Distributed: Accelerate Scheduler with Cython, PyPy, or C
We are sometimes bound by the administrative of the distributed scheduler. The scheduler is Pure-Python, and a bundle of core data structures (lists, sets, dicts). It generally has an overhead of a few hundred microseconds per task. When graphs become large (hundreds of thousands) this overhead can become troublesome.
There are a few potential solutions:
- Use Cython in a few places
- Run the entire scheduler in PyPy (workers, clients, and user code can still be in CPython)
- Rewrite everything in C/Go/Julia/whatever
Generally efforts here have to be balanced with the fact that the scheduler will continue to change, and we're likely to continue writing it in Python, so any performance improvement would have the extra constraint that it can't add significant development inertia or friction.
Here are a couple of cProfile-able scripts that stress scheduler performance: https://gist.github.com/mrocklin/eb9ca64813f98946896ec646f0e4a43b
 mrocklin
mrocklin
All 103 comments
Here is another, more real-world benchmark: https://gist.github.com/48b7c4b610db63b2ee816bd387b5a328
Though I plan to try to clean up performance on this one up a bit in pure python first.
mrocklin
on 3 Feb 2017
Any experience running with PyPy? How much is the difference?
I think it's a bit complicated to run the scheduler on pypy and the workers with cpython (if you want numpy or pandas).
According to @GaelVaroquaux 's testimonial on Cython:
You guys rock! In scikit-learn, we have decided early on to do Cython, rather than C or C++. That decision has been a clear win because the code is way more maintainable. We have had to convince new contributors that Cython was better for them, but the readability of the code, and the capacity to support multiple Python versions, was worth it.
With Cython it's easier to achieve c-like performance without leaving the python origins. I had great experience with it too.
 kszucs
on 3 Feb 2017
kszucs
on 3 Feb 2017
My perspective is the following:
The advantage of PyPy is that we would maintain a single codebase. We would also speedup everything for free (including tornado). I'm not normally excited about PyPy. I think that dask's distributed scheduler is an interesting exception. PyPy seems to be fairly common among web projects. The distributed scheduler looks much more like a web project than a data science project.
The advantage of Cython is that users can install and run it normally using their normal tool chain. Also the community that works on Dask has more experience with Cython than with PyPy. The disadvantage is that we will need to maintain two copies of several functions to support non-Cython users, and things will grow out of date. I do not intend to make Cython a hard dependency.
The advantage of C is that it would force us to reconsider our data structures.
mrocklin
on 3 Feb 2017
I'm using PyPy for client, workers and scheduler and it works fine. I also tried to run the scheduler on PyPy and client with CPython, that worked too.
The only problems arised when workers and client didn't both use PyPy or CPython, because the serialization/deserialization wasn't compatible (which makes sense).
I think that accelerating the scheduler in this way is a good idea, just wanted to state that at least with PyPy you can try it now right away, without any changes to distributed itself :-)
 Kobzol
on 3 Feb 2017
Kobzol
on 3 Feb 2017
cc: @marshyski this might of interest to you from Go perspective.
 hussainsultan
on 3 Feb 2017
hussainsultan
on 3 Feb 2017
@mrocklin
The disadvantage is that we will need to maintain two copies of several functions to support non-Cython users
Did You mean non-CPython users? It doesn't seem impossible to keep compatible with pypy without code duplication.
I guess Numba is out-of-scope - the scheduler depends and possibly will depend on hashtable structures, right?
kszucs
on 4 Feb 2017
No, I mean non-Cython users. I don't intend to make Dask depend on Cython near term.
mrocklin
on 4 Feb 2017
Numba is unlikely to accelerate the scheduler code.
mrocklin
on 4 Feb 2017
The disadvantage is that we will need to maintain two copies of several
functions to support non-Cython users, and things will grow out of
date.
You should explore using Cython's pure Python mode:
http://cython.readthedocs.io/en/latest/src/tutorial/pure.html
Maybe it will be enough for what you need.
Also, I think that if you need to have two implementations of functions,
a good practice is to test them together. It will help avoiding a decay.
I do not intend to make Cython a hard dependency.
The problem would not be Cython as a dependency, as it needs only to be a
build dependency, or even better, you can generate the C files and ship
them when you do releases (this is what we do in scikit-learn). The
problem is that you are adding compiled code to your project. It makes it
more likely that things go run on installation. You need to start
distributing binaries, and hence start compiling for the different
platforms and the different versions of Python. Systems that have non
uniform platforms (think a multi-machine environment) suffer.
I have always considered that adding compiled code to a project was a big
step, and I try to limit it. Note that limiting it is not always avoiding
it: I am very very happy that we decided for compiled code in
scikit-learn. It does increase the adoption cost for dask to add such a
requirement.
 GaelVaroquaux
on 4 Feb 2017
GaelVaroquaux
on 4 Feb 2017
cc @anton-malakhov
mrocklin
on 8 Feb 2017
Quick timing update showing PyPy vs CPython for creating typical dask graphs. We find that PyPy is in the expected 2-5x faster range we've seen with Cython in the past:
PyPy
>>>> import time
>>>> start = time.time(); d = {('x', i): (apply, lambda x: x + 1, [1, 2, 3, i],\
{}) for i in range(100000)}; end = time.time(); print(end - start)
0.11324095726
CPython
In [1]: import time
In [2]: start = time.time(); d = {('x', i): (apply, lambda x: x + 1, [1, 2, 3, i], {}) for i in range(100000)}; end = time.time(); print(end - start)
0.357743024826
Given what happens to turn up as a bottleneck. I can imagine wanting to cythonize core parts of dask.array as well (like top).
mrocklin
on 12 Feb 2017
Quick timing update showing PyPy vs CPython for creating typical dask graphs.
We find that PyPy is in the expected 2-5x faster range we've seen with Cython
in the past:
Usually that's because there are some type information that should be
added to make Cython faster.
GaelVaroquaux
on 12 Feb 2017
Usually that's because there are some type information that should be added to make Cython faster.
I'm aware. To be clear, my previous comment was comparing PyPy to CPython, not Cython. We observe similar speedups that we've seen when accelerating data-structure-dominated Python code with Cython in the past, notably 2-5x. In my experience 100x speedups only occur in Cython when accelerating numeric code, where Python's dynamic dispatch is a larger fraction of the cost.
mrocklin
on 12 Feb 2017
OK, I had misunderstood your comment.
GaelVaroquaux
on 12 Feb 2017
I'm not sure what you mean by "making Dask depend on Cython". Cython would only be a build-time dependency --- you'd ship either the generated C files via PyPi, Conda, etc, or the user would require a C compiler. It's similar to writing a C extension, just in a better language.
 honnibal
on 24 May 2017
honnibal
on 24 May 2017
@honnibal of course you're correct. I should have said something like "making the dask development process depend on Cython and the dask source installation process depend on a C compiler" both of which add a non-trivial cost.
mrocklin
on 25 May 2017
@mrocklin
Couldn't you integrate the cython building into travis before shipping to PyPI, and have a dask and dask-c version in PyPI? That seems like it has all the advantages and none of the costs.
Also, you're completely right that Cython won't be faster (or only a tiny bit than PyPy for your scheduler), but my argument against relying on it is that PyPy isn't production ready for and/or doesn't support a lot of important things, including a lot of the data science ecosystem that people would use Dask with. Cython already has complete compatibility with everything and is used in massive deployments by Google etc.
I also have a related question to all this, which is the reason I stumbled across this thread in the first place:
I'm trying to have dask compute a giant custom DAG of small numeric operators (something cython will give the 100x improvements in). How could I best implement this with dask?
 justinkterry
on 1 Nov 2017
justinkterry
on 1 Nov 2017
Couldn't you integrate the cython building into travis before shipping to PyPI, and have a dask and dask-c version in PyPI?
Yes.
That seems like it has all the advantages and none of the costs.
This adds a significant cost in development and build maintenance.
Also, you're completely right that Cython won't be faster (or only a tiny bit than PyPy for your scheduler), but my argument against relying on it is that PyPy isn't production ready for and/or doesn't support a lot of important things, including a lot of the data science ecosystem that people would use Dask with. Cython already has complete compatibility with everything and is used in massive deployments by Google etc.
It is very hard (and often incorrect) to make claims about one being faster or slower than the other generally. Things are more complex than that.
I also have a related question to all this, which is the reason I stumbled across this thread in the first place: I'm trying to have dask compute a giant custom DAG of small numeric operators (something cython will give the 100x improvements in). How could I best implement this with dask?
I'm going to claim that this is unrelated. Please open a separate issue if you have a bug or ask a question on stack overflow (preferably with a minimal example) if you have a usage question.
mrocklin
on 1 Nov 2017
@justinkterry You won't really see a speed benefit from Cython unless you plan out your data structures in C. That's not nearly as hard as people suggest, and I think it actually makes code better, not worse. But it does mean maintaining a separate dask-c fork is really costly.
As far as the Travis build process goes: Yeah, that does work. But the effort of automating the artifact release is really a lot. You have to use both Travis and Appveyor, and Travis's OSX stuff is not very nice, because the problem is hard. I'm also not sure Travis will stay so free for so long. I suspect they're losing a tonne of money.
In general the effort of shipping a Python C extension is really quite a lot. Sometimes I feel like it's harder to build, package and ship my NLP and ML libraries than it is to write them.
If it included C extensions, a library like Dask would have a build matrix with the following dimensions:
- OS: Windows, Linux, OSX. There's now also tonnes of less standard Linuxes, because of Docker
- Compiler: GCC, CLang, MinGW, MSVC (various), ICC
- Python version: 2.7, 3.5, 3.6, 3.7
- Installation: pip, conda, pip system installation, pip local directory
- Artifact type: sdist, wheel, build repository
- Architecture: 32 bit, 64 bit
That's over 1,000 combinations, so you can't test the matrix exhaustively. Building and shipping wheels for all combinations is also really difficult, so a lot of users will have to source install. This means that a lot of things that shouldn't matter do. For instance, the peak memory usage might spike during compilation for some compilers, bringing down small nodes (obviously an important use-case for Dask!). This might happen on some platforms, but not others --- and the breakage might be introduced in a point release when Dask upgraded the version of Cython used to generate the code.
Is it worth it? Well, for me the choice is between writing extension and going off and doing something completely different. My libraries couldn't exist in pure Python. But for a very marginal benefit, I think you'd rather be shipping a pure Python library.
Btw, I also think PyPy might not be that helpful? The workers would have to be running CPython, right? Most tasks you want to schedule with Dask will run poorly on PyPy.
honnibal
on 1 Nov 2017
@honnibal Thank you very much for your detailed explanation; that actually helps a lot. What would you recommend doing if I want to call a bunch of functions in dask that would be highly accelerated by C? Just package each one with cython and call it from the script using dask? My only concern with doing that is the time it takes to go between python and C, because it's a very large number of very short functions.
justinkterry
on 1 Nov 2017
What would you recommend doing if I want to call a bunch of functions in dask that would be highly accelerated by C?
@justinkterry I recommend raising a question on Stack Overflow using the #dask tag.
mrocklin
on 1 Nov 2017
Hi Everyone.
So me & Matt did some benchmarks, looked at pypy and here are the takeaways:
- PyPy gives about 40% speedup for free
- The remaining time is spent, predominantly:
- 15% doing bytearray += stuff, which relies on refcounting to be fast.
- 10% looking up stuff in dictionaries. The real figure is probably higher as it would show up in the GC. Using objects here instead of small dicts with known keys would speed things up considerably
- 25% of time in the GC - likely mostly the stuff above, but also there is quite a bit of list copies and resizing
I think we can get another 2x speedup from PyPy with moderate effort. I can't promise I'll find time immediately, but if someone pesters me at some stage in the near to mid future, I can have a look.
Cheers,
fijal
 fijal
on 11 Nov 2017
fijal
on 11 Nov 2017
This provides some motivation to arrange per-task information into objects. It is currently spread across ~20 or so dictionaries. This would have the extra advantage of maybe being clearer to new developers (although this is subjective). We would also have to see what affect this would have on CPython performance.
A rewrite of this size is feasible, but is also something that we would want to discuss heavily before performing. Presumably there are a number of other improvements that we might want to implement at the same time.
I can't promise I'll find time immediately, but if someone pesters me at some stage in the near to mid future, I can have a look.
My guess is that your time would be better spent by providing us with advice on how best to use PyPy during this process. My guess is that it would be unpleasant for anyone not already familiar with Dask's task scheduler to actually perform this rewrite.
mrocklin
on 11 Nov 2017
@mrocklin as a general note, if you're thinking about moving things from dicts to objects, then the attrs library is really excellent
 njsmith
on 12 Nov 2017
njsmith
on 12 Nov 2017
So on the plus side, I added some small PyPy improvements to be not as bad when handling bytearray (and it has nothing to do with the handling of refcounts). Where are the bytearrays constructed? It might be better (for Cpython too) to create a list and use b"".join instead of having a gigantic bytearrays.
As for how to get some basics. I do the following:
run the program with
PYPYLOG=jit-summary:- pypyprogram. That creates a short summary. What to look for:- number of aborts. If there are a lot of aborts, we need to look where.
PYPYLOG=jit:logwould create a massive log, where ABORT strings can be found. ABORT because trace is too long is normal - don't worry. ABORT because quasi immutable is forced is bad. I looked through the traceback and found is from calling a function. Then matt told me that function comes from cloudpickle, so presumably cloudpickle modifies some function parameters that are supposed to not be modified much - tracing time and backend time. This gives you some indication of warmup - if tracing + backend is a significant part of total time, either run for longer or pypy is struggling to warm up
- number of aborts. If there are a lot of aborts, we need to look where.
I run
PYPYLOG=log pypy programand then runPYTHONPATH=~/pypy python ~/pypy/rpython/tool/logparser.py print-summary -which gives me some basics: 8% of the time in GC (acceptable), 1% JIT tracing (good), the rest executionpython -m vmprof --web would upload the vmprof run.
At this stage, I think what we need to do is to take the core functions and make smaller benchmarks, otherwise it's a touch hard to do anything.
My hunch is that a lot of dicts and forest-like code of a few functions makes it hard for the JIT to make sense of it and as such too slow, but it's just a hunch for now
fijal
on 13 Nov 2017
I'm not sure we want to go too deep into PyPy-specific tuning. The idea of converting the forest-of-dicts approach to a per-task object scheme sounds reasonable on the principle, though I'm not sure how much it would speed things up. We also don't want to risk making CPython slower by accident, as it is our primary platform (and our users' as well).
 pitrou
on 13 Nov 2017
pitrou
on 13 Nov 2017
Right, I'm pretty sure pypy-specific tuning is a terrible idea. It's also rather unlikely to make a measurable difference on CPython. Measuring on PyPy though DOES make sense (especially that it runs almost 2x faster in the first place). Do you have benchmarks running on CPython all the time? Because if not, then "making it slower by accident" is a completely moot point.
fijal
on 13 Nov 2017
We do have a benchmarks suite (and some of us have individual benchmarks they run on a casual basis), but unfortunately we haven't automated its running (yet?).
pitrou
on 13 Nov 2017
Where are the bytearrays constructed? It might be better (for Cpython too) to create a list and use b"".join instead of having a gigantic bytearrays.
If I'm guessing correctly, it is in Tornado and should be fixed by https://github.com/tornadoweb/tornado/pull/2169
pitrou
on 13 Nov 2017
replacing OrderedDict with dict helps a bit on PyPy. I presume we can do that on PyPy always and CPython >= 3.6? Should help there too
fijal
on 13 Nov 2017
but unfortunately we haven't automated its running (yet?).
@pitrou it's running nightly and the results are posted to http://pandas.pydata.org/speed/distributed/. Though I haven't looked at how we'll that covers the paths that would be changed here.
 TomAugspurger
on 13 Nov 2017
TomAugspurger
on 13 Nov 2017
@TomAugspurger thanks for correcting me. Looks like I have some catching up to do :-)
pitrou
on 13 Nov 2017
One rewrite I would recommend (and I think would make everything both faster and more readable) would be to change the notion that now "key", as presented in say transition_released_waiting, is a key in one million dictionaries - and instead would put all those things as properties of an object. So say instead of self.waiting[key] would be key.waiting etc.
fijal
on 13 Nov 2017
And by the way, the benchmark of interest for this issue in http://pandas.pydata.org/speed/distributed/ should be time_trivial_tasks.
pitrou
on 13 Nov 2017
Here is some benchmark:
https://paste.pound-python.org/show/xaRmpbzZjJEGC9aIKv7W/
Now, the dict version is both the worst of PyPy and the best for CPython, so the speedup is more minimal. With objects, PyPy is another 40% faster. With a bit of effort, it would mean that we can make about 3x speedup on PyPy compared to best CPython version.
Now I don't know what to recommend - the dicts seem to be the fastest way to do those things on CPython (but your exact mileage might vary, depending on the sizes etc.), but on the other hand hampers the speedup when it's needed. On the other hand, no amount of C or Cython would help to speed those things either without changing the data structures. There is just all those dict lookups that need to be done and not much that can be done about it.
I would be happy to help with some recommendations, if there are concrete questions
fijal
on 13 Nov 2017
Can you post the timings you got on both PyPy and CPython?
(I'm assuming this is CPython 3.6, because we will care less about performance on 2.7, I think. Similarly, it would be nice if performance was measured on PyPy3)
pitrou
on 13 Nov 2017
correspondingly, one two and three (so namedtuple, dicts, objects)
3.6:
11.2s 3.6s 10.2s
2.7:
5.02s, 1.4s, 3.7s
PyPy:
0.32s, 0.50s, 0.32s
PyPy3:
0.36s, 0.45s, 0.30s
fijal
on 13 Nov 2017
Hmm, the timings are so small (a couple microseconds) that I wonder whether it's the loop that's really timed or the initialization overhead. The 3x slowdown from 2.7 to 3.6 is quite difficult to explain otherwise.
pitrou
on 13 Nov 2017
If I make the loop 10x bigger (put more objects there), it does not change the timing much. Calling an empty function enough times takes a fraction below the resolution of the above numbers, so it seems incredibly unlikely that the loop has anything to do with it.
fijal
on 13 Nov 2017
I'm not talking about the function call itself, but the initialization steps before the loop (creating the dicts, objects or namedtuples).
pitrou
on 13 Nov 2017
The times seem to be more or less proportional. Order is as follows:
empty, one, two, three, one_init, two_init, three_init
2.7:
(0.0073049068450927734, 3.4107110500335693, 1.0346159934997559, 2.9385740756988525, 1.6497900485992432, 0.5617139339447021, 1.8330729007720947)
3.6:
0.017946243286132812 10.70589828491211 3.830824375152588 10.620617151260376 4.614173173904419 1.8180482387542725 4.539532423019409
so init takes ~50% of the time, but consistently so.
fijal
on 13 Nov 2017
fijal, does adding __ slots __ help with objects under CPython.
 camarajm
on 13 Nov 2017
camarajm
on 13 Nov 2017
about 5-10%
fijal
on 13 Nov 2017
After experimenting a bit more with it, I don't think this benchmark is credible :-/
pitrou
on 13 Nov 2017
Credible as in fairly represents dask workload (I don't think it is) or credible as in shows tradeoffs of dicts vs objects? Also, "this" being the small one I wrote? I'm happy to try some other stuff
fijal
on 13 Nov 2017
Credible as in fairly represents dask workload (I don't think it is) or credible as in shows tradeoffs of dicts vs objects? Also, "this" being the small one I wrote?
1) Both :-)
2) Yes
pitrou
on 13 Nov 2017
Please come with something better. I'm happy to run it and tune it.
fijal
on 13 Nov 2017
Here is a take on your original benchmark: https://gist.github.com/pitrou/88306fbca13d6273aa642090fe687d22
Here I get on Python 3.6:
obj 1.2467336654663086
dict 1.1992299556732178
slots-obj 1.0798592567443848
cython-obj 1.1572723388671875
and on PyPy 5.1.2:
obj 0.14532494545
dict 0.188431978226
slots-obj 0.0962200164795
Cool, so we can switch to objects :-) Note that __slots__ on PyPy do nothing - the first one is likely longer due to JIT warmup or something and not the actual time.
fijal
on 13 Nov 2017
cc @scoder (Cython) in case he finds this sort of optimization case interesting
mrocklin
on 13 Nov 2017
In fact, I do. Thanks for bringing me in.
I was going to say that Python classes can be overridden into extension types when Cython compiles them, but Antoine has apparently already tested that. What he did not try, AFAICT, is to also compile the code that uses these objects then. If Cython knows the C type of an object, it can access its attributes as C struct members, which is as fast as it gets. You can use decorators for that:
http://docs.cython.org/en/latest/src/tutorial/pure.html#extension-types-and-cdef-functions
although I'd lean towards recommending an augmenting .pxd file here:
http://docs.cython.org/en/latest/src/tutorial/pure.html#augmenting-pxd
as it avoids any source code dependency on Cython's cython.py module.
I agree with Fijal that switching from dicts to objects seems like a very good idea. If you cythonize the result and use cdef classes, it should speed things up also in CPython.
 scoder
on 13 Nov 2017
scoder
on 13 Nov 2017
BTW, just to mention it, can't say if it's an option for you, but I noticed that @mrocklin's original benchmarks used the @coroutine decorator + yield. Tornado 4.3+ has support for async+await, as implemented by Cython. Meaning, you could switch to writing your code with async+await, and then compile it in Cython to target Py2.x and older Py3 versions that do not understand the syntax. It's probably slower in Py2.x, though, as the protocol lacks a C layer there.
scoder
on 13 Nov 2017
@pitrou is refactoring the scheduler here to be more amenable to future speedups: https://github.com/dask/distributed/pull/1594
mrocklin
on 1 Dec 2017
Linking for reference (as I was searching for this earlier), previous Cython exploration was done in PR ( https://github.com/dask/distributed/pull/1623 ).
 jakirkham
on 17 Apr 2020
jakirkham
on 17 Apr 2020
Also to tie things together a bit, there is a more recent effort implementing the scheduler in Rust ( https://github.com/dask/distributed/issues/3139 ).
jakirkham
on 17 Apr 2020
I'm curious if anyone has tried to use PyPy with Dask + Distributed of late. Am interested to know what that experience is like and how it compares to using CPython? Are there any noted performance improvements? Any issues to be aware of?
cc @mariusvniekerk (who I believe was looking into using PyPy with Distributed at one point in time)
jakirkham
on 29 Apr 2020
I sat down with the PyPy devs at one point to work on this. With fairly
artificial benchmarks and some effort we were able to get up to about a 2x
speedup. This matches the experience when Antoine tried using Cython, we
got up to about 1.5x maybe?
This lead me to believe that the next thing to do here is to rigorously
profile things to that we get a better understanding of what is slow. I
think that that is the next step here, rather than trying out a new
technology and hoping that it will have some impact.
On Wed, Apr 29, 2020 at 11:53 AM jakirkham notifications@github.com wrote:
I'm curious if anyone has tried to use PyPy with Dask + Distributed of
late. Am interested to know what that experience is like and how it
compares to using CPython? Are there any noted performance improvements?
Any issues to be aware of?cc @mariusvniekerk https://github.com/mariusvniekerk (who I believe was
looking into using PyPy with Distributed at one point in time)—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/dask/distributed/issues/854#issuecomment-621397728,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AACKZTC7OPKPAY42KUAORYLRPBZSDANCNFSM4C6ZYWMA
.
mrocklin
on 29 Apr 2020
Sure. Though if I understand correctly this was a few years ago. Am curious if things have changed since then (given various improvements to the entire stack).
jakirkham
on 29 Apr 2020
Most of my pypy dask stuff was toying around with streamz. For microbenchmarks doing things like echoservers/summing lists of python ints, I got about a 2-4x speedup
 mariusvniekerk
on 29 Apr 2020
mariusvniekerk
on 29 Apr 2020
One intuition I got when profiling and trying to speed up the scheduler with Cython, is that the scheduler algorithms are hash table-intensive. Much of the scheduling is based on many operations on sets or dicts.
One possible experiment would be to refer to tasks and other objects by sequential integer ids. Then you could store them in Numpy arrays, and perhaps even vectorize some of the operations. Or at least, it could give Cython or PyPy more room to optimize integer-indexed accesses.
(this probably requires some pooling, since all those objects have diverse and unpredictable lifetimes)
pitrou
on 1 May 2020
In PyPy this can be done with either a special dict or using object dict.
On Fri, May 1, 2020 at 1:02 PM Antoine Pitrou notifications@github.com
wrote:
One intuition I got when profiling and trying to speed up the scheduler
with Cython, is that the scheduler algorithms are hash table-intensive.
Much of the scheduling is based on many operations on sets or dicts.One possible experiment would be to refer to tasks and other objects by
sequential integer ids. Then you could something like Numpy arrays to store
them, and could perhaps vectorize some of the operations done on them. Or
at least, it could give Cython or PyPy more room to optimize
integer-indexed accesses.(this probably requires some pooling, since all those objects have diverse
and unpredictable lifetimes)—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/dask/distributed/issues/854#issuecomment-622345526,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AAAU7OCQH7SFG7HSI4SAHEDRPKT6HANCNFSM4C6ZYWMA
.
fijal
on 1 May 2020
@fijal You mean a int-keyed dict will automatically use faster lookup mechanisms?
pitrou
on 1 May 2020
int-keyed would, btu also object.__dict__ would automatically have
better performance for a small list of known keys (uses maps). Can be
also created using special invocations
On Fri, May 1, 2020 at 1:13 PM Antoine Pitrou notifications@github.com wrote:
>
@fijal You mean a int-keyed dict will automatically use faster lookup mechanisms?
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub, or unsubscribe.
fijal
on 1 May 2020
In this case this is not object.__dict__, but a bunch of hash tables with (a non-trivial number of) varying keys over time.
pitrou
on 1 May 2020
One intuition I got when profiling and trying to speed up the scheduler with Cython, is that the scheduler algorithms are hash table-intensive. Much of the scheduling is based on many operations on sets or dicts.
I would not be surprised if this was true. I would also like to verify that this is the problem before diving in here. Do you have thoughts on the right way to verify this? When I use Python profiling tools operations like dict.__getitem__ don't come up (understandably). I would love to see a profile of the scheduler, perhaps with some other technology than cProfile, that profiled also the cost of the CPython internals. Any recommendations here would be welcome.
If we knew that this was the problem then it would make a lot of sense to devote mental energy to thinking about how to re-arrange the scheduler. Without this information though it seems like a risky time investment.
mrocklin
on 1 May 2020
You could try Linux perf to get a C-level profile. perf record and perf report are the commands you want to try (this will profile a command from start to end). There are various options to control the sampling frequency, how the call stack is reconstructed, etc.
Once you have such a profile, you can look for function names containing PyDict, dict, PySet or set.
pitrou
on 1 May 2020
cc @quasiben @pentschev ? ^^
mrocklin
on 1 May 2020
Note these operations might not be dominant on CPython, but they may become dominant on Cython or PyPy once the overhead of regular Python execution is shaved off.
pitrou
on 1 May 2020
Given that we saw only a rougly 2x speedup with PyPy or Cython I would expect them to remain visible even in normal Python. If we see something like this at 20% then that would be an interesting signal I think.
mrocklin
on 1 May 2020
I have some simple profiling infrastructure set up (using perf and flamegraph) for the benchmarks from my Rust scheduler experiments. I'll try to run some of the benchmarks and post some numbers, although I can't promise that anything useful will come out of it.
Kobzol
on 1 May 2020
That would be great. Thank you @Kobzol !
mrocklin
on 1 May 2020
You might try https://github.com/benfred/py-spy
It's a low-overhead sampling profiler (which is what you want), and it has
at least some support for capturing both python and C functions
simultaneously.
On Fri, May 1, 2020, 07:28 Matthew Rocklin notifications@github.com wrote:
That would be great. Thank you @Kobzol https://github.com/Kobzol !
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
https://github.com/dask/distributed/issues/854#issuecomment-622410356,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AAEU42A6VQWTGVQUX4ZOWBDRPLMBPANCNFSM4C6ZYWMA
.
njsmith
on 1 May 2020
cc @shwina who just recently started looking at the Cython idea.
cc @kkraus14 for visibility.
 pentschev
on 1 May 2020
pentschev
on 1 May 2020
cc @galipremsagar for visibility too
 beckernick
on 1 May 2020
beckernick
on 1 May 2020
@fijal You mean a int-keyed dict will automatically use faster lookup mechanisms?
If this can be useful, a while ago, I coded a typed dict in Cython for
fast iteration:
https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/utils/_fast_dict.pyx
What made the above very easy to code was that I simply reused the map
construct of C++, which is based on good data structures (red-black
trees, I believe).
GaelVaroquaux
on 1 May 2020
AFAIR, it's less about iterating than random lookups and set operations. Iteration would probably be very fast on Cython and PyPy as well.
pitrou
on 1 May 2020
When I've profiled C-level function calls in Python/Cython code before, have found Callgrind to be useful.
Also when I suspect a lot of low-level calls are taking time, have preferred using DAGs to inspect time spent in the call graph (over things like flame graphs) as they can highlight many different codepaths that spend significant time in one low-level function.
Typically I go for something like gprof2dot to churn through the Callgrind output and generate a graph showing time spent per function.
To make this more effective we might considering passing key modules through Cython (no need to rewrite them in Cython though). This will gives us C symbols that Callgrind will be able to grab. Alternatively it looks like @jcrist has provided an option to annotate functions for Callgrind in Python.
jakirkham
on 1 May 2020
I spent some time exploring Cythonization as a way to reduce scheduler/client overheads.
Here's the benchmark I used:
from dask.datasets import timeseries
from dask.dataframe.shuffle import shuffle
from distributed import Client
if __name__ == "__main__":
client = Client()
ddf_h = timeseries(start='2000-01-01', end='2005-01-01', partition_freq='1d')
result = shuffle(ddf_h, "id", shuffle="tasks")
ddf = client.persist(result)
Here's a timeline* of execution on the client (top) and scheduler (bottom) threads, showing that a significant amount of overhead comes from the following 4 functions:
Client._graph_to_futuresClient.collections_to_dskScheduler.update_graphScheduler.transition
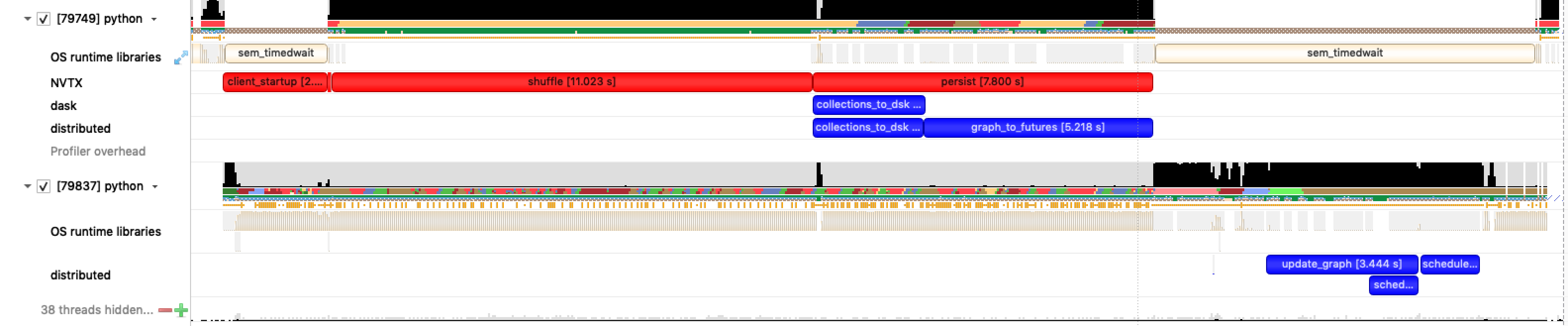
*the above figure was generated using NVTX -- Python bindings for which I'm working on :)
Based on the above, I Cythonized a few things within Dask/Distributed to see if I could bring down the overhead from these functions. The results are not ground-breaking, but not too bad for about an hour's work:
client, before and after Cythonization:


scheduler, before and after Cythonization:


See below for the changes I made:
https://github.com/dask/dask/pull/6178
https://github.com/dask/distributed/pull/3770
 shwina
on 5 May 2020
shwina
on 5 May 2020
@mrocklin I ran a few of my benchmarks and profiled the Dask scheduler with py-spy, using 7 compute nodes (168 Dask workers in total). It's not the most detailed way of profiling, but it gives a quick overall picture, similar to the built-in Dask profiling graphs. Some interesting things that I found by a quick glance:
1) In all benchmarks, 7-15% of time is spent in dask.sizeof. Seems like a lot. Here are some flamegraphs:
result.zip
2) decide_worker also takes about 5-15%, which seems reasonable. Rest of the time seems to be in the various task transitions (mainly task_finished if there are a lot of tasks, which is similar to rsds, it also spends significant time in something akin to task_finished).
3) There seems to be a slight performance regression between our tested version (2.8.1) and the latest released version (2.15.2) for the merge and merge_slow benchmarks. (dask-master is 2.15.2, dask-ws is 2.8.1 with our protocol modifications)
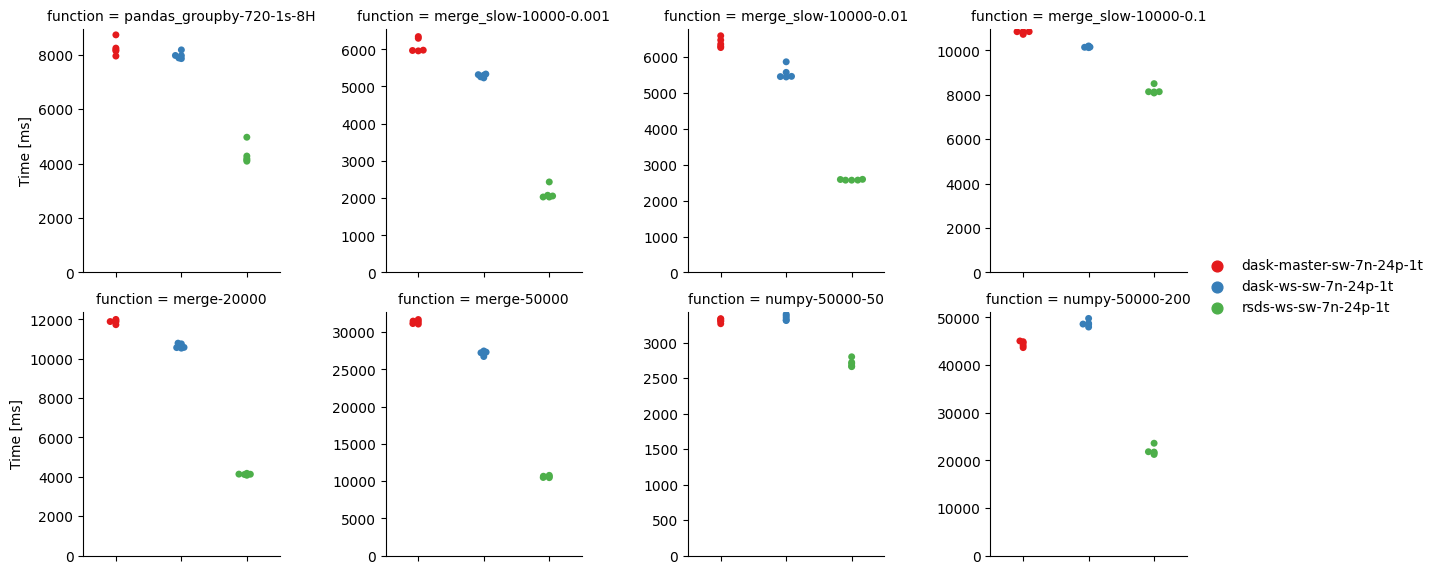
But it might be caused by various things, I didn't investigate further.
On the topic of this issue: I think that before a more serious effort to accelerate/optimize Dask starts, the first step should be to prepare some benchmark suite (with both microbenchmarks and larger "real-world" pipelines) which could be used to evaluate the performance of Dask. Having a standardized benchmark suite directly in the Dask repository which could be run easily and checked for regressions would be very useful for us when we were starting with the Rust scheduler. But mainly it would provide a way to evaluate how the performance of Dask changes over time to spot potential regressions, which are incredibly easy to make (twice so in Python).
Taken further, it could be run in CI (something akin to https://speed.pypy.org/timeline/). It's not so easy to set up and it might be a problem to run multi-node benchmarks in CI, but even without CI support I think that this benchmark suite would benefit Dask in general. It's great if we make a small change that speeds up the scheduler, but if it regresses two versions down the line because of a change in some different part of Dask, it's a bit wasteful (this is a hypothetical example of course). I suppose that you already have quite a few benchmarks stashed away somewhere, but I didn't find them in the repository and I don't know if they are run regularly.
Kobzol
on 5 May 2020
I suppose that you already have quite a few benchmarks stashed away somewhere, but I didn't find them in the repository and I don't know if they are run regularly.
@Kobzol Those are at https://github.com/dask/dask-benchmarks and are uploaded to https://pandas.pydata.org/speed/distributed/ and https://pandas.pydata.org/speed/dask/.
TomAugspurger
on 5 May 2020
Thanks, I somehow managed to miss these. They seem like microbenchmarks, which are undeniably useful, however I think that a suite of end-to-end pipelines should be included too, if possible.
Kobzol
on 5 May 2020
however I think that a suite of end-to-end pipelines should be included
too, if possible
+1
On Tue, May 5, 2020 at 4:20 AM Jakub Beránek notifications@github.com
wrote:
Thanks, I somehow managed to miss these. They seem like microbenchmarks,
which are undeniably useful, however I think that a suite of end-to-end
pipelines should be included too, if possible.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/dask/distributed/issues/854#issuecomment-623996112,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AACKZTCP2NHYU7ZY5KR7R5TRP7Y7VANCNFSM4C6ZYWMA
.
mrocklin
on 5 May 2020
In all benchmarks, 7-15% of time is spent in dask.sizeof. Seems like a lot. Here are some flamegraphs:
cc @fjetter nothing to do here, but I wanted you to be aware.
It looks like this is happening whenever the scheduler writes a message. We check if the message is large enough that we should serialize it in a separate thread. In the case of the scheduler all messages should already be pre-serialized, so this check should probably be skipped. This could be solved by passing through some offload= keyword or something similar. Although doing this in a way that respected Comms that didn't offload (like inproc) might require some care.
For the other components I'm still curious what within those functions is slow. Is it data structure access? Manipulating Task objects? It's hard to dive more deeply to figure out what about CPython itself is slow in particular.
mrocklin
on 5 May 2020
I wanted to check in here and bump this a bit. Two comments.
It seems like a task that we can do right now is come up with a benchmark suite that stresses the client/scheduler in a variety of ways. I'll list a few here
- roundtrip time for a single task
- bandwidth of many embarrassingly parallel tasks
- fully sequential workloads
- random graphs that are both sparsely and densely connected
- dataframe shuffle
- array rechunking with
x.rechunk((1, 1000)).rechunk((1000, 1))
Last time we spoke it sounded like this was something that the folks at NVIDIA felt comfortable contributing.
The results by @shwina with Cythonization are very cool. I would be curious to know some of the following:
- Are the speedups similar if we're not running cProfile, but just timing the results (sometimes cprofile can make Pure Python code a bit slower than it would otherwise be
- Are there things that we can do in the scheduler/client to make Cythonizing more effective? If so, what?
- What would our build process look like with a bit of Cython code?
mrocklin
on 26 May 2020
@Kobzol did you ever end up profiling things with perf or did you only use py-spy in the end ? No worries if you didn't do a perf run
 quasiben
on 8 Sep 2020
quasiben
on 8 Sep 2020
I didn't use perf on Dask itself, just py-spy.
Kobzol
on 8 Sep 2020
I have some questions about Cython.
In @shwina 's work here he Cythonized the TaskState and other classes in the Scheduler
This yielded only modest speedup.
I'm curious if it is possible to take this further, and modify the types in the class itself away from object type into something more compound, like the following:
dependencies: Dict[str, TaskState]
More specifically, some technical questions:
Does Cython have the necessary infrastructure to understand compound types like this? Do we instead need to declare types on the various methods like Scheduler.transition_*?
It looks like the previous effort didn't attempt to Cythonize the Scheduler.transition_* methods. This might be a good place to start with future efforts?
cc @jakirkham who I think might be able to answer the Cython questions above and has, if I recall correctly, recent experience doing this with UCX-Py. Also cc @quasiben who has been doing profiling here recently.
mrocklin
on 26 Oct 2020
You can use the dict type, but there is not currently dedicated support for containers with typed values like Dict[str, TaskState]. One of the issues is tracking usages of the "typing" module, another is integrating container item types into the type system. Both probably aren't difficult to implement (there is precedence for both, e.g. C++ template support), but it hasn't been implemented yet.
Usually, people type the variables that they assign the results to. Or use type casts. But that introduces either a requirement for Cython syntax or some runtime overhead in pure Python (due to a function call to cython.cast()).
Without looking at how the transition_*() methods are used, I can say that reducing call overhead is a very worthwhile goal for function/class heavy code. Nothing you can do in Python comes close to a C call.
scoder
on 26 Oct 2020
Given the dict is used with a pre-defined set of keys, I think we could define a big if, elif, elif, elif, etc. block which I believe Cython will optimize into a switch case for us. Would look a bit gross code-wise and be a bit unintuitive from a Python perspective.
 kkraus14
on 26 Oct 2020
kkraus14
on 26 Oct 2020
which I believe Cython will optimize into a switch case for us
switch doesn't work with string values. And a Python dict lookup with a str (especially a literal) is actually plenty fast. I doubt that this is a bottleneck here.
scoder
on 26 Oct 2020
Usually, people type the variables that they assign the results to. Or use type casts. But that introduces either a requirement for Cython syntax or some runtime overhead in pure Python (due to a function call to cython.cast()).
Thanks for the response @scoder . I think that we're becoming more comfortable with switching the entire file to Cython. So what I'm hearing is that we'll do something like the following:
cdef class TaskState
dependencies: dict
cdef transition_foo_bar(self, ts: TaskState):
key: str
value: TaskState
for key, value in ts.dependencies.items():
...
This is more c-like in that we're declaring up-front the types of various variables used within a function. Am I right in understanding that Cython will use these type hints effectively when unpacking key, value in the for loop, or do we need to do more here?
mrocklin
on 26 Oct 2020
I'm curious if it is possible to take this further, and modify the types in the class itself away from object type into something more compound, like the following:
dependencies: Dict[str, TaskState]
If we are comfortable moving to more typical Cython syntax, are we also comfortable making use of C++ objects in Cython? For example we could do things like this...
from libcpp.map cimport map
from libcpp.string cimport string
cdef class Obj:
cdef map[string, int] data
Asking as this would allow us to make the kind of optimizations referred to above.
jakirkham
on 26 Oct 2020
I would be inclined to do this incrementally and see what is needed. My _guess_ is that there will be value in the attributes of a TaskState object being easy to manipulate in Python as well. This will probably be useful when we engage the networking side of the scheduler, or the Bokeh dashboard.
To me the following somewhat incremental path seems good:
- Cythonize the entire scheduler.py file, without using C++
- Iterate on that for a while and see how fast we can get while collecting all of the low hanging fruit
- If this is fast enough then we stop here.
- Split the scheduler.pyx file out into a state machine part and a networking part, which gets converted back into pure Python. In doing so we figure out the right split in the scheduler.
- Now that the computational parts are well separated and there is a nice protocol boundary we have a bit more freedom to play with different technologies like C++, Rust, ...
mrocklin
on 26 Oct 2020
I'm skeptical using a C++ map would bring anything. First, you probably want an unordered_map (which is a hash table rather than a tree as in map). Second, Python dicts are quite optimized as far as hash tables go (for example, the hash value of a string is interned and needn't be recomputed, strings can often be compared by pointer..).
pitrou
on 26 Oct 2020
Sure the code above was intended to provide a sample. Not the optimal solution necessarily.
jakirkham
on 26 Oct 2020
Slightly orthogonal, but I think the biggest potential speedup for the scheduler would come from vectorizing scheduler operations. That is, instead of having dicts and sets that are iterated on, find a way to express the scheduling algorithm in terms of vector/matrix operations, and use Numpy to accelerate them. Regardless of the implementation language, implementing set operations in terms of hash table operations will always be costly.
(this has several implications, such as having to identify tasks and other entities by integer ids rather than arbitrary dict keys)
pitrou
on 4 Nov 2020
Jumping on a discussion from forever ago.... that was essentially the issue
with trying to speed it up on pypy. No matter what you do, dict operations
are expensive. If the only thing you do is dict, then cpython/pypy will be
the same speed and probably faster than an equivalent C implementation. But
the implementation in C will probably not use dicts everywhere, because
it's hard. I would strongly suggest doing that work before moving to
anything else, even if it makes CPython not faster (but it should make it
faster).
On Wed, Nov 4, 2020 at 2:58 PM Antoine Pitrou notifications@github.com
wrote:
Slightly orthogonal, but I think the biggest potential speedup for the
scheduler would come from vectorizing scheduler operations. That is,
instead of having dicts and sets that are iterated on, find a way to
express the scheduling algorithm in terms of vector/matrix operations, and
use Numpy to accelerate them. Regardless of the implementation language,
implementing set operations in terms of hash table operations will always
be costly.(this has several implications, such as having to identify tasks and other
entities by integer ids rather than arbitrary dict keys)—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/dask/distributed/issues/854#issuecomment-721716728,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AAAU7OHEZL3AIZY74733OGLSOFFXHANCNFSM4C6ZYWMA
.
fijal
on 4 Nov 2020
Thanks for the comments @pitrou and @fijal (also, it's good to hear from both of you after so long)
I agree that vectorization would probably push us well into the millions of tasks per second mark. If you look at HPC schedulers in academia one sees this kind of throughput. At some point we'll have to think about this, and I look forward to that. I still think that we should be able to do better than the 5k tasks-per-second limit that we have today. Dicts are slow, yes, but not that slow.
@quasiben did some low-level profiling with NVIDIA profilers and found that the majority of our time in CPython wasn't in PyDict_GetItem, but had more to do with attribute access (I think). Previous Cythonization efforts left, I think, some performance on the table. I'd like to explore that to see if we can get up to 50k or so (which would be a huge win for us) before moving on to larger architectural changes.
mrocklin
on 4 Nov 2020
HI Matthew
It might be an unpopular opinion, but the CPython performance does not tell
you much about how it would perform on anything else (e.g. PyPy, numba,
cython, rust, C). E.g. attribute access on PyPy is mostly getting compiled
to an array access
On Wed, Nov 4, 2020 at 4:14 PM Matthew Rocklin notifications@github.com
wrote:
Thanks for the comments @pitrou https://github.com/pitrou and @fijal
https://github.com/fijal (also, it's good to hear from both of you
after so long)I agree that vectorization would probably push us well into the millions
of tasks per second mark. If you look at HPC schedulers in academia one
sees this kind of throughput. At some point we'll have to think about this,
and I look forward to that. I still think that we should be able to do
better than the 5k tasks-per-second limit that we have today. Dicts are
slow, yes, but not that slow.@quasiben https://github.com/quasiben did some low-level profiling with
NVIDIA profilers and found that the majority of our time in CPython wasn't
in PyDict_GetItem, but had more to do with attribute access (I think).
Previous Cythonization efforts left, I think, some performance on the
table. I'd like to explore that to see if we can get up to 50k or so (which
would be a huge win for us) before moving on to larger architectural
changes.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/dask/distributed/issues/854#issuecomment-721755431,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AAAU7ODHEQVJSROZ2RVVDR3SOFOS7ANCNFSM4C6ZYWMA
.
fijal
on 4 Nov 2020
Yeah, I'm hoping that we could get the same performance result with Cython. My hope (perhaps naive) is that there are large optimizations here that PyPy wasn't able to find, and that by writing this code manually and inspecting the generated C that we might be able to find something that PyPy missed. I'm making that bet mostly based on the belief that dict/attribute access isn't that slow, but I'll admit that I'm making it in igornance of an understanding of how awesome PyPy is.
Also, to be clear, I'm not saying "we're going with Cython" but rather "we should explore diving more deeply into Cython and see how it goes"
mrocklin
on 4 Nov 2020
Hi Matthew
I'm really not telling you where you should or should not go. I was
merely saying that everything that does any form of optimization
will have a very different profile (more like PyPy) than CPython and
looking where CPython spends it's time is not that interesting. Using
ints as keys, preallocating arrays (as opposed to resizable ones or
dictionaries) etc. are all sensible strategies that will yield good
results in anything optimizing, like say Java, except in CPython.
Best,
Maciej
On Wed, Nov 4, 2020 at 4:21 PM Matthew Rocklin notifications@github.com wrote:
>
Yeah, I'm hoping that we could get the same performance result with Cython. My hope (perhaps naive) is that there are large optimizations here that PyPy wasn't able to find, and that by writing this code manually and inspecting the generated C that we might be able to find something that PyPy missed. I'm making that bet mostly based on the belief that dict/attribute access isn't that slow, but I'll admit that I'm making it in igornance of an understanding of how awesome PyPy is.
Also, to be clear, I'm not saying "we're going with Cython" but rather "we should explore diving more deeply into Cython and see how it goes"
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub, or unsubscribe.
fijal
on 4 Nov 2020
Ah! Got it.
mrocklin
on 4 Nov 2020
On the interpreter side, conda-forge and Anaconda both build CPython with profile-guided optimizations (PGO). So at least on that side, we are probably as well optimized as we can hope.
jakirkham
on 25 Nov 2020
Related issues
mrocklin
·
4Comments
mrocklin
·
3Comments
quasiben
·
5Comments
 DPeterK
·
3Comments
DPeterK
·
3Comments
 lostmygithubaccount
·
4Comments
lostmygithubaccount
·
4Comments
Most helpful comment
I spent some time exploring Cythonization as a way to reduce scheduler/client overheads.
Here's the benchmark I used:
Here's a timeline* of execution on the client (top) and scheduler (bottom) threads, showing that a significant amount of overhead comes from the following 4 functions:
Client._graph_to_futuresClient.collections_to_dskScheduler.update_graphScheduler.transition*the above figure was generated using NVTX -- Python bindings for which I'm working on :)
Based on the above, I Cythonized a few things within Dask/Distributed to see if I could bring down the overhead from these functions. The results are not ground-breaking, but not too bad for about an hour's work:
client, before and after Cythonization:
scheduler, before and after Cythonization:
See below for the changes I made:
https://github.com/dask/dask/pull/6178
https://github.com/dask/distributed/pull/3770