Dvc: run/repro: add option to not remove outputs before reproduction
All 18 comments
What about corrupting the cache, @efiop ? Is this for reflink only?
 ghost
on 20 Nov 2018
ghost
on 20 Nov 2018
@mroutis Great point! We should dvc unprotect the outputs when this option is specified, so that user has safe copies(or reflinks).
 efiop
on 20 Nov 2018
efiop
on 20 Nov 2018
Adding my +1 here. This would be helpful for doing a warm start during parameter search. Some of our stages are very long running and starting from the previous results would help it complete much faster.
 AlJohri
on 30 Jan 2019
AlJohri
on 30 Jan 2019
@AlJohri WDYT of this (hacky) possible solution?
Add a stage before the training stage, that takes the latest cached checkpoint from the output of the training stage, moves or copies it to a different path, and then that resume checkpoint is a cached dependency of the training stage?
This should allow each git commit to describe an accurate snapshot of a training run - the checkpoint you start from, and the checkpoint that resulted.
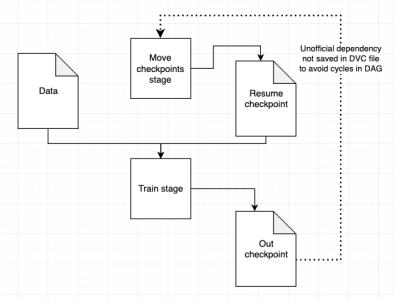
 guysmoilov
on 19 Feb 2019
guysmoilov
on 19 Feb 2019
Probably should look something like:
$ dvc run --outs-no-remove ckpt ...
which would add something like
remove: False
to the dvc file for ckpt output, so that dvc repro knows about it.
efiop
on 20 Mar 2019
Should be closed by #1759
 pared
on 25 Mar 2019
pared
on 25 Mar 2019
@AlJohri there is new option in run for this case, Ill add it to docs soon, but you can find it in closing issue name.
pared
on 25 Mar 2019
What should I do if from time to time I want to start fresh? Use dvc remove on .dvc file or rm the output?
EDIT: dvc remove doesn't remove persistent outputs (though some progress bars appear the first time it is called, but if executed again the command does nothing). Is it expected behaviour?
 piojanu
on 26 Mar 2019
piojanu
on 26 Mar 2019
@piojanu actually what this option is doing is just setting persist flag inside stage file. So if you want to edit behaviour after some time, just change this flag in .dvc file. As to dvc remove, I am looking into that.
pared
on 26 Mar 2019
@piojanu thank you for pointing that out! I created issue for that one. #1784
pared
on 26 Mar 2019
@piojanu It is also worth noting, that this behaviour is only possible, if user actually appends data to output. If, for example, our run command somehow destroys file, persist flag will not be able to prevent that. For example, reproducing given command:
dvc run --outs-persist something "echo something > something"
will always result in overwriting the file, beause that is how > works. However, if we use ">>",
then we can utilize persist functionality.
pared
on 26 Mar 2019
Yea, I understand that :) But maybe it is worth including it in docs. Also, should dvc remove (when fixed) work or it is not recommended path and it can break something?
piojanu
on 26 Mar 2019
@piojanu it should work, even now, since patch entered master, it was my mistake, didn't test whether remove works for persistent outputs.
pared
on 26 Mar 2019
Very good guys! This is a very important feature, I already started using it to great effect instead of my above workaround: https://dagshub.com/Guy/fairseq/src/dvc/dvc-example/train.dvc
I vote for having a short flag for it, I think it will be commonly used for anyone that wants to train with checkpoints, or for scenarios like this: https://discuss.dvc.org/t/version-checking-with-dvc/168/5
Maybe -p -P ?
guysmoilov
on 2 Apr 2019
@guysmoilov Thanks a lot for your input on discuss forum! :slightly_smiling_face:
Mind creating a feature request for it? :slightly_smiling_face:
efiop
on 2 Apr 2019
@AlJohri quick question, but the "warm start" and "reusing previous results" - are you referring to reusing the previous model (trained with a different set of params) to continue training it with a new set? Or is it something different in your case? We would really appreciate your input here! Thanks!
 shcheklein
on 11 Apr 2019
shcheklein
on 11 Apr 2019
hey there, sorry I'm actually not 100% sure what I meant before. it was related to more efficient hyperparameter searching but I can't remember the particular use case. I had a job where the parameter search took a very long time but I don't recall how I thought a warm start might solve that in this scenario
"warm start machine learning" has a lot of hits on google so perhaps you can read more about the more general use case
AlJohri
on 11 Apr 2019
Hello, @guysmoilov , @AlJohri, @pared , @efiop !
I was thinking about the _usefulness_ of having a persist flag and the reason behind it, after reading the whole convo the use case is still not clear for me.
The idea to resume a process from a certain point could be handled by the script itself (writing to a temporary file not specified on the run command as output and then, when the process has finished, move the temporary file to the wanted location).
It would be great if you can come up with an example of how you are using this feature today :smiley:
ghost
on 23 Apr 2019
Related issues
 dnabanita7
·
3Comments
ghost
·
3Comments
ghost
·
3Comments
dnabanita7
·
3Comments
ghost
·
3Comments
ghost
·
3Comments
 TezRomacH
·
3Comments
TezRomacH
·
3Comments
 analystanand
·
3Comments
analystanand
·
3Comments
Most helpful comment
@AlJohri there is new option in run for this case, Ill add it to docs soon, but you can find it in closing issue name.