Dvc: automatic log files for dvc run/repro
I would love to see support for automatically tracking and redirecting stdout/stderr to a log file via an option to dvc run/repro. This will make it much easier to run via nohup or running on remote servers more generally.
 AlJohri
AlJohri
All 15 comments
@AlJohri Do you mean something like dvc run --stdout my.log ...(and similarly --stderr) or something else?
 efiop
on 14 Aug 2019
efiop
on 14 Aug 2019
I think I had the same idea (see Discord context) - add a --stdout foo flag to dvc run, e.g.
dvc run -d input.csv --stdout output.csv mycommand.sh
which would basically be equivalent to
dvc run -d input.csv --outs output.csv 'mycommand.sh > output.csv'.
Name is negotiable of course.
Was thinking of this as a way to avoid using shell-isms in simple cases, and to avoid repeating the filename.
 kenahoo
on 14 Aug 2019
kenahoo
on 14 Aug 2019
@kenahoo , @AlJohri, I don't get the benefit of DVC implementing an option of doing I/O redirections, would you mind elaborating a little bit more? :)
What I like about the current implementation is that the cmd is explicit about what will happen and you are not tying it to any DVC behavior. This is easy to handle, as we can just pass the cmd to a shell without doing any pre-processing (expand variables, modify cmd according to options, etc.)
Also, I'm not aware why the current implementation conflicts with nohup, cronjobs, or _systemd units_ :thinking: Could it be solved with something like https://linux.die.net/man/1/tee (saving the output to a file but at the same time showing it on stdout?)
 ghost
on 20 Aug 2019
ghost
on 20 Aug 2019
I'm not aware of any conflicts with nohup/cron/systemd either, not sure what @AlJohri had in mind.
What does your phrase "tying it to any DVC behavior" mean? I feel like the implementation would probably be to just change a Python call like subprocess.run(cmd) to subprocess.run(cmd, stdout=file) - you wouldn't literally change the cmd string to use shell redirection.
kenahoo
on 20 Aug 2019
When I wrote this issue, I was using Bash 3, the default bash on macos.
On Bash 3, the syntax to run something in the background and redirect the log output looks like: nohup some_command > nohup2.out 2>&1 & which is _very_ easy to mess up to remember or to type.
With Bash 4+ it's now: nohup some_command &> nohup2.out & which is a definitely a bit easier.
These days, I use the following bash functions which make life easier:
background() {
nohup bash --login -c "$*" &
}
background-log() {
filename="$1"
shift
nohup bash --login -c "$*" &> "$filename" &
}
Usage:
background jupyter notebook
- start command in background and leave output to default nohup.out`
background-log "experiment-$(date).log" dvc repro --all-pipelines
- start command in background and log to the given filename
I'd love any improvements from the bash-experts around here but I think this issue can be closed.
AlJohri
on 21 Aug 2019
What does your phrase "tying it to any DVC behavior" mean? I feel like the implementation would probably be to just change a Python call like subprocess.run(cmd) to subprocess.run(cmd, stdout=file) - you wouldn't literally change the cmd string to use shell redirection.
@kenahoo , true that! I was thinking to actually modify the cmd and append something like > file :sweat_smile:
ghost
on 21 Aug 2019
@AlJohri , thanks for sharing the bash functions! Very useful :smiley:
I'm not a bash expert by no means, but your functions look good :+1:
ghost
on 21 Aug 2019
I'd love any improvements from the bash-experts around here
background() {
nohup bash --login -c "$@" &
}
background-log() {
local filename="$1"
shift
nohup bash --login -c "$@" &> "$filename" &
}
- Using
"$@"instead of"$*"makes a difference if you sometimes have to call something like this:
bash background jupyter "first notebook" - Bash variables are global by default. It is a good practice to make them local.
 dashohoxha
on 21 Aug 2019
dashohoxha
on 21 Aug 2019
@dashohoxha FWIW, I just tried that background command with $@ and I got:
usage: jupyter [-h] [--version] [--config-dir] [--data-dir] [--runtime-dir]
[--paths] [--json]
[subcommand]
jupyter: error: one of the arguments --version subcommand --config-dir --data-dir --runtime-dir --paths is required
It works when I change back to $*.
AlJohri
on 21 Aug 2019
@AlJohri Check out this: https://stackoverflow.com/questions/2761723/what-is-the-difference-between-and-in-shell-scripts
dashohoxha
on 21 Aug 2019
@AlJohri @kenahoo So, guys, the consensus is that we don't need it after all or what? :)
Actually, another suprusingly related issue is https://github.com/iterative/dvc/issues/755, in which I am also looking at reproducing the DAG in parallel manner, in which we need to somehow deal with stdout/stderr of the stages. And obvious way to do that is to just auto-generate stage1.dvc.log(or .stdout, .stderr) alongside and dump everything in there. Anothe approach would be to force people to redirect everything themselves during dvc run with --stdout and --stderr as proposed in this issue and only allow parallel execution of those stages, so that we don't run the risk of two stages wanting some user input like confirmation prompts or something.
efiop
on 21 Aug 2019
@efiop I think my use case must be more different from the original issue than I thought. I'll pop it into a different ticket.
kenahoo
on 22 Aug 2019
Created #2425 .
kenahoo
on 22 Aug 2019
I kind of find myself wanting this again. I think I didn't explain it properly last time.
Since each DVC stage is creating and then eventually storing an immutable copy data, I want to store some metadata associated with a particular "run" of a stage. Some pieces of metadata could be how long it took a stage to run, or the stdout/stderr of the stage.
This would help with situations where I print out information to STDOUT but haven't taken the time to really create a proper metadata file that stores this information.
For example, in this screenshot below, I print out the number of rows before and after a stage that filters data. I want to able to go back and reference this information somehow but I don't really want to add yet another output file that stores this metadata for such a simple stage.
To summarize, I think the idea is to basically store the stdout/sterr of each stage as an implicit out and cache it via DVC.
Perhaps with an accompanying command dvc log blah.dvc which prints that log back out to you for a particular stage.
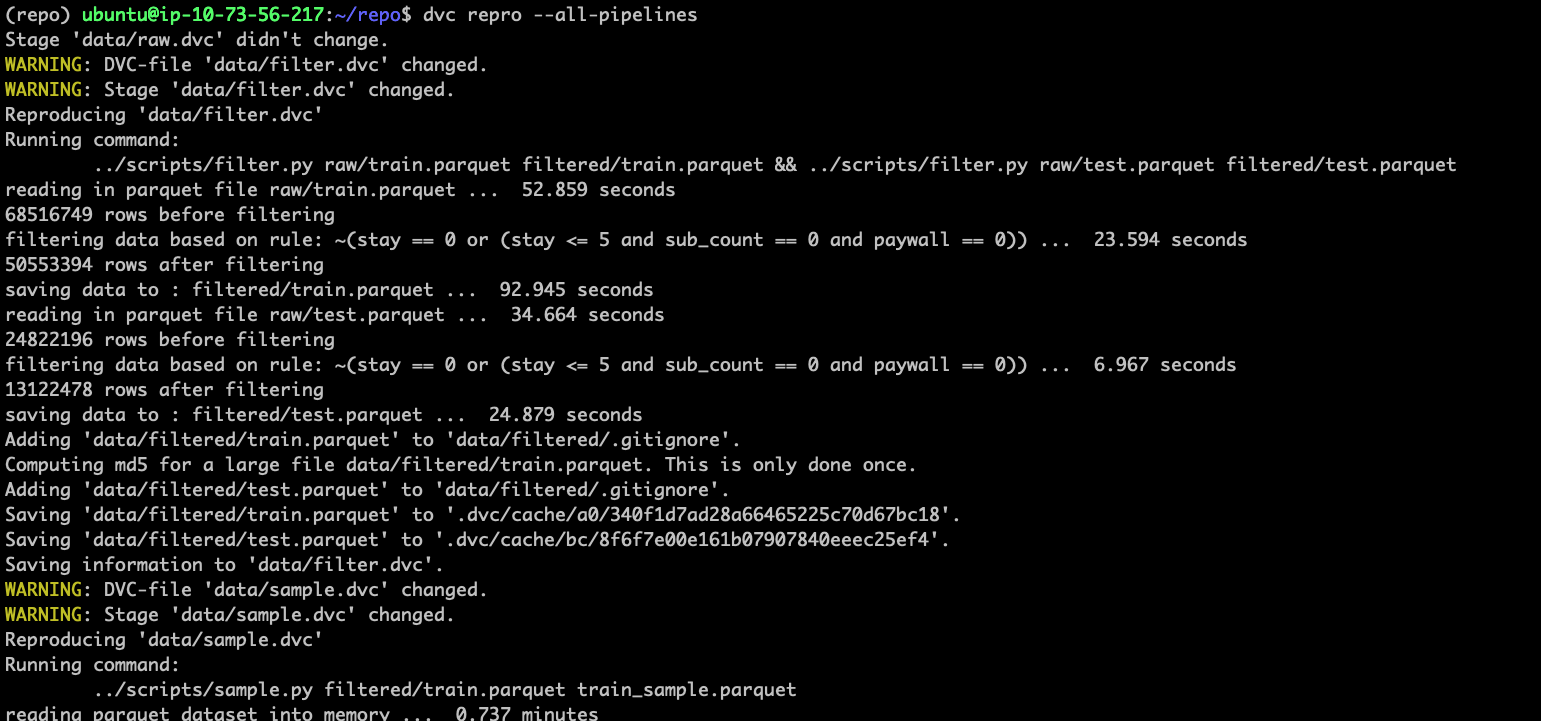
This isn't super well thought out and I might just be getting lazy here- but I've found myself wanting this a few times now.
AlJohri
on 30 Aug 2019
the idea is to basically store the stdout/sterr of each stage as an implicit out and cache it via DVC
If this feature is implemented, I believe that the proper way to track such information is through git (assuming that it is not too large).
Right now you can implement it yourself, if you redirect the stdout/sterr to a log file, and add this log file to git. Something like this:
dvc run -f stage1.dvc -d ... -o ... 'cmd ... &> stage1.log'
git add stage1.log
Perhaps with an accompanying command
dvc log blah.dvcwhich prints that log back out to you for a particular stage.
With the implementation I suggested above this would be less -r stage1.log. But I have not thought it well either, I may be wrong :)
dashohoxha
on 30 Aug 2019
Related issues
 jorgeorpinel
·
3Comments
ghost
·
3Comments
jorgeorpinel
·
3Comments
ghost
·
3Comments
 mfrata
·
3Comments
mfrata
·
3Comments
 siddygups
·
3Comments
siddygups
·
3Comments
 tc-ying
·
3Comments
tc-ying
·
3Comments
Most helpful comment
I think I had the same idea (see Discord context) - add a
--stdout fooflag todvc run, e.g.dvc run -d input.csv --stdout output.csv mycommand.shwhich would basically be equivalent to
dvc run -d input.csv --outs output.csv 'mycommand.sh > output.csv'.Name is negotiable of course.
Was thinking of this as a way to avoid using shell-isms in simple cases, and to avoid repeating the filename.