test non-python packages in asv (i don't see a point in doing that, because it will require too much effort for too little value, as 99% of things will be visible in python packages), we might combine those, but not for now.
 efiop
on 14 May 2020
efiop
on 14 May 2020
For the record: discussed with @pared that we should store the results in dvc in the same repo and commit them with a bot user that we need to create.
efiop
on 14 May 2020
Yes, definitely. Bot (machine) users are within GitHub's user policy.
casperdcl
on 14 May 2020
makes total sense to me to create a separate git repo for that
Sure, I think we're all agreed on the main point to not clutter the main repo
test non-python packages in asv
Pretty easy work-around if required using os.system() within a python benchmark function.
casperdcl
on 14 May 2020
During GitHub actions research, I found this:
https://github.com/marketplace/actions/continuous-benchmark
Seems like it promotes pytest-benchmark mentioned by @casperdcl
So, another candidate.
pared
on 15 May 2020
Not sure if that does it for each commit, but just have to note that we won't be able to do it for every commit, as our benchmarks will probably take too long to run (we want to simulate real use cases). We need scheduled runs for tags that will run once a day or even once a week. Maybe with triggers for new tags even, not sure.
efiop
on 15 May 2020
I think it's just a render for the json output of pytest-benchmark, which we'll have to run ourselves
casperdcl
on 15 May 2020
Ok, so a little summary on progress so far:
- I created
dvc-benchrepo utilizingdvcandasvto perform the benchmarks. - I set up GitHub Actions as a runner for now as it was seemingly the fastest way to set up the environment for benchmarks (in case of
buildkiteit seems like one needs a machine for building and installing, only then can proceed with benchmarking workflow) - For now each time we PR, all benchmarks will be reproduced. Further progress of this issue could include modifying the repo in a way that we won't rerun all benches if we happen to run the benchmarks on the same (similar?, in terms of computational power) machine.
- Altogether with point 3 we could think of running the benchmarks on a particular machine, so far we "draw" one from Azure. I have already seen runs performed on 2 threaded Xeon as well as 6 threaded. We can think of moving the build to buildkite then, though GitHub actions also allow to set up custom worker. This will be important in particular, when we will start writing benchmarks checking
--jobsarg influence. - GitHub Actions have one more advantage.
pared
on 19 May 2020
@pared Sorry if I've missed it something, but why did we choose asv compared to pytest-benchmark for now?
efiop
on 25 May 2020
@efiop
pytest-benchmarkties us to github-actions, whileasvcan be installed on any machine supporting python. We can always migrate our benchmarks to a different methods of running.asvhas easy way of running the profiler on a particular commit and benchmark. When we see degradation, we can just check out the project and go forasv profile {benchmark} {revision}.I could not find information for
pytest-benchmarkon how to trigger just specific commits. We don't want to run all benchmarks on every commit, as we expect them to test real use cases, like adding big datasets, which will be time and resource consuming.I could not find the notion of "runner" specification for
pytest-benchmark. (Creator suggest hosting own runner for stable benchmark results)[https://github.com/marketplace/actions/continuous-benchmark#stability-of-virtual-environment].asvby default uses current machine specification as a run identifier, so there is no chance that benchmarks run on different machines will be compared to each other.
[EDIT]
I was talking here about github actions supporting pytest-benchmark.
As to pytest-benchmark alone, its just faster for us to use asv, because we don't have to set up the whole framework for iterating over commits, executing benchmarks, visualizing results and handling execution machine.
pared
on 25 May 2020
@pared moved some tickets to https://github.com/iterative/dvc-bench/issues . Please take a look if I've missed anything important.
Maybe we could close this ticket and move to dvc-bench issues?
efiop
on 25 May 2020
@efiop
I agree
pared
on 25 May 2020
Related issues
 GildedHonour
·
3Comments
jorgeorpinel
·
3Comments
GildedHonour
·
3Comments
jorgeorpinel
·
3Comments
 analystanand
·
3Comments
analystanand
·
3Comments
 mdscruggs
·
3Comments
mdscruggs
·
3Comments
 prihoda
·
3Comments
prihoda
·
3Comments
Most helpful comment
@shcheklein this sounds like a big task; but I think actually reasonably straightforward. I'd recommend just using
asvin a daily travis/circleci/gha cron job. Some notes:dvc-testasv.conf.json, a directory containing benchmark scripts, adding 3 lines to.gitignore, and adding a few lines to a new CI jobsubprocess.callYes, there are issues with cloud CI jobs running on different machines under different load thus affecting tests but there are work-arounds for this too.
Also you'd be able to run benchmarks locally on a range of commits using
Feel free to open issue(s) and assign any of these tasks to me :)