Detectron2: zero bbox AP while segm AP is nonzero
I am training instance segmentation with custom datasets and mask-rcnn with different backbones. Below are evaluation results:
Loading and preparing results...
DONE (t=0.09s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
COCOeval_opt.evaluate() finished in 1.95 seconds.
Accumulating evaluation results...
COCOeval_opt.accumulate() finished in 0.49 seconds.
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.000
[07/28 21:15:38 d2.evaluation.coco_evaluation]: Evaluation results for bbox:
| AP | AP50 | AP75 | APs | APm | APl |
|:-----:|:------:|:------:|:-----:|:-----:|:-----:|
| 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
Loading and preparing results...
DONE (t=1.52s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *segm*
COCOeval_opt.evaluate() finished in 3.63 seconds.
Accumulating evaluation results...
COCOeval_opt.accumulate() finished in 0.45 seconds.
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.295
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.477
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.316
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.074
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.188
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.336
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.355
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.425
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.426
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.134
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.317
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.481
[07/28 21:15:45 d2.evaluation.coco_evaluation]: Evaluation results for segm:
| AP | AP50 | AP75 | APs | APm | APl |
|:------:|:------:|:------:|:-----:|:------:|:------:|
| 29.527 | 47.702 | 31.592 | 7.419 | 18.774 | 33.596 |
APs for bbox are all zero but segm APs are nonzero.
I plotted some of the predictions alongside gt and the predicted bboxes look OK. Unfortunately I cannot share any images here.
Expected behavior:
Nonezero AP values for both bbox and segm.
Environment:
```---------------------- ------------------------------------------------------------------------------
sys.platform linux
Python 3.7.6 | packaged by conda-forge | (default, Jun 1 2020, 18:57:50) [GCC 7.5.0]
numpy 1.18.5
detectron2 0.2 @/opt/conda/lib/python3.7/site-packages/detectron2
Compiler GCC 7.3
CUDA compiler CUDA 10.1
detectron2 arch flags sm_35, sm_37, sm_50, sm_52, sm_60, sm_61, sm_70, sm_75
DETECTRON2_ENV_MODULE
PyTorch 1.4.0 @/opt/conda/lib/python3.7/site-packages/torch
PyTorch debug build False
GPU available True
GPU 0 Tesla P100-PCIE-16GB
CUDA_HOME /usr/local/cuda
Pillow 7.1.2
torchvision 0.5.0 @/opt/conda/lib/python3.7/site-packages/torchvision
torchvision arch flags sm_35, sm_50, sm_60, sm_70, sm_75
fvcore 0.1.1.post20200716
cv2 4.3.0
PyTorch built with:
- GCC 7.3
- Intel(R) Math Kernel Library Version 2019.0.5 Product Build 20190808 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v0.21.1 (Git Hash 7d2fd500bc78936d1d648ca713b901012f470dbc)
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- NNPACK is enabled
- CUDA Runtime 10.1
- NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_61,code=sm_61;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_37,code=compute_37
- CuDNN 7.6.3
- Magma 2.5.1
- Build settings: BLAS=MKL, BUILD_NAMEDTENSOR=OFF, BUILD_TYPE=Release, CXX_FLAGS= -Wno-deprecated -fvisibility-inlines-hidden -fopenmp -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -O2 -fPIC -Wno-narrowing -Wall -Wextra -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable -Wno-unused-function -Wno-unused-result -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Wno-stringop-overflow, DISABLE_NUMA=1, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, USE_CUDA=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON, USE_STATIC_DISPATCH=OFF,
```
 Nan2018
Nan2018
All 8 comments
From tensorboard:
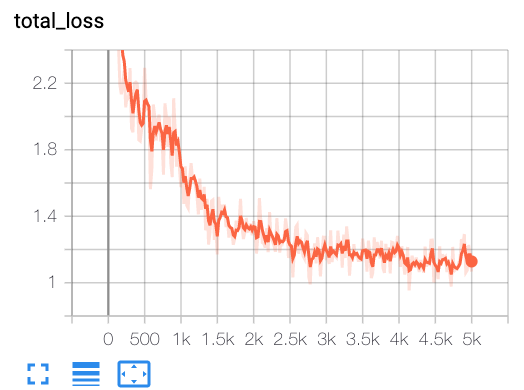
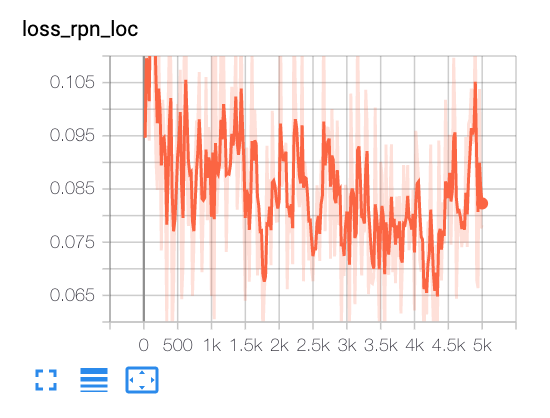
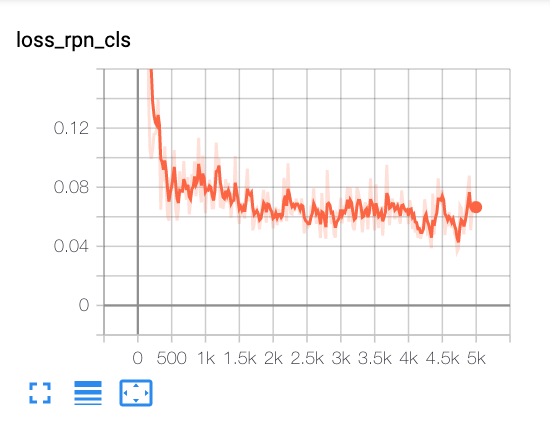
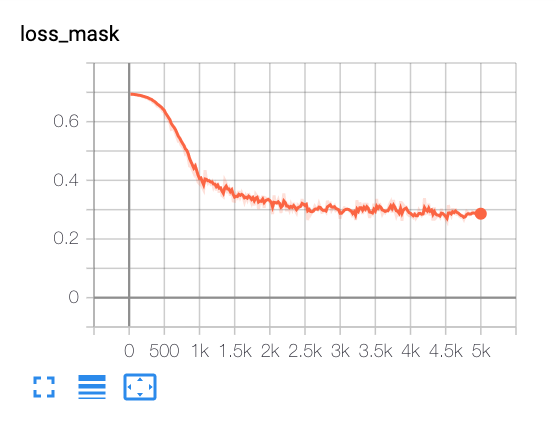
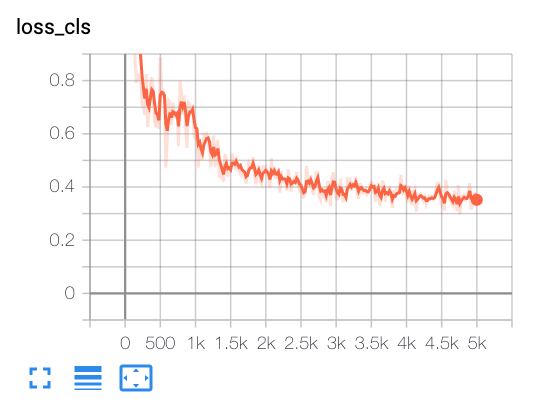
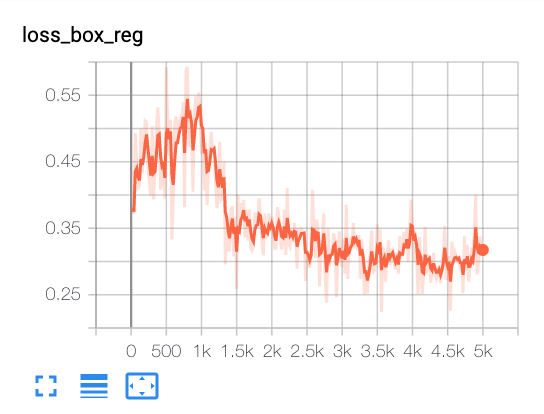
Nan2018
on 29 Jul 2020
We'll need the prediction file and ground truth file in order to see why bbox AP is evaluated to zero. It can be a result of non-standard annotation format, or some corner cases that was handled incorrectly by evaluation code.
 ppwwyyxx
on 30 Jul 2020
ppwwyyxx
on 30 Jul 2020
yeah you need to registered the data val or test before if u want to see the evaluate..
@ppwwyyxx sir , i want to ask something about evaluate i was successfully to evaluate but i dont understand about the Map, why the BBox and segm give bad result just like 50 -70 , but in visualisation give good result (in image) like the result must be 90++, i was tried in mask rcnn and give like 97 Map, but here just 50 - 70 why like that?
or can we just show the result about ap iou 50?
because in my data it show ap iou 50 ==100
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.703
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 1.000
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.777
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.513
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.797
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.737
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.737
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.737
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.550
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.830
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000
| AP | AP50 | AP75 | APs | APm | APl |
|:------:|:-------:|:------:|:------:|:------:|:-----:|
| 70.254 | 100.000 | 77.668 | 51.337 | 79.713 | nan |
| category | AP | category | AP | category | AP |
|:-----------|:-------|:-----------|:-------|:-----------|:-------|
| aorta | 57.640 | hole | 45.033 | la | 77.663 |
| lv | 86.832 | ra | 71.287 | rv | 83.069 |
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type segm
COCOeval_opt.evaluate() finished in 0.00 seconds.
Accumulating evaluation results...
COCOeval_opt.accumulate() finished in 0.01 seconds.
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.650
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 1.000
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.787
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.440
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.755
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.673
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.677
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.677
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.470
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.780
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000
| AP | AP50 | AP75 | APs | APm | APl |
|:------:|:-------:|:------:|:------:|:------:|:-----:|
| 64.958 | 100.000 | 78.713 | 43.968 | 75.453 | nan |
| category | AP | category | AP | category | AP |
|:-----------|:-------|:-----------|:-------|:-----------|:-------|
| aorta | 58.059 | hole | 29.877 | la | 68.248 |
| lv | 76.416 | ra | 74.079 | rv | 83.069 |
OrderedDict([('bbox',
{'AP': 70.25412541254124,
'AP-aorta': 57.64026402640263,
'AP-hole': 45.03300330033003,
'AP-la': 77.66336633663367,
'AP-lv': 86.83168316831683,
'AP-ra': 71.28712871287128,
'AP-rv': 83.06930693069306,
'AP50': 100.0,
'AP75': 77.66776677667767,
'APl': nan,
'APm': 79.71287128712872,
'APs': 51.336633663366335}),
('segm',
{'AP': 64.95811724029545,
'AP-aorta': 58.059405940594054,
'AP-hole': 29.87741631305988,
'AP-la': 68.24752475247524,
'AP-lv': 76.4158415841584,
'AP-ra': 74.07920792079207,
'AP-rv': 83.06930693069306,
'AP50': 100.0,
'AP75': 78.71287128712872,
'APl': nan,
'APm': 75.45297029702971,
'APs': 43.968411126826965})])
 Adithia99
on 30 Jul 2020
Adithia99
on 30 Jul 2020
We'll need the prediction file and ground truth file in order to see why bbox AP is evaluated to zero. It can be a result of non-standard annotation format, or some corner cases that was handled incorrectly by evaluation code.
I am not sure if I can share the files here. In detectron2, is there an out of shelf function to evaluate directly with the prediction and gt files (coco format)? The COCOEval class from pycocotools is nice but lacks per class results.
Nan2018
on 30 Jul 2020
The private evaluation.coco_evaluation._evaluate_predictions_on_coco function can be used to evaluate a prediction & gt file. The predictions should already be saved as a json when COCOEvaluator evaluates it.
We uses our own implementation of COCO API. With this function you can also try the official COCO API
ppwwyyxx
on 30 Jul 2020
The error was from the annotation file. Thanks for helping @ppwwyyxx
closing
Nan2018
on 1 Aug 2020
If you can explain what the error in annotation file is, maybe we are able to detect it and avoid such issues.
ppwwyyxx
on 1 Aug 2020
The original annotation is not coco format, and the bbox coordinates are (x_min, y_max, x_max, y_min). I didn't notice this awkward order when building the data dictionary for detectron2. As a result, the coco format annotation generated by detectron2 is (x_min, y_max, width, -height) for bboxes.
I didn't notice this error because the detectron2.utils.visualizer.Visualizer is able to plot the correct bboxes with this coordinates.
Nan2018
on 1 Aug 2020
Related issues
 aminekechaou
·
3Comments
aminekechaou
·
3Comments
 kl720
·
3Comments
kl720
·
3Comments
 invisprints
·
4Comments
invisprints
·
4Comments
 marcoippolito
·
4Comments
marcoippolito
·
4Comments
 ChungNPH
·
3Comments
ChungNPH
·
3Comments
Most helpful comment
The private
evaluation.coco_evaluation._evaluate_predictions_on_cocofunction can be used to evaluate a prediction & gt file. The predictions should already be saved as a json whenCOCOEvaluatorevaluates it.We uses our own implementation of COCO API. With this function you can also try the official COCO API