Deepspeech: Wrong character timings from ctc_decoder
- I have written a few lines to output character timings in native_client/python/client.py: (l. 59)
def metadata_to_string(metadata):
transcript = ''
starts= ''
for item in metadata.items:
start= "{0:.3f}".format(item.start_time)
starts += start
transcript += start + "\t" + item.character + "\n"
return transcript
- Linux Ubuntu 16.04 in Docker Image from Dockerfile
- Exact command to reproduce: using your pretrained model 0.5.0, your lm, your smoke test audio (all from version 0.5.0)
python native_client/python/client.py \
--model deepspeech-0.5.0/model/output_graph.pb \
--alphabet deepspeech-0.5.0/model/alphabet.txt \
--lm deepspeech-0.5.0/model/lm.binary \
--trie deepspeech-0.5.0/model/trie --extended \
--audio data/smoke_test/LDC93S1_pcms16le_1_8000.wav \
```
- output is:
0.340 s
0.520 h *****
0.380 e
0.480
0.520 h *****
0.560 a
0.600 d
0.700
0.720 t
0.760 o
0.880
0.920 d
0.960 u
1.020 c
1.040 k
1.380 *******
1.240 s
1.280 u
1.300 i
1.340 t
1.380 *******
1.420 a
1.440 n
1.460 d
1.500
1.540 g
1.580 r
1.620 e
1.660 a
1.680 s
1.800 y
1.880
1.960 w
2.000 a
2.040 s
2.280 t
2.360 e
2.440
2.500 a
2.660
2.740 y
2.760 e
2.780 a
2.820 r
- there is a bug (*****) in the start_timings in some cases and I'm not sure, but I think it's happing somwhere in these lines in path_trie.cpp. I don't really know what is saved in children, but I guess too much as it's using the same late "h" time in "she" as in "had", so the "h" in had has apparently a higher probabilty ?! It's in native_client/ctcdecode/path_trie.cpp l.38-48
```cpp
PathTrie* PathTrie::get_path_trie(int new_char, int new_timestep, float cur_log_prob_c, bool reset) {
auto child = children_.begin();
for (child = children_.begin(); child != children_.end(); ++child) {
if (child->first == new_char) {
if (child->second->log_prob_c < cur_log_prob_c) { // here is the problem?
child->second->log_prob_c = cur_log_prob_c;
child->second->timestep = new_timestep;
}
break;
}
}
 malena1906
malena1906
All 7 comments
@malena1906 That analysis does not look wrong. Maybe we should check timestamp does increase in this if branch you are mentionning ?
 lissyx
on 9 Aug 2019
lissyx
on 9 Aug 2019
Yeah, it seems that is indeed where the problem is coming from, but I don't yet fully understand the cause here. I'll take a deeper look.
 reuben
on 9 Aug 2019
reuben
on 9 Aug 2019
OK, I think I've identified the problem, but it's hard to verify how my fix impacts the quality of the timings.
@malena1906 could you try out PR #2302 and see if it fixes the problem for you? Also, if you have any other inputs that had this problem and could try them as well, I'd appreciate it!
reuben
on 16 Aug 2019
For me it fixes the problem with inconsistencies in increasing timings, but I think the two starting characters are now quite different.
Here is the same output with the changes included. Sorry I haven't had time earlier to response
0.000 s
0.020 h
0.360 e
0.460
0.480 h
0.520 a
0.580 d
0.620 e
0.780 d
0.960 u
1.020 c
1.100 s
1.200
1.220 s
1.280 u
1.300 i
1.340 t
1.360
1.420 a
1.440 n
1.460 d
1.500
1.560 g
1.580 r
1.620 e
1.660 a
1.680 s
1.800 y
1.900
1.940 w
1.980 a
2.020 t
2.080 h
2.240 o
2.280 r
2.380
2.500 a
2.560 l
2.680
2.740 y
2.780 e
2.800 a
2.820 r
I'll check the behaviour with more examples later but I agree with @dabinat that all of the rest letter timings are now a bit earlier which is not too bad as they were late before anyways (here all settings same as stated in my first coment)
malena1906
on 21 Aug 2019
Here you can see both OLD and NEW version of the timings in audacity and for the first word its weird, any ideas @reuben ?
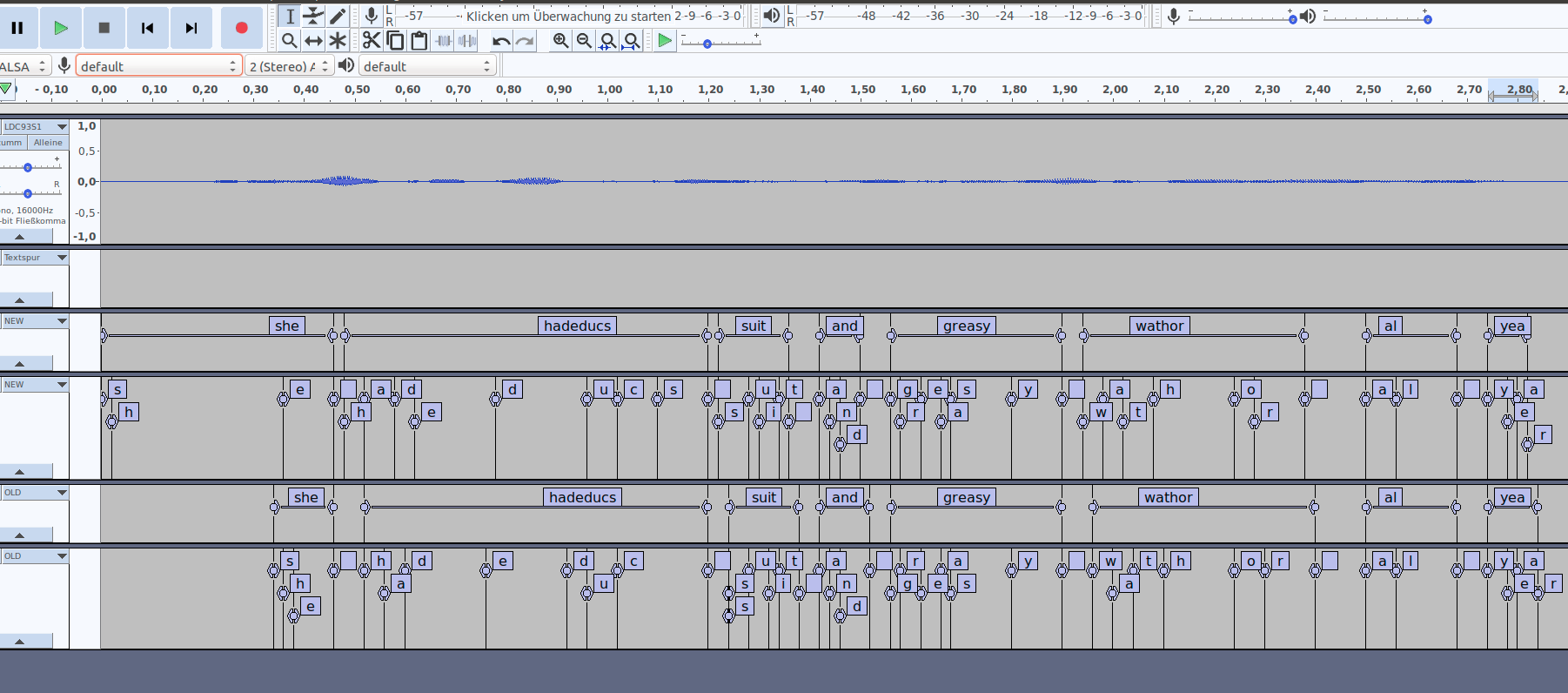
malena1906
on 21 Aug 2019
@malena1906 Oooh, great idea importing the labels into Audacity!
I did some experiments and the first word timings with the fix match what they looked like before the peak probability change (5bf6e63f1b87289ab870d0f027b2be185d5ae79e) was introduced. So this is a behavior unrelated to that change or the fix for this issue. Would you mind opening a new issue about this weird first word behavior? I've tried a couple of approaches trying to fix it but it made other things worse, so I'll have to look at it more carefully when I have some time.
reuben
on 21 Aug 2019
This thread has been automatically locked since there has not been any recent activity after it was closed. Please open a new issue for related bugs.
![lock[bot] picture](https://avatars1.githubusercontent.com/in/6672?v=4&s=40) lock[bot]
on 20 Sep 2019
lock[bot]
on 20 Sep 2019
Related issues
 RaphaelHuirong
·
7Comments
RaphaelHuirong
·
7Comments
 alanbekker
·
3Comments
alanbekker
·
3Comments
 cvenci
·
4Comments
cvenci
·
4Comments
 deepak02
·
7Comments
deepak02
·
7Comments
 The-Gupta
·
7Comments
The-Gupta
·
7Comments
Most helpful comment
Yeah, it seems that is indeed where the problem is coming from, but I don't yet fully understand the cause here. I'll take a deeper look.