Deepspeech: ArchLinux PKGBUILDs for native client and python bindings
I created (unofficial) PKGBUILD files for Arch Linux, which can be downloaded here:
https://github.com/stes/arch-deepspeech
If desired to include such files in the main repository or at the Arch User Repository, I am happy to submit a pull request.
 stes
stes
All 154 comments
Thanks for that @stes !
I had a quick look, and I think that if you want to include that into AUR, however, you might require much more work. I guess it's not a good idea to package binaries built somewhere else, so I think the best course of action would be to rebuilt for Arch on your side, including Tensorflow.
Which main repo are you referring to, Mozilla's one or ArchLinux' one?
 lissyx
on 21 Nov 2017
lissyx
on 21 Nov 2017
@stes I see there's ArchLinux on (Dockerhub)[https://hub.docker.com/r/base/archlinux/], so you can have that as a base image on TaskCluster. So maybe you could do a PR that includes your work to build and produce an ArchLinux package ?
lissyx
on 21 Nov 2017
Hello @lissyx , thanks for responding that fast!
I had a quick look, and I think that if you want to include that into AUR, however, you might require much more work. I guess it's not a good idea to package binaries built somewhere else, so I think the best course of action would be to rebuilt for Arch on your side, including Tensorflow.
Actually the packages I provide in the repository are build by me for Arch Linux (using your "official" build instructions) to make sure to compile against the most recent version of libraries etc.
So maybe you could do a PR that includes your work to build and produce an ArchLinux package?
I looked at the dockerhub images, that seems to be the right way of building the binaries in the future.
I suggest to wait until the pre-trained models are up and I am happy with the packaging process on my own machine.
stes
on 21 Nov 2017
@stes Perfect, I don't know ArchLinux very well, and reading the Makefile or PKGBUILD I could not find where you perform the actual build :). If you do a PR against our TaskCluster changes to produce packages, you'll need to flag me or @reuben as a reviewer first ; PR from non collaborators cannot trigger TaskCluster process (for security reasons), so we need to take a first look and trigger for you (for now). We can help you for that part, though.
lissyx
on 21 Nov 2017
@stes Would you like to make a PR that at least links to where people can find your packages? We could add that in the README, like we did for Rust and Go bindings.
lissyx
on 14 Dec 2017
@lissyx yes of course, added #1109
I put it just under the Rust and Go bindings, although it is technically not about bindings, but I wanted to prevent clutter in the README.
I can update the PKGBUILD in the next days to use the most recent version of the deep speech model and also include a download procedure for pre-trained models. I wanted to let the release settle a bit before packaging anything.
Once that works, I can look into the TaskCluster build (for that I will probably approach you again).
stes
on 15 Dec 2017
Thanks! We should be doing a dot release soon, I hope :)
lissyx
on 15 Dec 2017
I currently try to fix the deepspeech PKGBUILD on AUR with the latest version. The problem is that the readme tagged with 0.1.1 is outdated and the update in the master is to new for version 0.1.1. So I had to guess some build options, but it still fails. Can anyone please help me how to properly build 0.1.1? The previous version compiled fine (but with some security problems of the binary itsef).
# Maintainer: Jonas Heinrich <[email protected]>
# Contributor: NicoHood <archlinux {cat} nicohood {dog} de>
pkgname=deepspeech
pkgver=0.1.1
pkgrel=1
pkgdesc="A TensorFlow implementation of Baidu's DeepSpeech architecture"
arch=('x86_64')
url="https://github.com/mozilla/DeepSpeech"
license=('MPL2')
makedepends=('bazel' 'python-numpy' 'python-pip' 'python-wheel' 'python-setuptools' 'git')
depends=('python-tensorflow' 'python-scipy' 'sox' 'gcc-libs')
source=("deepspeech-${pkgver}.tar.gz::https://github.com/mozilla/DeepSpeech/archive/v${pkgver}.tar.gz"
"git+https://github.com/mozilla/tensorflow.git") #TODO use fixed git commit/version
sha512sums=('63a5b73fe5b294b97b029e963a3c76f73e6c0d39895135c8ddc6eac502dcae0fe32e6babed55c3308add72e6d195f7a994d40eb4c149a54d9dcc3a017a6c28c8'
'SKIP')
# TODO gpg signatures
# TODO add models as extra/split package
# TODO add python bindings
prepare() {
cd "$srcdir/tensorflow"
# These environment variables influence the behavior of the configure call below.
export PYTHON_BIN_PATH=/usr/bin/python
export USE_DEFAULT_PYTHON_LIB_PATH=1
export TF_NEED_JEMALLOC=1
export TF_NEED_GCP=0
export TF_NEED_HDFS=0
export TF_NEED_S3=0
export TF_ENABLE_XLA=1
export TF_NEED_GDR=0
export TF_NEED_VERBS=0
export TF_NEED_OPENCL=0
export TF_NEED_MPI=0
ln -sf ../DeepSpeech-${pkgver}/native_client ./
}
build() {
cd "$srcdir/tensorflow"
export CC_OPT_FLAGS="-march=x86-64"
export TF_NEED_CUDA=0
./configure
bazel build -c opt --copt=-O3 //native_client:libctc_decoder_with_kenlm.so
bazel build --config=monolithic -c opt --copt=-O3 --copt=-fvisibility=hidden \
//tensorflow:libtensorflow_cc.so \
//tensorflow:libtensorflow_framework.so \
//native_client:deepspeech \
//native_client:deepspeech_utils \
//native_client:generate_trie
# bazel build -c opt --copt=-O3 //tensorflow:libtensorflow_cc.so \
# //tensorflow:libtensorflow_framework.so \
# //native_client:deepspeech \
# //native_client:deepspeech_utils \
# //native_client:ctc_decoder_with_kenlm \
# //native_client:generate_trie
cd "${srcdir}/DeepSpeech-${pkgver}/native_client"
make deepspeech
}
package() {
cd "${srcdir}/DeepSpeech-${pkgver}/native_client"
PREFIX="${pkgdir}/usr" make install
}
...
INFO: From Compiling native_client/generate_trie.cpp:
In file included from native_client/generate_trie.cpp:7:0:
native_client/trie_node.h:29:28: warning: multi-character character constant [-Wmultichar]
static const int MAGIC = 'TRIE';
^~~~~~
INFO: Elapsed time: 3278.809s, Critical Path: 158.85s
INFO: Build completed successfully, 3590 total actions
c++ -o deepspeech `pkg-config --cflags sox` client.cc -Wl,--no-as-needed -Wl,-rpath,\$ORIGIN -L/build/deepspeech/src/tensorflow/bazel-bin/tensorflow -L/build/deepspeech/src/tensorflow/bazel-bin/native_client -ldeepspeech -ldeepspeech_utils -ltensorflow_cc -ltensorflow_framework `pkg-config --libs sox`
/tmp/ccsWte2Z.o: In function `LocalDsSTT(DeepSpeech::Model&, short const*, unsigned long, int)':
client.cc:(.text+0x94): undefined reference to `DeepSpeech::Model::getInputVector(short const*, unsigned int, int, float**, int*, int*)'
client.cc:(.text+0xb9): undefined reference to `DeepSpeech::Model::infer(float*, int, int)'
/tmp/ccsWte2Z.o: In function `main':
client.cc:(.text+0x22e): undefined reference to `DeepSpeech::Model::Model(char const*, int, int, char const*, int)'
client.cc:(.text+0x288): undefined reference to `DeepSpeech::Model::enableDecoderWithLM(char const*, char const*, char const*, float, float, float)'
client.cc:(.text+0x7bc): undefined reference to `DeepSpeech::Model::~Model()'
client.cc:(.text+0x7e1): undefined reference to `DeepSpeech::Model::~Model()'
collect2: error: ld returned 1 exit status
make: *** [Makefile:22: deepspeech] Error 1
==> ERROR: A failure occurred in build().
Aborting...
==> ERROR: Build failed, check /var/lib/archbuild/extra-x86_64/arch/build
 NicoHood
on 25 Feb 2018
NicoHood
on 25 Feb 2018
@NicoHood Please stick to v0.1.1, and document exactly your issues. From what I'm reading, you are mixing v0.1.1 with master TensorFlow ? Please use r1.4 branch from mozilla/tensorflow with DeepSpeech v0.1.1
lissyx
on 25 Feb 2018
I am happy to use a fixed tensorflow version/branch. The problem was I did not know about this branch fits to 0.1.1. Where can I find this information for future builds?
This branch fails at the version check:
==> Starting build()...
Extracting Bazel installation...
You have bazel 0.10.1- (@non-git) installed.
Add "--config=mkl" to your bazel command to build with MKL support.
Please note that MKL on MacOS or windows is still not supported.
If you would like to use a local MKL instead of downloading, please set the environment variable "TF_MKL_ROOT" every time before build.
Configuration finished
............
Loading:
Loading: 0 packages loaded
Loading: 0 packages loaded
ERROR: /build/deepspeech/src/tensorflow/WORKSPACE:15:1: Traceback (most recent call last):
File "/build/deepspeech/src/tensorflow/WORKSPACE", line 15
closure_repositories()
File "/build/.cache/bazel/_bazel_builduser/1f26581d0edfc50ffeb635c4dee8caad/external/io_bazel_rules_closure/closure/repositories.bzl", line 69, in closure_repositories
_check_bazel_version("Closure Rules", "0.4.5")
File "/build/.cache/bazel/_bazel_builduser/1f26581d0edfc50ffeb635c4dee8caad/external/io_bazel_rules_closure/closure/repositories.bzl", line 172, in _check_bazel_version
fail(("%s requires Bazel >=%s but was...)))
Closure Rules requires Bazel >=0.4.5 but was 0.10.1- (@non-git)
ERROR: Error evaluating WORKSPACE file
ERROR: /build/deepspeech/src/tensorflow/WORKSPACE:41:1: Traceback (most recent call last):
File "/build/deepspeech/src/tensorflow/WORKSPACE", line 41
tf_workspace()
File "/build/deepspeech/src/tensorflow/tensorflow/workspace.bzl", line 146, in tf_workspace
check_version("0.5.4")
File "/build/deepspeech/src/tensorflow/tensorflow/workspace.bzl", line 56, in check_version
fail("\nCurrent Bazel version is {}, ...))
Current Bazel version is 0.10.1- (@non-git), expected at least 0.5.4
ERROR: Error evaluating WORKSPACE file
ERROR: Skipping '//native_client:libctc_decoder_with_kenlm.so': error loading package 'external': Package 'external' contains errors
WARNING: Target pattern parsing failed.
ERROR: error loading package 'external': Package 'external' contains errors
INFO: Elapsed time: 1.351s
FAILED: Build did NOT complete successfully (0 packages loaded)
==> ERROR: A failure occurred in build().
Aborting...
==> ERROR: Build failed, check /var/lib/archbuild/extra-x86_64/arch/build
@NicoHood This is an upstream TensorFlow issue, you should try lower versions of Bazel. We sticked to 0.5.4 for some time, and this was working with this specific branch, and I explicitely remember that some people were running into issues back in the days with Bazel ~0.7.
lissyx
on 25 Feb 2018
@NicoHood I know it might be inconvenient, this is also why I've opened https://github.com/mozilla/DeepSpeech/issues/1253 and related upstream issues to see how we can improve stuff. In the specific case of Bazel versions, you should refer to TensorFlow instructions as we link them in our README: https://github.com/mozilla/DeepSpeech/blob/master/native_client/README.md#building
lissyx
on 25 Feb 2018
Hm, this gets too complicated for what its worth then. What about the master branch of deepspeech, with which version of tensorflow can I compile this? 1.5?
Also we have tensorflow 1.5 in our official repositories, can I somehow reuse those compiled .so files? Compiling everything takes extremely long.
What about the changes you made in your mozilla branch? Can you push them generic to upstream so no special fork is requried?
NicoHood
on 25 Feb 2018
@NicoHood Yes, current master is bound with r1.5. You need to rebuild, because we switched to monolithic builds. Our changes are easy to find: it's mostly about RPi3 cross-compilation and tfcompile. If you use upstream TensorFlow, it's going to choke on some definitions. Pushing this to upstream is not that trivial ...
lissyx
on 25 Feb 2018
@NicoHood Besides, I don't see what is complicated, just use a local install of Bazel v0.5.4 and that should work, playing with bazel's --output_user_root and --output_base.
lissyx
on 25 Feb 2018
@NicoHood If you want to stick to upstream, you can just patch native_client/BUILD file to remove the definitions of deepspeech_model_core, tfcompile.config, tfcompile.model and libdeepspeech_model.so.
Building from scratch only our stuff (CPU build) is completed in about 600-800 secs on my desktop (i7-4790K).
lissyx
on 25 Feb 2018
How would I start the build then? I installed tensorflow and modfied BUILD like this (not sure if that was correct)
diff --git a/native_client/BUILD b/native_client/BUILD
index 5d001c9..1f4a061 100644
--- a/native_client/BUILD
+++ b/native_client/BUILD
@@ -15,40 +15,9 @@ config_setting(
}
)
-tf_library(
- name = "deepspeech_model_core",
- cpp_class = "DeepSpeech::nativeModel",
- # We don't need tests or benchmark binaries
- gen_test=False, gen_benchmark=False,
- # graph and config will be generated at build time thanks to the matching
- # genrule.
- graph = "tfcompile.model.pb",
- config = "tfcompile.config.pbtxt",
- # This depends on //tensorflow:rpi3 condition defined in mozilla/tensorflow
- tfcompile_flags = select({
- "//tensorflow:rpi3": str('--target_cpu="cortex-a53"'),
- "//conditions:default": str('')
- }),
-)
-
-genrule(
- name = "tfcompile.config",
- srcs = ["tfcompile.config.pbtxt.src"],
- outs = ["tfcompile.config.pbtxt"],
- cmd = "$(location :model_size.sh) $(SRCS) $(DS_MODEL_TIMESTEPS) $(DS_MODEL_FRAMESIZE) >$@",
- tools = [":model_size.sh"]
-)
-
-genrule(
- name = "tfcompile.model",
- outs = ["tfcompile.model.pb"],
- cmd = "cp $(DS_MODEL_FILE) $@"
-)
-
tf_cc_shared_object(
name = "libdeepspeech.so",
srcs = ["deepspeech.cc", "deepspeech.h", "deepspeech_utils.h", "alphabet.h", "beam_search.h", "trie_node.h"] +
- if_native_model(["deepspeech_model_core.h"]) +
glob(["kenlm/lm/*.cc", "kenlm/util/*.cc", "kenlm/util/double-conversion/*.cc",
"kenlm/lm/*.hh", "kenlm/util/*.hh", "kenlm/util/double-conversion/*.h"],
exclude = ["kenlm/*/*test.cc", "kenlm/*/*main.cc"]) +
@@ -101,11 +70,6 @@ tf_cc_shared_object(
defines = ["KENLM_MAX_ORDER=6"],
)
-tf_cc_shared_object(
- name = "libdeepspeech_model.so",
- deps = [":deepspeech_model_core"]
-)
-
# We have a single rule including c_speech_features and kissfft here as Bazel
# doesn't support static linking in library targets.
[arch@talloniv DeepSpeech]$ bazel build -c opt --copt=-O3 //native_client:libctc_decoder_with_kenlm.so
ERROR: The 'build' command is only supported from within a workspace.
How would I start the build and link to the system tensorflow install?
NicoHood
on 25 Feb 2018
@NicoHood This is documented in the native_client/README.md, you need to symlink from TensorFlow's source to native_client/: https://github.com/mozilla/DeepSpeech/blob/master/native_client/README.md#preparation
lissyx
on 25 Feb 2018
@NicoHood Please note you still need to build using --config=monolithic --copt=-fvisibility=hidden for libdeepspeech.so.
lissyx
on 25 Feb 2018
But I only can do this at the same time when I am also building tensorflow. So I need to package tensorflow at the same time when also packaging deepspeech. I though this can be reused with an already installed tensorflow package, does not seem so. Not sure how this can be speed up then.
NicoHood
on 25 Feb 2018
The readme does not note those options you mentioned. They also do not state the bazel version nor the tensorflow version.
https://github.com/mozilla/DeepSpeech/tree/master/native_client#building
NicoHood
on 25 Feb 2018
@NicoHood No, you don't need to package tensorflow at the same time. It's all statically compiled into libdeepspeech.so
lissyx
on 25 Feb 2018
@NicoHood As I said earlier, the Bazel versions requirements are coming from TensorFlow, not from us.
lissyx
on 25 Feb 2018
@NicoHood The flags are properly documented: https://github.com/mozilla/DeepSpeech/tree/master/native_client#building:
bazel build -c opt --copt=-O3 //native_client:libctc_decoder_with_kenlm.so
bazel build --config=monolithic -c opt --copt=-O3 --copt=-fvisibility=hidden //native_client:libdeepspeech.so //native_client:deepspeech_utils //native_client:generate_trie
I also tried the latest version of deepspeech master which also fails, but this time with a runtime error:
$ ./deepspeech output_graph.pb test2.wav alphabet.txt lm.binary trie
Warning: reading entire model file into memory. Transform model file into an mmapped graph to reduce heap usage.
2018-02-26 13:52:36.973865: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA
Error: Alphabet size does not match loaded model: alphabet has size 1164, but model has 28 classes in its output. Make sure you're passing an alphabet file with the same size as the one used for training.
Loading the LM will be faster if you build a binary file.
Reading alphabet.txt
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
terminate called after throwing an instance of 'lm::FormatLoadException'
what(): native_client/kenlm/lm/read_arpa.cc:65 in void lm::ReadARPACounts(util::FilePiece&, std::vector<long unsigned int>&) threw FormatLoadException.
first non-empty line was "a" not \data\. Byte: 218
Aborted (core dumped)
I am wondering why the alphabet now causes problems. Maybe you changed the format!? It seems its better to wait for the next release. Feel free to contact me before you tag a new release, I am happy to test it for Arch Linux :)
NicoHood
on 26 Feb 2018
You are passing arguments in the wrong order, wav should be the last one. You also have not setup git-lfs as documented so the language model cannot be read correctly (last error).
lissyx
on 26 Feb 2018
Oh what a dump mistake X_x. It now works:
$ ./deepspeech output_graph.pb alphabet.txt lm.binary trie test2.wav
Warning: reading entire model file into memory. Transform model file into an mmapped graph to reduce heap usage.
2018-02-26 14:22:52.601762: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA
night for
Do I really need git lfs? I only compiled deepspeech as described in the readme, I did not train a model. I just used the model from 0.1.1.
Do you know how to get rid of the warning Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA? The processing is quite slow on my i7, I guess that is due to this missing optimization?
NicoHood
on 26 Feb 2018
@NicoHood You need git-lfs to use the git-stored model, under data/lm. If you downloaded the deepspeech-models tarball, you can just use the lm.binary and trie from your extraction.
Regarding your warning, that's because we document conservative optimizations. You have to weight the level of optimizations that you pass to TensorFlow with what users might have.
So since you passed nothing, except --copt=-O3 then nothing is available. TensorFlow r1.6 (upcoming) defaulted to up-to AVX: https://github.com/tensorflow/tensorflow/blame/26ae3287a12c71fccaec9ea74f55b6a51a3d33c6/RELEASE.md#L5
Our TaskCluster-builds are also upto AVX, by building everything with:
--copt=-mtune=generic --copt=-march=x86-64 --copt=-msse --copt=-msse2 --copt=-msse3 --copt=-msse4.1 --copt=-msse4.2 --copt=-mavx
Just be aware that if you enable some optimizations then TensorFlow (and thus DeepSpeech) won't be able to run on a hardware that does not have them. This is a limitation from TensorFlow :/.
lissyx
on 26 Feb 2018
Thanks, the warnings now disappeared, the processing is still slow as it is only running in a single core. Is there any chance to do multi core processing?
The available trained model, was this created from the user data of the mozilla site or was it created by some librespeech test data? On my PC it is not working as good as on someone else setup. I am wondering if its a problem with my microphone or his/my voice. He assumed the current model relys on very clear speech, is that true?
NicoHood
on 26 Feb 2018
@NicoHood It should leverage multithreading, at least our builds do, you might have to force linking with pthread. Regarding your other questions, I would advise having a look at other issues and at discourse https://discourse.mozilla.org/c/deep-speech, because this is going a bit further than your package. It could be the mic yes, it also depends how you perform the recording: bitrate, etc. You should do mono/16kHz. We have data showing that converting from other tricks the model (likely non earable noise?).
lissyx
on 26 Feb 2018
@NicoHood Aside, I've just closed https://github.com/mozilla/DeepSpeech/issues/1253 but I invite you to follow my suggestion in the latest comment https://github.com/mozilla/DeepSpeech/issues/1253#issuecomment-368835718 so that we can improve the process for people doing important work like yours of packaging / contributing bindings.
lissyx
on 27 Feb 2018
1st comment: Yes the pip installation works with multiple cores it seems. If you are building with other options than in the readme, thats not a good idea. You should at least note both of them, so the results are reproducible and people like me are not wondering about the bugs.
2nd comment:
Doing more prereleases could help. This gives the devs a fixed state where they can test on, instead of a random master commit. Also it would help if you can name us some deadlines where a new version is expected.
For example I will not try any work on deepspeech until the next release, as the current version is too hard to patch and I know the next version will work better (from the git master test). However I will not test this in detail, as I dont know when the next release happens and how much is about to change. will it be within the next month or later?
So prereleases and release dates would be nice. They dont have to be that accurate, just to understand when you wish to have feedback from the maintainers.
NicoHood
on 27 Feb 2018
@NicoHood Well, all the "release" build options are properly available to anyone, though it might not be "easy" to find: https://github.com/mozilla/tensorflow/blob/r1.5/tc-vars.sh#L76-L81 https://github.com/mozilla/tensorflow/blob/r1.5/tc-vars.sh#L97-L100
Putting that in the README is risky, because it might intrigate people on erroneous / incompatible builds flags: so far, most of the people who had to rebuild were people with CPUs not supporting AVX / AVX2, so we should be careful in what we document there. It's easier to debug from the warning tensorflow outputs when your CPU supports instructions that the build does not has, rather than to debug "which optimization flag is triggering this segfault".
Regarding deadlines, we started documenting things a bit better: https://github.com/mozilla/DeepSpeech/projects but we don't have any date set, because it's hard to give anything even unaccurate so far. Would a date that is inaccurate up to weeks make sense and help?
For your other comments, there should be no reason to patch anything. Building with https://github.com/mozilla/tensorflow should work flawlessly (it does on TaskCluster). And thus, git pull on both repo should be enough. And yes, I'm sorry, there are prerequistes from TensorFlow and we cannot do anything about that. But I documented you simple way to install a different local version of Bazel to be able to build, this should work (this is what I do as well).
So, Bazel v0.5.4 + https://github.com/mozilla/tensorflow/tree/r1.4 + https://github.com/mozilla/DeepSpeech/tree/v0.1.1 and it must work :)
lissyx
on 27 Feb 2018
For the pre-release process, can you elaborate a bit on your idea ? I'm not sure I get the proper picture of the process that would help you.
lissyx
on 27 Feb 2018
About the build options: Someone on AUR wrote:
also i suggest to change "export CC_OPT_FLAGS="-march=x86-64"" to "export CC_OPT_FLAGS="-march=native"" to enable ALL the optimization for your hardware
Maybe this could be best for all users, I have to test it.
About the pre-release process:
Lets say you want to release v0.2.0 in about 2 weeks and most/all of the features are integrated. Then you can create a new git tag and mark it as prerelease on Github (for example 0.2.0-rc1). All maintainers can now test this fixed version and report bugs. They all test the same version, not some random commit on the master branch. This means if the same bugs occur for mutliple people it might be easier to find, and also you can compare against the next RC2 then.
NicoHood
on 27 Feb 2018
@NicoHood I second the -march=native removal. About the RC process, that might be a good idea, but it requires some work, I don't think we want to publish RC packages to pypi/npm (which is what happens right now when we do a release).
lissyx
on 27 Feb 2018
@NicoHood Actually, I see TensorFlow rc packages on Pypi, so ... We'll have to evaluate :)
lissyx
on 1 Mar 2018
@lissyx Could you please tag a new (pre) release? It looks like the latest git version of deepspeech fixed lots of bugs and is also easier to build. It would help us to test your software faster. Thanks in advance.
 AtosNicoS
on 23 Apr 2018
AtosNicoS
on 23 Apr 2018
@AtosNicoS I cannot right now, we don't have the infrastructure setup for that, but you can give a try to current master. I hope to address that this week in https://github.com/mozilla/DeepSpeech/issues/1293, but I have to complete the ARM / ARM64 hardware part first and I have to debug power supply right now :)
lissyx
on 23 Apr 2018
Could you please give me a hint which tensorflow branch I need to use for building the deepspeech master? r1.6, r1.7 or master?
This is the error I get with 1.6:
Analyzing: target //native_client:libctc_decoder_with_kenlm.so (2 packages loaded)
WARNING: /build/.cache/bazel/_bazel_builduser/1f26581d0edfc50ffeb635c4dee8caad/external/protobuf_archive/WORKSPACE:1: Workspace name in /build/.cache/bazel/_bazel_builduser/1f26581d0edfc50ffeb635c4dee8caad/external/protobuf_archive/WORKSPACE (@com_google_protobuf) does not match the name given in the repository's definition (@protobuf_archive); this will cause a build error in future versions
Analyzing: target //native_client:libctc_decoder_with_kenlm.so (10 packages loaded)
Analyzing: target //native_client:libctc_decoder_with_kenlm.so (18 packages loaded)
Analyzing: target //native_client:libctc_decoder_with_kenlm.so (44 packages loaded)
ERROR: /build/.cache/bazel/_bazel_builduser/1f26581d0edfc50ffeb635c4dee8caad/external/jpeg/BUILD:126:12: Illegal ambiguous match on configurable attribute "deps" in @jpeg//:jpeg:
@jpeg//:k8
@jpeg//:armeabi-v7a
Multiple matches are not allowed unless one is unambiguously more specialized.
ERROR: Analysis of target '//native_client:libctc_decoder_with_kenlm.so' failed; build aborted:
/build/.cache/bazel/_bazel_builduser/1f26581d0edfc50ffeb635c4dee8caad/external/jpeg/BUILD:126:12: Illegal ambiguous match on configurable attribute "deps" in @jpeg//:jpeg:
@jpeg//:k8
@jpeg//:armeabi-v7a
Multiple matches are not allowed unless one is unambiguously more specialized.
INFO: Elapsed time: 5.139s
FAILED: Build did NOT complete successfully (45 packages loaded)
@AtosNicoS DeepSpeech master goes with TensorFlow r1.6
lissyx
on 23 Apr 2018
Is the error I am seeing possibly because of the recent arm patches? Those are new, and I am building against mozillas tensorflow r1.6 branch.
AtosNicoS
on 23 Apr 2018
@AtosNicoS There was no error when I replied to your message :(. Misread your reply, since you are using mozilla/tensorflow r1.6 branch, I'm pretty sure it's only because of Bazel not being v0.10.0.
lissyx
on 23 Apr 2018
@AtosNicoS The v0.10.0 Bazel hint is documented at https://github.com/mozilla/DeepSpeech/blob/master/native_client/README.md#building, but I'm sad I missed the occasion of updating the doc to also make it clear to use mozilla/tensorflow repo :(
lissyx
on 23 Apr 2018
I am using the latest bazel 0.12.0, that is propably the problem. But I cannot simply downgrade on Arch Linux as you never know if something else will then break. Why would such a minor update break the hole build system? Is there a way to fix it?
AtosNicoS
on 23 Apr 2018
@AtosNicoS I have no idea, we are tied to what TensorFlow depends on. Can't you just use a local install of the proper bazel version, to avoid interfering with a system-wide installation ? You should be able to get the installer from their releases and then install it in your home or somewhere else locally. Then using the --output_user_root and --output_base flags, you should be able to ensure it also does not interfer with any running system bazel.
lissyx
on 23 Apr 2018
I was able to build it with the following PKGBUILD and patch from the archlinux tensorflow PKGBUILD:
# Maintainer: Jonas Heinrich <[email protected]>
# Contributor: Jonas Heinrich <[email protected]>
pkgname=deepspeech
pkgver=v0.1.1.r67.gae146d0
pkgrel=1
pkgdesc="A TensorFlow implementation of Baidu's DeepSpeech architecture"
arch=('x86_64')
url="https://github.com/mozilla/DeepSpeech"
license=('MPL2')
makedepends=('bazel' 'python-numpy' 'python-pip' 'python-wheel' 'python-setuptools' 'git')
depends=('python-tensorflow' 'python-scipy' 'sox')
source=("git+https://github.com/mozilla/deepspeech.git"
"git+https://github.com/mozilla/tensorflow.git#branch=r1.6"
17508.patch)
sha512sums=('SKIP'
'SKIP'
'18e3b22e956bdd759480d2e94212eb83d6a59381f34bbc7154cadbf7f42686c2f703cc61f81e6ebeaf1da8dc5de8472e5afc6012abb1720cadb68607fba8e8e1')
pkgver() {
cd "$pkgname"
git describe --long --tags | sed 's/\([^-]*-g\)/r\1/;s/-/./g'
}
prepare()
{
patch -Np1 -i ${srcdir}/17508.patch -d tensorflow
cd "$srcdir/tensorflow"
# These environment variables influence the behavior of the configure call below.
export PYTHON_BIN_PATH=/usr/bin/python
export USE_DEFAULT_PYTHON_LIB_PATH=1
export TF_NEED_JEMALLOC=1
export TF_NEED_GCP=0
export TF_NEED_HDFS=0
export TF_NEED_S3=0
export TF_ENABLE_XLA=1
export TF_NEED_GDR=0
export TF_NEED_VERBS=0
export TF_NEED_OPENCL=0
export TF_NEED_MPI=0
ln -sf ../deepspeech/native_client ./
}
build() {
cd "$srcdir/tensorflow"
export CC_OPT_FLAGS="-march=x86-64"
export TF_NEED_CUDA=0
./configure
# bazel build -c opt --copt=-O3 \
# //tensorflow:libtensorflow_cc.so \
# //tensorflow:libtensorflow_framework.so \
# //native_client:deepspeech \
# //native_client:deepspeech_utils \
# //native_client:ctc_decoder_with_kenlm \
# //native_client:generate_trie
bazel build -c opt --copt=-O3 --copt="-D_GLIBCXX_USE_CXX11_ABI=0" //native_client:libctc_decoder_with_kenlm.so
bazel build --config=monolithic -c opt --copt=-O3 --copt="-D_GLIBCXX_USE_CXX11_ABI=0" --copt=-fvisibility=hidden //native_client:libdeepspeech.so //native_client:deepspeech_utils //native_client:generate_trie
cd "${srcdir}/deepspeech/native_client"
make deepspeech
}
package() {
cd "${srcdir}/deepspeech/native_client"
PREFIX=${pkgdir}/usr make install
}
From 340327dc8cc637fef01e66f7dd7cae68ce259b94 Mon Sep 17 00:00:00 2001
From: Yun Peng <[email protected]>
Date: Wed, 7 Mar 2018 13:50:31 +0100
Subject: [PATCH] jpeg.BUILD: Using --cpu instead of --android_cpu
---
third_party/jpeg/jpeg.BUILD | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/third_party/jpeg/jpeg.BUILD b/third_party/jpeg/jpeg.BUILD
index 87a23925c43..4418ac32fc4 100644
--- a/third_party/jpeg/jpeg.BUILD
+++ b/third_party/jpeg/jpeg.BUILD
@@ -526,12 +526,12 @@ config_setting(
config_setting(
name = "armeabi-v7a",
- values = {"android_cpu": "armeabi-v7a"},
+ values = {"cpu": "armeabi-v7a"},
)
config_setting(
name = "arm64-v8a",
- values = {"android_cpu": "arm64-v8a"},
+ values = {"cpu": "arm64-v8a"},
)
config_setting(
Right, thanks! Looks like https://github.com/tensorflow/tensorflow/commit/340327dc8cc637fef01e66f7dd7cae68ce259b94 is an actual upstream patch :)
You only build the C++ codenase, no NodeJS nor Python package ?
lissyx
on 23 Apr 2018
Not yet, as I just analyze how good the recognition works. The problem I got now is that my build only uses a single core which makes it very slow. I must be still missing something in my build.
AtosNicoS
on 23 Apr 2018
@AtosNicoS Try forcing -lpthread, somehow Bazel seems to have a different behavior between 0.12.0 and 0.10.0. Maybe also it's just because of the optimization levels, and threading only kicks in when you leverage SSE* and AVX stuff. You should hang out on Discourse, there are some feedback on the quality of the model, and tips on recording audio, which might save you troubles.
lissyx
on 23 Apr 2018
@AtosNicoS I know nothing about ArchLinux, but I'd like to give it a try on TaskCluster, how should I be using your PKGBUILD file to produce some installable package ?
lissyx
on 23 Apr 2018
First you need a basic Arch Linux installation. I hope your taskcluster provides such an image!? Otherwise you have to read the wiki on how to install an Arch Linux system. I could also provide you with some installer scripts, but this is not advices.
Then you need to install the general development environment:
sudo pacman -S base-devel devtools --needed
And also edit/create your makepkg config to use multiple processors:
nano ~/makepkg.conf
---------------------------
MAKEFLAGS="-j$(nproc)"
Then download the PKGBUILD and the patch in the same folder and run extra-x86_64-build. It will compile the code and provide you with some package. Install it with sudo pacman -U <name>.pkg.tar.xz. I hope that helps.
AtosNicoS
on 24 Apr 2018
Thanks @AtosNicoS ! We can use any DockerHub image, so I can use https://hub.docker.com/r/base/archlinux/ :-).
lissyx
on 24 Apr 2018
@AtosNicoS I'm unable to install devtools package: https://taskcluster-artifacts.net/PCVDMDu8RkeznwJAPNY6yA/0/public/logs/live_backing.log
i'm using the archimg/base-devel:2018.04.01 Docker image: https://github.com/archimg/archlinux/blob/master/Dockerfiles/basement/Dockerfile.base-devel
And the payload:
pacman --noconfirm -Syyu && pacman --noconfirm -S --needed git devtoools && adduser --system --home /home/build-user build-user && cd /home/build-user/ && echo -e \"#!/bin/bash\\nset -xe\\n env && id && git clone --quiet https://github.com/lissyx/DeepSpeech.git ~/DeepSpeech/ds/ && cd ~/DeepSpeech/ds && git checkout --quiet 9bc2d682e5cb17d46b79feeaa1c3515bdb6b5d3d\" > /tmp/clone.sh && chmod +x /tmp/clone.sh && sudo -H -u build-user /bin/bash /tmp/clone.sh && true && sudo -H -u build-user --preserve-env /bin/bash /home/build-user/DeepSpeech/ds/packages/archlinux/build.sh && sudo -H -u build-user /bin/bash /home/build-user/DeepSpeech/ds/packages/archlinux/package.sh\n
You used 3 'o' devtoools, but it is devtools. (it was my fault, i've edited my post above now)
Also there is no need to create a builduser etc. Devtools will handel everything for you and build you a clean package in a chroot only with the specified dependencies in the PKGBUILD.
I have not used such docker images before, but to me it sounds wrong to build packages different than what I suggested. The base-devel image is a correct choice though :)
AtosNicoS
on 24 Apr 2018
@AtosNicoS Good catch. What's wrong with the way I'm building it? I'm using the steps you documented :)
lissyx
on 24 Apr 2018
@AtosNicoS Okay, it's a dead-end: Docker won't allow mount: https://tools.taskcluster.net/groups/CqfVCTZIT3usOxv3oNOGqQ/tasks/CqfVCTZIT3usOxv3oNOGqQ/runs/0/logs/public%2Flogs%2Flive.log#L857
lissyx
on 24 Apr 2018
Let me comment your "payload" in multiple lines
pacman --noconfirm -Syyu
pacman --noconfirm -S --needed git devtools
# Okay I missunderstood why you added a new user, but it might be correct, as you should not start devtools (extra-x64build) as root.
adduser --system --home /home/build-user build-user
cd /home/build-user/
# What is this used for? Debugging?
echo -e \"#!/bin/bash\\nset -xe\\n env
id
git clone --quiet https://github.com/lissyx/DeepSpeech.git ~/DeepSpeech/ds/
cd ~/DeepSpeech/ds
# I am not sure what this command does. It does a checkout but redirects it into a script!? Why are you dping this?
git checkout --quiet 9bc2d682e5cb17d46b79feeaa1c3515bdb6b5d3d\" > /tmp/clone.sh
chmod +x /tmp/clone.sh
sudo -H -u build-user /bin/bash /tmp/clone.sh
# What is the sense of this true command?
true
# Link to your scripts: https://github.com/mozilla/DeepSpeech/commit/9bc2d682e5cb17d46b79feeaa1c3515bdb6b5d3d
# Those look good so far.
sudo -H -u build-user --preserve-env /bin/bash /home/build-user/DeepSpeech/ds/packages/archlinux/build.sh
sudo -H -u build-user /bin/bash /home/build-user/DeepSpeech/ds/packages/archlinux/package.sh\n
So it should work.
Regarding your 2nd comment:
Hm that's a pity. You could try to run makepkg directly. This is not advices for building clean packages to distribute though. It could work if you always reset the docker image (I am not sure how you handle this, do you destroy it everytime?). However as a quick'ndirty test you could try to run makepkg -sri instead of extra_x64-build.
AtosNicoS
on 24 Apr 2018
@AtosNicoS What you call "non-sense" and others are just leftover because I re-used the template from some other build, it's a quick test :). The docker image should be clean, there is no re-use over each run. I'll give a try to makepkg -sri then :)
lissyx
on 24 Apr 2018
@AtosNicoS Okay after some extra trial / error, I had to make a few changes to the base system and also to your PKGBUILD, but this run should start to build stuff properly: https://tools.taskcluster.net/groups/Jb_S9OnrSjWLQwBOi4Ht4g/tasks/VL_FC8BxSn-1_h6Na2NCTg/runs/0
lissyx
on 24 Apr 2018
@AtosNicoS It built successfully :) https://queue.taskcluster.net/v1/task/VL_FC8BxSn-1_h6Na2NCTg/runs/0/artifacts/public/deepspeech-v0.1.1.r67.gae146d0-1-x86_64.pkg.tar.xz
I tend to think the pkgver variable should be removed in favor of the pkgver function is that right ?
lissyx
on 24 Apr 2018
Great news!
The pkgver variable gets replaced and then updated by the pkgver function. In our case it is more or less useless, as you always reset the docker container. I think it is still mandatory to specify a pkgver variable. Just keep it as it is, or set it to the latest version where you changes the PKGBUILD.
Have you tried the compiled binary? It works, but it is still super slow, even on my i7. It uses only a single CPU core to calculate the result.
2018-04-25 08:14:09.091573: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA
@AtosNicoS I have not tried that, but since we just pass -O3 it's not surprising :-). I'd like to have pkgver really match the current git tag, should I be generating the PKGBUILD file to handle that or can we do something with the pkgver function ?
Would you be willing to take ownership of that to have PKGBUILD landed ? Or should you just do a PR against @stes's repo ?
lissyx
on 25 Apr 2018
Note: I am the same person as @NicoHood , just at work, so you dont get confused. I am doing this mainly at work but i am also interested to use and package it for ArchLinux in my free time.
I have not tried that, but since we just pass -O3 it's not surprising :-).
What is not surprising? That it is not using multiple cores?
I'd like to have pkgver really match the current git tag, should I be generating the PKGBUILD file to handle that or can we do something with the pkgver function ?
When you build the package the pkgver() function gets called and automatically updates the pkgver variable of the PKGBUILD. However if you delete the docker container afterwards it gets discarded. It does not really matter what version the pkgver variable has, as it gets replaced anyways.
Beside this, this package is a deepspeech-git package actually. This is only for testing purposes, to test the latest master branch. If you really want to package deepspeech you build against a fixed tag. Thatswhy I was requesting prereleases. In this case the pkgver is fixed (no function) and download a .tar file from the github tag and builds that. Everyone else should be able to reproduce this package then, as -git packages change too fast and might break.
Would you be willing to take ownership of that to have PKGBUILD landed ? Or should you just do a PR against @stes's repo ?
We will use the proper way of distributing packages, the AUR (Arch Linux User Repository). It will be those two packages:
https://aur.archlinux.org/packages/deepspeech/
https://aur.archlinux.org/packages/deepspeech-git/
The first one would normally be based on 0.1.1 . However I was unable to build that for archlinux, that's why I am waiting for the next version. In the meantime we can use the -git package and propose the changes to the AUR maintainer "onny".
The most important aspects for me are now:
- Use multiple cores/speed up recognition
- Get a package building with a new release (no -git version)
AtosNicoS
on 25 Apr 2018
@AtosNicoS I figured you were the same one, just at work :). Regarding the speed, threading depends on TensorFlow, and it has two levels of threading: intra-op and inter-op, so it deeply depends on the exact op and implementations. I've verified on all our builds, and we do leverage multiple cores, but not over the whole process. So I guess once we verify if -lpthread is actually correctly passed in your build and we enable more optimizations, we should see it kicking-in :).
Regarding the versions, I know, I'm about to work on that, the PSU issues seems to be solved. But still, it might be useful to have the deepspeech-git one. I even plan on following what TensorFlow seems to be doing now, that is, to push alpha / rc versions to repos (PyPI/NPM), so that people can more easily grab them.
lissyx
on 25 Apr 2018
But where would you add -lpthread? Could you modify the PKGBUILD is the way you are building deepspeech? This information is missing in the Readme and I have no idea how to optimize the builds/build it the same way as you do.
AtosNicoS
on 25 Apr 2018
@AtosNicoS In fact, -lpthread should already be added by the tensorflow build files. But you can try and force --linkopt=-lpthread for example, on the bazel build command line. It's not documented, because we had no issue on our side, so I'm just trying to guess while helping you.
lissyx
on 25 Apr 2018
@AtosNicoS Okay, giving a try by enabling more optimizations: https://tools.taskcluster.net/groups/MaHPfnchSjiWuxBmJfJh_w/tasks/HojdsHLXRWWqyr1i-MRm5g/details
lissyx
on 25 Apr 2018
@AtosNicoS This one should have more optimization enabled :) https://queue.taskcluster.net/v1/task/HojdsHLXRWWqyr1i-MRm5g/runs/0/artifacts/public/deepspeech-v0.1.1.r67.gae146d0-1-x86_64.pkg.tar.xz
lissyx
on 25 Apr 2018
I tried yours package, but it still only uses a single CPU core. I also tested the precompiled binary under ubuntu 17.10 which also uses a single core. Have you verified that its working on your PC?
AtosNicoS
on 26 Apr 2018
@AtosNicoS I just re-checked, also with latest master, ubuntu 17.10, and I do see several threads created and running during inference. https://index.taskcluster.net/v1/task/project.deepspeech.deepspeech.native_client.master.cpu/artifacts/public/native_client.tar.xz How do you check on your side? I'm taking a look at htop during inference.
lissyx
on 26 Apr 2018
TF_CPP_MIN_VLOG_LEVEL=2 ./deepspeech ../models/output_graph.pbmm ../models/alphabet.txt ../audio/ -t 2>&1 | grep -i thread
2018-04-26 08:56:23.173155: I tensorflow/core/common_runtime/local_device.cc:40] Local device intra op parallelism threads: 8
2018-04-26 08:56:23.173424: I tensorflow/core/common_runtime/direct_session.cc:82] Direct session inter op parallelism threads: 8
I get the same output, but from the gnome system monitor I can see that only one core is used. And it takes quite a long time to calculate:
TF_CPP_MIN_VLOG_LEVEL=2 deepspeech output_graph.pb alphabet.txt lm.binary trie test.wav -t 2>&1 | grep -i thread
2018-04-26 09:54:48.800322: I tensorflow/core/common_runtime/local_device.cc:40] Local device intra op parallelism threads: 8
2018-04-26 09:54:48.800603: I tensorflow/core/common_runtime/direct_session.cc:82] Direct session inter op parallelism threads: 8

AtosNicoS
on 26 Apr 2018
@AtosNicoS Can you give a check with htop as well ? What are your system specs and how "quite a long time" is ?
lissyx
on 26 Apr 2018
Same with htop (Arch Linux):

My system is a Fujitsu P957 Desktop with the latest i7 7700, 32GB ram and SSD. I am either running it bare metal or inside a VM from windows (I am switching back and forth, but it also happens on bare metal). Details about the PC:
http://www.fujitsu.com/de/products/computing/pc/desktops/esprimo-p957-e94/
It takes 14 seconds to decode a 3s sound file inside the VM. Similar measures for bare metal. I used this model: https://github.com/ynop/deepspeech-german I will try the 'official' deepspeech model, but from my previous experiences I think it will not differ in any way. Edit: Also only uses 1 core, but is faster. It only takes 8 seconds to decode.
I noticed the same behavior on my (completely independant) private Fujitsu E744 Laptop with a slightly slower i7 CPU.
AtosNicoS
on 26 Apr 2018
@AtosNicoS Okay, clearly, 14 secs for 3 secs of audio on an i7-7700 is not good. Since it's slow, can you htop -p $(pidof deepspeech) ? We should be able to see the threads for sure.
Can you also ldd deepspeech to make sure it's picking up libpthread ?
lissyx
on 26 Apr 2018

$ ldd /usr/bin/deepspeech
linux-vdso.so.1 (0x00007ffff5f70000)
libdeepspeech.so => /usr/lib/libdeepspeech.so (0x00007f580c7bf000)
libdeepspeech_utils.so => /usr/lib/libdeepspeech_utils.so (0x00007f580e937000)
libsox.so.3 => /usr/lib/libsox.so.3 (0x00007f580c535000)
libstdc++.so.6 => /usr/lib/libstdc++.so.6 (0x00007f580c1ae000)
libm.so.6 => /usr/lib/libm.so.6 (0x00007f580be1a000)
libgcc_s.so.1 => /usr/lib/libgcc_s.so.1 (0x00007f580bc03000)
libc.so.6 => /usr/lib/libc.so.6 (0x00007f580b848000)
libdl.so.2 => /usr/lib/libdl.so.2 (0x00007f580b644000)
libpthread.so.0 => /usr/lib/libpthread.so.0 (0x00007f580b426000)
/lib64/ld-linux-x86-64.so.2 => /usr/lib64/ld-linux-x86-64.so.2 (0x00007f580e744000)
libltdl.so.7 => /usr/lib/libltdl.so.7 (0x00007f580b21c000)
libpng16.so.16 => /usr/lib/libpng16.so.16 (0x00007f580afe6000)
libz.so.1 => /usr/lib/libz.so.1 (0x00007f580adcf000)
libmagic.so.1 => /usr/lib/libmagic.so.1 (0x00007f580abad000)
libgsm.so.1 => /usr/lib/libgsm.so.1 (0x00007f580a9a1000)
libgomp.so.1 => /usr/lib/libgomp.so.1 (0x00007f580a773000)
So there are threads, and they are running ?! Can you try without the language model ?
lissyx
on 26 Apr 2018
I removed the lm.binary and trie from the command line and the german model now finishes instant and the us model takes about 5 seconds now. It looks like its multithreading now, but the CPU overall is still not at 100%.
AtosNicoS
on 26 Apr 2018
@AtosNicoS Well, as I said, we don't directly control the level of parallelism, it depends on the tensorflow ops themselves. I'm surprised the KenLM language model takes that much of time for you, but at least it means we have something comparable now.
lissyx
on 26 Apr 2018
@AtosNicoS I've pushed a first tentative 0.2.0-alpha.0 tag now that we have simplified that process :)
lissyx
on 28 Apr 2018
Thanks! I got it building using this PKGBUILD:
pkgname=deepspeech
_pkgname=DeepSpeech
pkgver=0.2.0_alpha.3
pkgrel=1
pkgdesc="A TensorFlow implementation of Baidu's DeepSpeech architecture"
arch=('x86_64')
url="https://github.com/mozilla/DeepSpeech"
license=('MPL2')
makedepends=('bazel' 'python-numpy' 'python-pip' 'python-wheel' 'python-setuptools' 'git')
depends=('python-tensorflow' 'python-scipy' 'sox')
source=("${pkgname}-${pkgver}.tar.gz::https://github.com/mozilla/DeepSpeech/archive/v${pkgver//_/-}.tar.gz"
"git+https://github.com/mozilla/tensorflow.git#branch=r1.6"
17508.patch)
sha512sums=('9ee15be1b22a1d327c97f8e94b5b0e3b779c574a150ed1bd97b0d7ccbe583f625df9014debae4daa238dbfcacf4bc1929e4722349055038c8020744a8194d6d3'
'SKIP'
'18e3b22e956bdd759480d2e94212eb83d6a59381f34bbc7154cadbf7f42686c2f703cc61f81e6ebeaf1da8dc5de8472e5afc6012abb1720cadb68607fba8e8e1')
prepare()
{
patch -Np1 -i ${srcdir}/17508.patch -d tensorflow
cd "$srcdir/tensorflow"
# These environment variables influence the behavior of the configure call below.
export PYTHON_BIN_PATH=/usr/bin/python
export USE_DEFAULT_PYTHON_LIB_PATH=1
export TF_NEED_JEMALLOC=1
export TF_NEED_KAFKA=0
export TF_NEED_OPENCL_SYCL=0
export TF_NEED_GCP=0
export TF_NEED_HDFS=0
export TF_NEED_S3=0
export TF_ENABLE_XLA=1
export TF_NEED_GDR=0
export TF_NEED_VERBS=0
export TF_NEED_OPENCL=0
export TF_NEED_MPI=0
export TF_NEED_TENSORRT=0
export TF_SET_ANDROID_WORKSPACE=0
ln -sf "../${_pkgname}-${pkgver//_/-}/native_client" ./
}
build() {
cd "$srcdir/tensorflow"
export CC_OPT_FLAGS="-march=x86-64"
export TF_NEED_CUDA=0
./configure
bazel build -c opt --copt=-mtune=generic --copt=-march=x86-64 --copt=-msse --copt=-msse2 --copt=-msse3 --copt=-msse4.1 --copt=-msse4.2 --copt=-mavx --copt="-D_GLIBCXX_USE_CXX11_ABI=0" //native_client:libctc_decoder_with_kenlm.so
bazel build --config=monolithic -c opt --copt=-mtune=generic --copt=-march=x86-64 --copt=-msse --copt=-msse2 --copt=-msse3 --copt=-msse4.1 --copt=-msse4.2 --copt=-mavx --copt="-D_GLIBCXX_USE_CXX11_ABI=0" --copt=-fvisibility=hidden //native_client:libdeepspeech.so //native_client:deepspeech_utils //native_client:generate_trie
cd "${srcdir}/${_pkgname}-${pkgver//_/-}/native_client"
make deepspeech
}
package() {
cd "${srcdir}/${_pkgname}-${pkgver//_/-}/native_client"
PREFIX=${pkgdir}/usr make install
}
Any reason why you removed -O3?
I analyzed the deepspeech output now with a predefined "grammar" as a quick test and got pretty good results: https://github.com/mozilla/DeepSpeech/issues/1290#issuecomment-386217745
AtosNicoS
on 3 May 2018
@AtosNicoS Thanks! No good reason, we don't have the flag actually on TaskCluster, I'm not sure there's so much difference between -Ox, what's likely more important is the optimizations such as SSE, AVX, but we should maybe have a look?
I'm also wondering if we should investigate this threading stuff with the language model: a quick look shows it should leverage multiple CPUs, but I'm now unsure if we do it properly :)
lissyx
on 3 May 2018
The multithreading stuff should be investigated more, of course.
I want to share my recent PKGBUILD, now with python bindings. Please have a look at it, if I missed anything.
pkgbase=deepspeech
pkgname=('deepspeech' 'python-deepspeech')
_pkgname=DeepSpeech
pkgver=0.2.0_alpha.3
pkgrel=1
pkgdesc="A TensorFlow implementation of Baidu's DeepSpeech architecture"
arch=('x86_64')
url="https://github.com/mozilla/DeepSpeech"
license=('MPL2')
makedepends=('bazel' 'python-numpy' 'python-pip' 'python-wheel' 'python-setuptools' 'git' 'sox' 'swig')
source=("${pkgname}-${pkgver}.tar.gz::https://github.com/mozilla/DeepSpeech/archive/v${pkgver//_/-}.tar.gz"
"git+https://github.com/mozilla/tensorflow.git#branch=r1.6"
17508.patch)
sha512sums=('9ee15be1b22a1d327c97f8e94b5b0e3b779c574a150ed1bd97b0d7ccbe583f625df9014debae4daa238dbfcacf4bc1929e4722349055038c8020744a8194d6d3'
'SKIP'
'18e3b22e956bdd759480d2e94212eb83d6a59381f34bbc7154cadbf7f42686c2f703cc61f81e6ebeaf1da8dc5de8472e5afc6012abb1720cadb68607fba8e8e1')
prepare()
{
patch -Np1 -i ${srcdir}/17508.patch -d tensorflow
cd "$srcdir/tensorflow"
# These environment variables influence the behavior of the configure call below.
export PYTHON_BIN_PATH=/usr/bin/python
export USE_DEFAULT_PYTHON_LIB_PATH=1
export TF_NEED_JEMALLOC=1
export TF_NEED_KAFKA=0
export TF_NEED_OPENCL_SYCL=0
export TF_NEED_GCP=0
export TF_NEED_HDFS=0
export TF_NEED_S3=0
export TF_ENABLE_XLA=1
export TF_NEED_GDR=0
export TF_NEED_VERBS=0
export TF_NEED_OPENCL=0
export TF_NEED_MPI=0
export TF_NEED_TENSORRT=0
export TF_SET_ANDROID_WORKSPACE=0
ln -sf "../${_pkgname}-${pkgver//_/-}/native_client" ./
}
build() {
cd "$srcdir/tensorflow"
export CC_OPT_FLAGS="-march=x86-64"
export TF_NEED_CUDA=0
./configure
bazel build -c opt --copt=-mtune=generic --copt=-march=x86-64 --copt=-msse --copt=-msse2 --copt=-msse3 --copt=-msse4.1 --copt=-msse4.2 --copt=-mavx --copt="-D_GLIBCXX_USE_CXX11_ABI=0" //native_client:libctc_decoder_with_kenlm.so
bazel build --config=monolithic -c opt --copt=-mtune=generic --copt=-march=x86-64 --copt=-msse --copt=-msse2 --copt=-msse3 --copt=-msse4.1 --copt=-msse4.2 --copt=-mavx --copt="-D_GLIBCXX_USE_CXX11_ABI=0" --copt=-fvisibility=hidden //native_client:libdeepspeech.so //native_client:deepspeech_utils //native_client:generate_trie
cd "${srcdir}/${_pkgname}-${pkgver//_/-}/native_client"
make deepspeech
make bindings
}
package_deepspeech() {
depends=('sox')
cd "${srcdir}/${_pkgname}-${pkgver//_/-}/native_client"
PREFIX=${pkgdir}/usr make install
}
package_python-deepspeech() {
pkgdesc="DeepSpeech Python bindings"
depends=('deepspeech' 'python' 'python-scipy')
cd "${srcdir}/${_pkgname}-${pkgver//_/-}/native_client"
PIP_CONFIG_FILE=/dev/null pip install --isolated --root="$pkgdir" --ignore-installed --no-deps dist/deepspeech*.whl
# Reuse deepspeech .so files
rm "$pkgdir/usr/bin/deepspeech"
rm -rf "$pkgdir/usr/lib/python3.6/site-packages/deepspeech/lib"
ln -s /usr/lib "$pkgdir/usr/lib/python3.6/site-packages/deepspeech/lib"
}
Thanks! giving it a try: https://tools.taskcluster.net/groups/acc0nK5mRdqWER8gmF2VCg
lissyx
on 3 May 2018
@AtosNicoS It seems to have built properly, but I cannot figure out where the python wheel has been produced?
lissyx
on 3 May 2018
@lissyx There is no python wheel package, you will produce 2 Archlinux packages ending both with .tar.xz. For ArchLinux we do not want wheel packages, as pip is not the preferred way to install packages. You rather build the package and install it yourself. pip is just a software which automates the process for distributions that dont provide such python packages. For Archlinux writing packages is extremely simple, so you normally write a quick PKGBUILD whenever possible.
Currently I am building the wheel package, as the makefile does not give me any other option and then I install it again with pip into the package. However this is still not perfect, it would be better to use setuptools to install the package directly.
Here is an example of how its normally handled:
https://git.archlinux.org/svntogit/community.git/tree/trunk/PKGBUILD?h=packages/python-gitpython
https://github.com/gitpython-developers/GitPython/blob/master/setup.py
AtosNicoS
on 4 May 2018
@AtosNicoS We use setuptools, so I don't know what should be changed for your usecase ? Anyway, wheel or pkg.tar.xz, I cannot figure out from your PKGBUILD where this is being produced, to be able to expose it as an artifact :)
lissyx
on 4 May 2018
@AtosNicoS Re-verifying the thing about threads and KenLM, it looks like there's nothing wrong:
- using the language model should not have a big hit on performances, all the measures we did, I'm able to confirm locally, show the time is orders of magnitude lower than the time for the whole inference
- the threading support exists only for filtering and estimations, but not for querying.
lissyx
on 4 May 2018
@AtosNicoS We use setuptools
I missed that. I will try to use setuptools then instead. sorry and thanks for the hint!
@AtosNicoS Re-verifying the thing about threads and KenLM, it looks like there's nothing wrong:
I try to publish the package on AUR over the weekend. Maybe other ArchLinux members can test that as well and report more feedback. Thanks for looking into it. :)
AtosNicoS
on 4 May 2018
I checked building with setuptools directly. It seems you are setting a lot of helper variables in the makefile, so we have to place the install calls into the makefile, not the PKGBUILD. But I want to avoid creating a wheel package and then installing it. It is just a useless step (for non pip users/distribution users).
Old: Make/build -> wheel package -> install via pip -> Distribution package
New: Make/build -> install via setuptools directly -> Distribution package
Some of my finding below:
When creating the temp directory you could use mkdir -p. Otherwise it will fail if you run make bindings twice. Note: I am not 100% sure if this is correct or if I missed anything here.
https://github.com/mozilla/DeepSpeech/blob/4e53683c43443d6c5335ad70e5e2801be395cebb/native_client/definitions.mk#L107
Same for this rm command. Use -f to ignore files that do not exist: Note: I am not 100% sure if this is correct or if I missed anything here.
https://github.com/mozilla/DeepSpeech/blob/4e53683c43443d6c5335ad70e5e2801be395cebb/native_client/Makefile#L43
The question I am asking myself is why you remove the .o files. Are they even packaged? Shouldnt they get removed earlier, directly inside the make bindings-build target?
I would remove this pip install command:
https://github.com/mozilla/DeepSpeech/blob/4e53683c43443d6c5335ad70e5e2801be395cebb/native_client/Makefile#L34
Dependencies should be listed in the readme. You dont need pip to install dependency packages. I consider packages via pip a potential security risk and prefer distribution packages whenever possible (as those can verify gpg signatures if available). The person who build should install packages the way he prefers, dont use pip directly. For example in the ArchLinux PKGBUILD we would specify the dependencies directly and remove pip completely.
I am thinking of adding another target to install the bindings directly instead of generating a wheel package first:
bindings-install: bindings-build MANIFEST.in
cat MANIFEST.in
rm -f temp_build/python/*_wrap.o
AS=$(AS) CC=$(CC) CXX=$(CXX) LD=$(LD) CFLAGS="$(CFLAGS)" LDFLAGS="$(LDFLAGS_NEEDED) $(RPATH_PYTHON)" MODEL_LDFLAGS="$(LDFLAGS_DIRS)" UTILS_LDFLAGS="-L${TFDIR}/bazel-bin/native_client" MODEL_LIBS="$(LIBS)" $(PYTHON_PATH) $(NUMPY_INCLUDE) python ./setup.py install --skip-build --optimize=1 $(SETUP_FLAGS)
You can use the command like this then:
# General installation, system wide (not recommended from my point of view)
sudo make bindings-install
# Install into a local directory as non-root user:
SETUP_FLAGS="--root=mypackagedir" make bindings-install
# More specific inside an ArchLinux PKGBUILD
SETUP_FLAGS="--root=${pkgdir}" make bindings-install
@AtosNicoS Could you take that to Discourse? It's really deriving from the topic and I always found Github a pain to use for more discussions-oriented stuff, especialy about quoting.
lissyx
on 4 May 2018
@AtosNicoS Proper python package: https://queue.taskcluster.net/v1/task/N1oZy5VARjCTFM4FBKB67Q/runs/0/artifacts/public/python-deepspeech-0.2.0_alpha.3-1-x86_64.pkg.tar.xz
lissyx
on 4 May 2018
I tried the 0.1.1 model from the github release. It uses a single CPU core and takes 7 seconds to parse a simple audio file. I also used the audio provided by mozilla from the github release. Can you please also test this on your machine?
$ date && deepspeech model/us/output_graph.pb model/us/alphabet.txt model/us/lm.binary model/us/trie 2830-3980-0043.wav && date
Sat May 5 11:26:47 CEST 2018
TensorFlow: b'v1.6.0-16-gc346f2c8fd'
DeepSpeech: unknown
Warning: reading entire model file into memory. Transform model file into an mmapped graph to reduce heap usage.
2018-05-05 11:26:47.679101: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
experience proves this
Sat May 5 11:26:54 CEST 2018
$ date && deepspeech_python model/us/output_graph.pb 2830-3980-0043.wav model/us/alphabet.txt model/us/lm.binary model/us/trie && date
Sat May 5 11:30:22 CEST 2018
Loading model from file model/us/output_graph.pb
2018-05-05 11:30:22.877855: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Loaded model in 0.309s.
Loading language model from files model/us/lm.binary model/us/trie
Loaded language model in 2.115s.
Running inference.
experience proves this
Inference took 5.351s for 1.975s audio file.
Sat May 5 11:30:30 CEST 2018
As another error I get the following message with the python deepspeech binary on my personal laptop:
$ date && deepspeech_python model/de/output_graph.pb 2830-3980-0043.wav model/de/alphabet.txt && date
Sat May 5 11:31:39 CEST 2018
Loading model from file model/de/output_graph.pb
2018-05-05 11:31:39.524129: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Loaded model in 0.063s.
Running inference.
2018-05-05 11:31:39.665658: E tensorflow/core/framework/op_segment.cc:53] Create kernel failed: Invalid argument: NodeDef mentions attr 'identical_element_shapes' not in Op<name=TensorArrayV3; signature=size:int32 -> handle:resource, flow:float; attr=dtype:type; attr=element_shape:shape,default=<unknown>; attr=dynamic_size:bool,default=false; attr=clear_after_read:bool,default=true; attr=tensor_array_name:string,default=""; is_stateful=true>; NodeDef: bidirectional_rnn/bw/bw/TensorArray_1 = TensorArrayV3[clear_after_read=true, dtype=DT_FLOAT, dynamic_size=false, element_shape=[?,750], identical_element_shapes=true, tensor_array_name="bidirectional_rnn/bw/bw/dynamic_rnn/input_0", _device="/job:localhost/replica:0/task:0/device:CPU:0"](bidirectional_rnn/bw/bw/TensorArrayUnstack/strided_slice). (Check whether your GraphDef-interpreting binary is up to date with your GraphDef-generating binary.).
2018-05-05 11:31:39.665717: E tensorflow/core/common_runtime/executor.cc:643] Executor failed to create kernel. Invalid argument: NodeDef mentions attr 'identical_element_shapes' not in Op<name=TensorArrayV3; signature=size:int32 -> handle:resource, flow:float; attr=dtype:type; attr=element_shape:shape,default=<unknown>; attr=dynamic_size:bool,default=false; attr=clear_after_read:bool,default=true; attr=tensor_array_name:string,default=""; is_stateful=true>; NodeDef: bidirectional_rnn/bw/bw/TensorArray_1 = TensorArrayV3[clear_after_read=true, dtype=DT_FLOAT, dynamic_size=false, element_shape=[?,750], identical_element_shapes=true, tensor_array_name="bidirectional_rnn/bw/bw/dynamic_rnn/input_0", _device="/job:localhost/replica:0/task:0/device:CPU:0"](bidirectional_rnn/bw/bw/TensorArrayUnstack/strided_slice). (Check whether your GraphDef-interpreting binary is up to date with your GraphDef-generating binary.).
[[Node: bidirectional_rnn/bw/bw/TensorArray_1 = TensorArrayV3[clear_after_read=true, dtype=DT_FLOAT, dynamic_size=false, element_shape=[?,750], identical_element_shapes=true, tensor_array_name="bidirectional_rnn/bw/bw/dynamic_rnn/input_0", _device="/job:localhost/replica:0/task:0/device:CPU:0"](bidirectional_rnn/bw/bw/TensorArrayUnstack/strided_slice)]]
Error running session: Invalid argument: NodeDef mentions attr 'identical_element_shapes' not in Op<name=TensorArrayV3; signature=size:int32 -> handle:resource, flow:float; attr=dtype:type; attr=element_shape:shape,default=<unknown>; attr=dynamic_size:bool,default=false; attr=clear_after_read:bool,default=true; attr=tensor_array_name:string,default=""; is_stateful=true>; NodeDef: bidirectional_rnn/bw/bw/TensorArray_1 = TensorArrayV3[clear_after_read=true, dtype=DT_FLOAT, dynamic_size=false, element_shape=[?,750], identical_element_shapes=true, tensor_array_name="bidirectional_rnn/bw/bw/dynamic_rnn/input_0", _device="/job:localhost/replica:0/task:0/device:CPU:0"](bidirectional_rnn/bw/bw/TensorArrayUnstack/strided_slice). (Check whether your GraphDef-interpreting binary is up to date with your GraphDef-generating binary.).
[[Node: bidirectional_rnn/bw/bw/TensorArray_1 = TensorArrayV3[clear_after_read=true, dtype=DT_FLOAT, dynamic_size=false, element_shape=[?,750], identical_element_shapes=true, tensor_array_name="bidirectional_rnn/bw/bw/dynamic_rnn/input_0", _device="/job:localhost/replica:0/task:0/device:CPU:0"](bidirectional_rnn/bw/bw/TensorArrayUnstack/strided_slice)]]
None
Inference took 0.080s for 1.975s audio file.
Sat May 5 11:31:39 CEST 2018
I am using this german language model. The english provides by mozilla works properly. But for some reason the "normal" native client without python bindings works properly for this model on my machine.
The python tool and the native tool have different order of command line parameters. Those should be made equal.
NicoHood
on 5 May 2018
@NicoHood All the tests I could do regarding threading shows it works as expected. The error you have is because you trained with TensorFlow >= r1.5 and you used binaries v0.1.1 (TensorFlow r1.4) for inference. Order of the parameter is the same in all binaries, but it changed since 0.1.1
lissyx
on 5 May 2018
@NicoHood Please verify threading with TF_CPP_MIN_VLOG_LEVEL=2, as documented earlier.
lissyx
on 5 May 2018
alex@portable-alex:~/tmp/deepspeech/cpu-0.1.1$ wget https://index.taskcluster.net/v1/task/project.deepspeech.deepspeech.native_client.v0.1.1.cpu/artifacts/public/native_client.tar.xz && tar xf native_client.tar.xz
--2018-05-05 14:07:46-- https://index.taskcluster.net/v1/task/project.deepspeech.deepspeech.native_client.v0.1.1.cpu/artifacts/public/native_client.tar.xz
Résolution de index.taskcluster.net (index.taskcluster.net)… 54.243.65.240, 54.225.111.188, 23.23.146.2
Connexion à index.taskcluster.net (index.taskcluster.net)|54.243.65.240|:443… connecté.
requête HTTP transmise, en attente de la réponse… 303 See Other
Emplacement : https://queue.taskcluster.net/v1/task/bzVx8U5xSgSUisIqdsLFmA/artifacts/public%2Fnative_client.tar.xz [suivant]
--2018-05-05 14:07:47-- https://queue.taskcluster.net/v1/task/bzVx8U5xSgSUisIqdsLFmA/artifacts/public%2Fnative_client.tar.xz
Résolution de queue.taskcluster.net (queue.taskcluster.net)… 54.243.65.240, 54.225.111.188, 23.23.146.2
Connexion à queue.taskcluster.net (queue.taskcluster.net)|54.243.65.240|:443… connecté.
requête HTTP transmise, en attente de la réponse… 303 See Other
Emplacement : https://taskcluster-artifacts.net/bzVx8U5xSgSUisIqdsLFmA/0/public/native_client.tar.xz [suivant]
--2018-05-05 14:07:48-- https://taskcluster-artifacts.net/bzVx8U5xSgSUisIqdsLFmA/0/public/native_client.tar.xz
Résolution de taskcluster-artifacts.net (taskcluster-artifacts.net)… 54.230.76.189
Connexion à taskcluster-artifacts.net (taskcluster-artifacts.net)|54.230.76.189|:443… connecté.
requête HTTP transmise, en attente de la réponse… 200 OK
Taille : 10187244 (9,7M) [application/x-xz]
Enregistre : «native_client.tar.xz»
native_client.tar.xz 100%[=======================================================================================================================================================================================================>] 9,71M 1,89MB/s ds 6,4s
2018-05-05 14:07:55 (1,51 MB/s) - «native_client.tar.xz» enregistré [10187244/10187244]
alex@portable-alex:~/tmp/deepspeech/cpu-0.1.1$ ./deepspeech ../models/output_graph.pb ../audio/2830-3980-0043.wav ../models/alphabet.txt -t
2018-05-05 14:08:42.096843: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
experience proves tis
cpu_time_overall=5.35120 cpu_time_mfcc=0.00319 cpu_time_infer=5.34801
alex@portable-alex:~/tmp/deepspeech/cpu-0.1.1$ ./deepspeech ../models/output_graph.pb ../audio/2830-3980-0043.wav ../models/alphabet.txt ../models/lm.binary ../models/trie -t
2018-05-05 14:08:58.059388: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
experience proves this
cpu_time_overall=5.51043 cpu_time_mfcc=0.00266 cpu_time_infer=5.50778
alex@portable-alex:~/tmp/deepspeech/cpu-0.1.1$ TF_CPP_MIN_VLOG_LEVEL=2 ./deepspeech ../models/output_graph.pb ../audio/2830-3980-0043.wav ../models/alphabet.txt -t 2>&1 | grep -i thread
2018-05-05 14:09:20.403349: I tensorflow/core/common_runtime/local_device.cc:40] Local device intra op parallelism threads: 8
2018-05-05 14:09:20.403595: I tensorflow/core/common_runtime/direct_session.cc:85] Direct session inter op parallelism threads: 8
And using time:
alex@portable-alex:~/tmp/deepspeech/cpu-0.1.1$ time ./deepspeech ../models/output_graph.pb ../audio/2830-3980-0043.wav ../models/alphabet.txt -t
2018-05-05 14:11:26.084127: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
experience proves tis
cpu_time_overall=5.45314 cpu_time_mfcc=0.00314 cpu_time_infer=5.44999
real 0m3,791s
user 0m4,865s
sys 0m0,957s

lissyx
on 5 May 2018
@AtosNicoS @NicoHood You might be interested in https://github.com/mozfr/besogne/wiki/Common-Voice-Fr :)
lissyx
on 7 May 2018
With alpha 9 I get the error:
$ make deepspeech
c++ -std=c++11 -o deepspeech `pkg-config --cflags sox` client.cc -Wl,--no-as-needed -Wl,-rpath,\$ORIGIN -L/home/arch/hackallthethings/tensorflow/bazel-bin/native_client -ldeepspeech `pkg-config --libs sox`
/usr/bin/ld: /tmp/cc04sVn3.o: in function `PrintHelp(char const*)':
client.cc:(.text+0x41): undefined reference to `DS_PrintVersions()'
/usr/bin/ld: /tmp/cc04sVn3.o: in function `ProcessArgs(int, char**)':
client.cc:(.text+0x199): undefined reference to `DS_PrintVersions()'
/usr/bin/ld: /tmp/cc04sVn3.o: in function `LocalDsSTT(ModelState*, short const*, unsigned long, int)':
client.cc:(.text+0x255): undefined reference to `DS_SpeechToText(ModelState*, short const*, unsigned int, unsigned int)'
/usr/bin/ld: /tmp/cc04sVn3.o: in function `main':
client.cc:(.text+0x95d): undefined reference to `DS_CreateModel(char const*, unsigned int, unsigned int, char const*, unsigned int, ModelState**)'
/usr/bin/ld: client.cc:(.text+0x9e2): undefined reference to `DS_EnableDecoderWithLM(ModelState*, char const*, char const*, char const*, float, float)'
/usr/bin/ld: client.cc:(.text+0xd06): undefined reference to `DS_DestroyModel(ModelState*)'
/usr/bin/ld: /home/arch/hackallthethings/tensorflow/bazel-bin/native_client/libdeepspeech.so: undefined reference to `DeepSpeech::audioToInputVector(short const*, unsigned int, int, int, int, float**, int*, int*)'
collect2: error: ld returned 1 exit status
make: *** [Makefile:22: deepspeech] Error 1
my PKGBUILD:
# Maintainer: NicoHood <archlinux {cat} nicohood {dog} de>
# PGP ID: 97312D5EB9D7AE7D0BD4307351DAE9B7C1AE9161
# Contributor: Jonas Heinrich <[email protected]>
pkgbase=deepspeech
pkgname=('deepspeech' 'python-deepspeech')
_pkgname=DeepSpeech
pkgver=0.2.0_alpha.9
pkgrel=1
pkgdesc="A TensorFlow implementation of Baidu's DeepSpeech architecture"
arch=('x86_64')
url="https://github.com/mozilla/DeepSpeech"
license=('MPL2')
makedepends=('bazel' 'python-numpy' 'python-scipy' 'python-pip' 'python-wheel' 'python-setuptools' 'git' 'sox' 'swig')
source=("${pkgname}-${pkgver}.tar.gz::https://github.com/mozilla/DeepSpeech/archive/v${pkgver//_/-}.tar.gz"
"git+https://github.com/mozilla/tensorflow.git#branch=r1.6"
# TODO Add speech model as split package
#"https://github.com/mozilla/DeepSpeech/releases/download/v0.1.1/deepspeech-0.1.1-models.tar.gz"
17508.patch)
sha512sums=('139a357e4e5bdcbe548be5bd1e096c0c3d4cdbf375744172622187bc25b04d7e166632c0c581f483dbb8ce1180de4e465f5a0ef383a9daab1965f99357de4679'
'SKIP'
'18e3b22e956bdd759480d2e94212eb83d6a59381f34bbc7154cadbf7f42686c2f703cc61f81e6ebeaf1da8dc5de8472e5afc6012abb1720cadb68607fba8e8e1')
prepare()
{
patch -Np1 -i ${srcdir}/17508.patch -d tensorflow
cd "$srcdir/tensorflow"
# These environment variables influence the behavior of the configure call below.
export PYTHON_BIN_PATH=/usr/bin/python
export USE_DEFAULT_PYTHON_LIB_PATH=1
export TF_NEED_JEMALLOC=1
export TF_NEED_KAFKA=0
export TF_NEED_OPENCL_SYCL=0
export TF_NEED_GCP=0
export TF_NEED_HDFS=0
export TF_NEED_S3=0
export TF_ENABLE_XLA=1
export TF_NEED_GDR=0
export TF_NEED_VERBS=0
export TF_NEED_OPENCL=0
export TF_NEED_MPI=0
export TF_NEED_TENSORRT=0
export TF_SET_ANDROID_WORKSPACE=0
ln -sf "../${_pkgname}-${pkgver//_/-}/native_client" ./
}
build() {
cd "$srcdir/tensorflow"
export CC_OPT_FLAGS="-march=x86-64"
export TF_NEED_CUDA=0
./configure
bazel build -c opt --copt=-mtune=generic --copt=-march=x86-64 --copt=-msse \
--copt=-msse2 --copt=-msse3 --copt=-msse4.1 --copt=-msse4.2 \
--copt=-mavx --copt="-D_GLIBCXX_USE_CXX11_ABI=0" \
//native_client:libctc_decoder_with_kenlm.so
bazel build --config=monolithic -c opt --copt=-mtune=generic \
--copt=-march=x86-64 --copt=-msse --copt=-msse2 --copt=-msse3 \
--copt=-msse4.1 --copt=-msse4.2 --copt=-mavx \
--copt="-D_GLIBCXX_USE_CXX11_ABI=0" --copt=-fvisibility=hidden \
//native_client:libdeepspeech.so \
//native_client:generate_trie
cd "${srcdir}/${_pkgname}-${pkgver//_/-}/native_client"
make deepspeech
#make bindings
}
package_deepspeech() {
depends=('sox')
cd "${srcdir}/${_pkgname}-${pkgver//_/-}/native_client"
PREFIX=${pkgdir}/usr make install
}
package_python-deepspeech() {
pkgdesc="DeepSpeech Python bindings"
depends=('deepspeech' 'python' 'python-scipy' 'python-numpy')
cd "${srcdir}/${_pkgname}-${pkgver//_/-}/native_client"
#PIP_CONFIG_FILE=/dev/null pip install --isolated --root="$pkgdir" --ignore-installed --no-deps dist/deepspeech*.whl
# Reuse deepspeech .so files
#mv "$pkgdir/usr/bin/deepspeech" "$pkgdir/usr/bin/deepspeech_python"
#rm -rf "$pkgdir/usr/lib/python3.6/site-packages/deepspeech/lib"
#ln -s /usr/lib "$pkgdir/usr/lib/python3.6/site-packages/deepspeech/lib"
}
Any ideas?
Do I need tensorflow 1.6 or 1.7?
NicoHood
on 22 Aug 2018
@NicoHood This feels like improper build of something. Can you ensure there is no stale Bazel cache anywhere? Verify exported symbols from your linkage as well: /home/arch/hackallthethings/tensorflow/bazel-bin/native_client/libdeepspeech.so should export all those DS_PrintVersions() and the others
lissyx
on 22 Aug 2018
It builds now, I did something wrong.
Also, any release date planned yet? Would it be possible for you to release a precompiled language model for the english language? Is there any data from the common voice project available yet (looking out for german)?
NicoHood
on 24 Aug 2018
@NicoHood Please ask that on Discourse. @reuben might know for the date
lissyx
on 24 Aug 2018
I tried the latest 0.2.0 release of Deepspeech and its models. The recognition is still slow, because it only uses a single core. Any idea how to solve it?
Here is the link to the most up to date PKGBUILD I am using:
https://aur.archlinux.org/cgit/aur.git/tree/PKGBUILD?h=deepspeech
NicoHood
on 20 Sep 2018
@NicoHood As you can remember, every reproduction I've ever seen was using all the cores available. Please share output with TF_CPP_MIN_VLOG_LEVEL=2 to check how much parallelism gets in.
lissyx
on 20 Sep 2018
alexandre@serveur:~/tmp/deepspeech-0.2/bin-cpu$ wget https://github.com/mozilla/DeepSpeech/releases/download/v0.2.0/native_client.amd64.cpu.linux.tar.xz
--2018-09-20 17:49:06-- https://github.com/mozilla/DeepSpeech/releases/download/v0.2.0/native_client.amd64.cpu.linux.tar.xz
Résolution de github.com (github.com)… 192.30.253.113, 192.30.253.112
Connexion à github.com (github.com)|192.30.253.113|:443… connecté.
requête HTTP transmise, en attente de la réponse… 302 Found
Emplacement : https://github-production-release-asset-2e65be.s3.amazonaws.com/60273704/34255200-bb7c-11e8-8829-c0fbd1fdcaa9?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20180920%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20180920T154907Z&X-Amz-Expires=300&X-Amz-Signature=ab35e7d412ead739c5a374e775e28dded2e3af6581e2298bb396cb37e086180c&X-Amz-SignedHeaders=host&actor_id=0&response-content-disposition=attachment%3B%20filename%3Dnative_client.amd64.cpu.linux.tar.xz&response-content-type=application%2Foctet-stream [suivant]
--2018-09-20 17:49:07-- https://github-production-release-asset-2e65be.s3.amazonaws.com/60273704/34255200-bb7c-11e8-8829-c0fbd1fdcaa9?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20180920%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20180920T154907Z&X-Amz-Expires=300&X-Amz-Signature=ab35e7d412ead739c5a374e775e28dded2e3af6581e2298bb396cb37e086180c&X-Amz-SignedHeaders=host&actor_id=0&response-content-disposition=attachment%3B%20filename%3Dnative_client.amd64.cpu.linux.tar.xz&response-content-type=application%2Foctet-stream
Résolution de github-production-release-asset-2e65be.s3.amazonaws.com (github-production-release-asset-2e65be.s3.amazonaws.com)… 52.216.133.139
Connexion à github-production-release-asset-2e65be.s3.amazonaws.com (github-production-release-asset-2e65be.s3.amazonaws.com)|52.216.133.139|:443… connecté.
requête HTTP transmise, en attente de la réponse… 200 OK
Taille : 4802992 (4,6M) [application/octet-stream]
Sauvegarde en : « native_client.amd64.cpu.linux.tar.xz »
native_client.amd64.cpu.linux.tar.xz 100%[====================================================================================================================================================================================>] 4,58M 2,22MB/s ds 2,1s
2018-09-20 17:49:09 (2,22 MB/s) — « native_client.amd64.cpu.linux.tar.xz » sauvegardé [4802992/4802992]
alexandre@serveur:~/tmp/deepspeech-0.2/bin-cpu$ tar xf native_client.amd64.cpu.linux.tar.xz
alexandre@serveur:~/tmp/deepspeech-0.2/bin-cpu$ TF_CPP_MIN_VLOG_LEVEL=2 ./deepspeech --model ~/tmp/deepspeech-0.2/models/output_graph.pbmm --alphabet ~/tmp/deepspeech-0.2/models/alphabet.txt --lm ~/tmp/deepspeech-0.2/models/lm.binary --trie ~/tmp/deepspeech-0.2/models/trie --audio ~/tmp/deepspeech-0.2/audio/ -t 2>&1 | grep -i parallel
2018-09-20 17:49:20.090351: I tensorflow/core/common_runtime/local_device.cc:40] Local device intra op parallelism threads: 32
2018-09-20 17:49:20.091385: I tensorflow/core/common_runtime/direct_session.cc:82] Direct session inter op parallelism threads: 32
alexandre@serveur:~/tmp/deepspeech-0.2/bin-cpu$
So I see TensorFlow picking the 32 cores of my CPU.
lissyx
on 20 Sep 2018
@NicoHood Thanks for the AUR link, I guess it means this is indeed packaged now? We should close that issue if that is the case. Then, with proper logging enabled, it'd be great if you could file another issue about that threading issue, because the PKGBUILD seems okay to me, and all of the threading is handled by TensorFlow, and it should rely on pthread kind of automagically (there are a lot of placed in the TensorFlow build system where they force -lpthread).
lissyx
on 20 Sep 2018
TF_CPP_MIN_VLOG_LEVEL=2 deepspeech --model output_graph.pb --alphabet alphabet.txt --lm lm.binary --trie trie --audio test.wav &>log.txt
Output: https://gist.github.com/NicoHood/e797ded67dbad47d7c372dd1450c4f3b
Uses only a single core:
The PKGBUILD is not completed yet, as the python bindings are not yet packaged. I try to solve those issues now and prepare a PR for future versions.
NicoHood
on 20 Sep 2018
Well, according to this log:
2018-09-20 18:18:57.713779: I tensorflow/core/common_runtime/local_device.cc:40] Local device intra op parallelism threads: 8
2018-09-20 18:18:57.714286: I tensorflow/core/common_runtime/direct_session.cc:82] Direct session inter op parallelism threads: 8
Thread are indeed properly used. Your chart does not document a lot of what is each line, but so far, I don't see what can be done.
lissyx
on 20 Sep 2018
@NicoHood Can you share more details on your setup, on how you proceed to compare and what you consider « too slow » ?
lissyx
on 20 Sep 2018
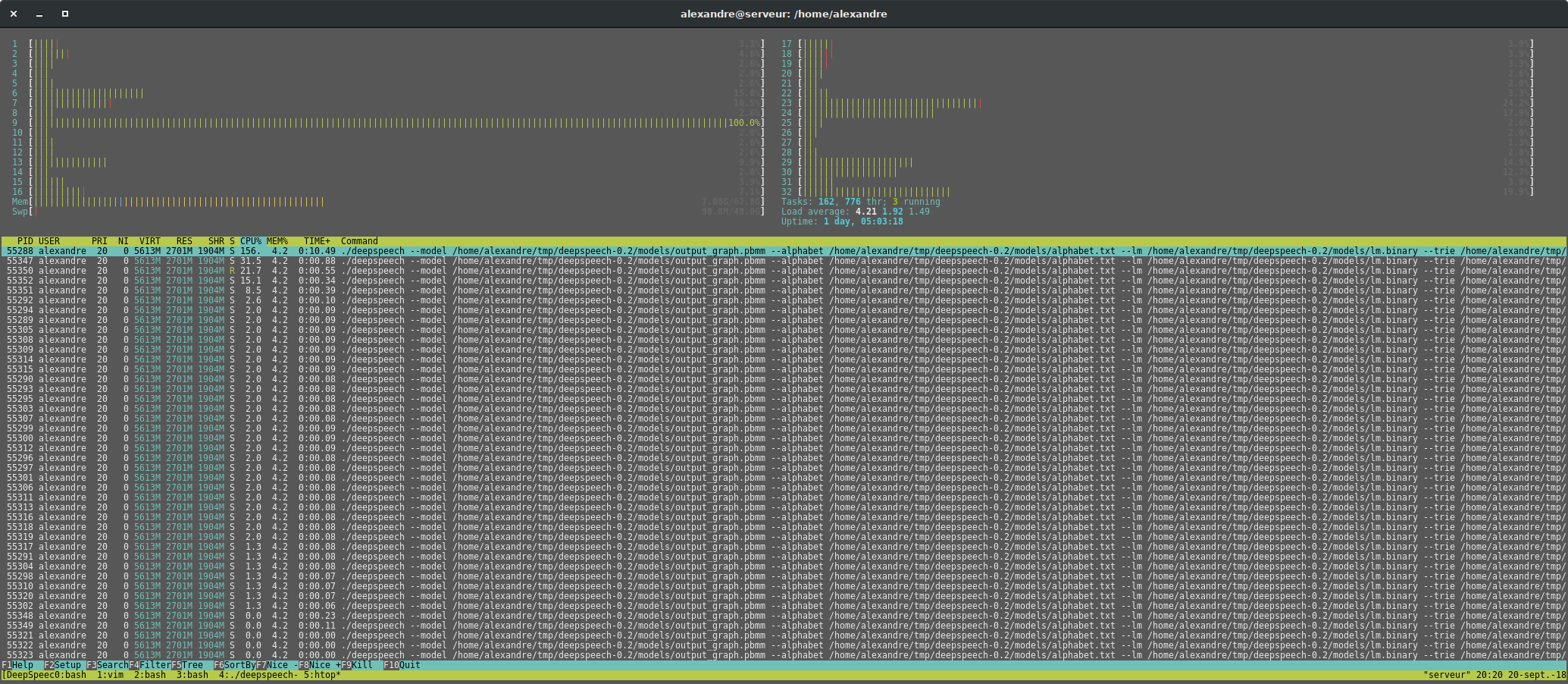
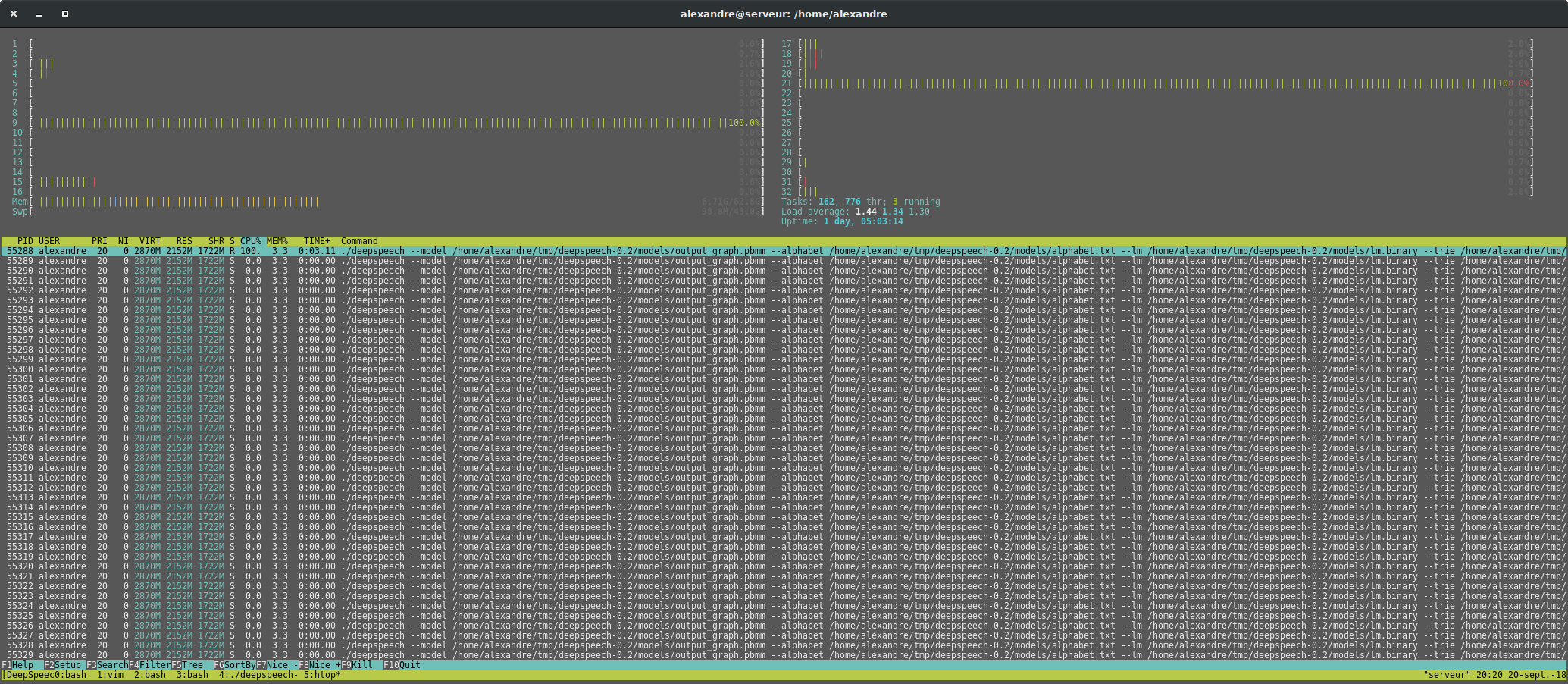
lissyx
on 20 Sep 2018
@NicoHood So, I do see 32 threads kicking in, and computing. Maybe not super-efficient, but that's another issue. It'd be great if you could share your exact STR and hardware, so we can see how bad it is for you.
lissyx
on 20 Sep 2018
Slow means it takes longer to analyze than the audio is long. Maybe it uses multiple threads, but they are all on a single core. And that is the limit for the threads to execute. Your screenshot shows the exact same problem I guess. Maybe a single core is faster for you, so its still quite fast.
Intel(R) Core(TM) i7-4702MQ CPU @ 2.20GHz
NicoHood
on 20 Sep 2018
Slow means it takes longer to analyze than the audio is long. Maybe it uses multiple threads, but they are all on a single core. And that is the limit for the threads to execute. Your screenshot shows the exact same problem I guess. Maybe a single core is faster for you, so its still quite fast.
Intel(R) Core(TM) i7-4702MQ CPU @ 2.20GHz
We need more than just "it takes longer". TensorFlow controls the parallelism of the ops, we don't have that much control over it. It's possible there is just not enough to do accross multiple cores?
lissyx
on 21 Sep 2018
Running inference also has some setup costs, and depending on how you measure this might give your the feeling that things are slow.
lissyx
on 21 Sep 2018
No matter how it works, it is slow. 10 seconds for a 3s long audio:
$ date && deepspeech --model output_graph.pb --alphabet alphabet.txt --lm lm.binary --trie trie --audio test.wav && date
Fri Sep 21 15:31:21 CEST 2018
TensorFlow: b'v1.6.0-18-g50214731ea'
DeepSpeech: unknown
Warning: reading entire model file into memory. Transform model file into an mmapped graph to reduce heap usage.
2018-09-21 15:31:21.663859: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
hello this is attesti
Fri Sep 21 15:31:31 CEST 2018
# Official test audio file
$ date && deepspeech --model output_graph.pb --alphabet alphabet.txt --lm lm.binary --trie trie --audio 4507-16021-0012.wav && date
Fri Sep 21 15:32:50 CEST 2018
TensorFlow: b'v1.6.0-18-g50214731ea'
DeepSpeech: unknown
Warning: reading entire model file into memory. Transform model file into an mmapped graph to reduce heap usage.
2018-09-21 15:32:50.193486: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
why should one halt on the way
Fri Sep 21 15:32:59 CEST 2018
@NicoHood Thanks for those figures :). The way you perform testing does matter. Could you try with the following?
- use the
.pbmmfile, this avoid a lot of memory allocations - give a directory with multiple WAV inside for the audio, and not just a file, this will run multiple times and will allow to see the difference between a first slower run
- pass the
-tflag to see how much time is indeed spent in inference
lissyx
on 21 Sep 2018
Also, just in case, would you mind giving a try in comparison with our binaries ?
lissyx
on 21 Sep 2018
[arch@talloniv models]$ date && deepspeech --model output_graph.pb --alphabet alphabet.txt --lm lm.binary --trie trie --audio audio -t && date
Fri Sep 21 15:54:55 CEST 2018
TensorFlow: b'v1.6.0-18-g50214731ea'
DeepSpeech: unknown
Warning: reading entire model file into memory. Transform model file into an mmapped graph to reduce heap usage.
2018-09-21 15:54:55.749334: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Running on directory audio
> audio/2830-3980-0043.wav
experience proves this
cpu_time_overall=2.87568
> audio/4507-16021-0012.wav
why should one halt on the way
cpu_time_overall=3.08023
> audio/8455-210777-0068.wav
your power is sufficient i saiy
cpu_time_overall=2.92105
Fri Sep 21 15:55:09 CEST 2018
[arch@talloniv models]$ date && deepspeech --model output_graph.pbmm --alphabet alphabet.txt --lm lm.binary --trie trie --audio audio -t && date
Fri Sep 21 15:55:21 CEST 2018
TensorFlow: b'v1.6.0-18-g50214731ea'
DeepSpeech: unknown
2018-09-21 15:55:21.352876: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Running on directory audio
> audio/2830-3980-0043.wav
experience proves this
cpu_time_overall=2.48478
> audio/4507-16021-0012.wav
why should one halt on the way
cpu_time_overall=3.14252
> audio/8455-210777-0068.wav
your power is sufficient i saidh
cpu_time_overall=2.91874
Fri Sep 21 15:55:34 CEST 2018
[arch@talloniv models]$ date && deepspeech --model output_graph.rounded.pb --alphabet alphabet.txt --lm lm.binary --trie trie --audio audio -t && date
Fri Sep 21 15:55:44 CEST 2018
TensorFlow: b'v1.6.0-18-g50214731ea'
DeepSpeech: unknown
Warning: reading entire model file into memory. Transform model file into an mmapped graph to reduce heap usage.
2018-09-21 15:55:44.789549: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Running on directory audio
> audio/2830-3980-0043.wav
experience proves this
cpu_time_overall=2.83313
> audio/4507-16021-0012.wav
why should one halt on the way
cpu_time_overall=3.04817
> audio/8455-210777-0068.wav
your power is sufficient i saind
cpu_time_overall=2.93069
Fri Sep 21 15:55:58 CEST 2018
[arch@talloniv models]$ date && deepspeech --model output_graph.rounded.pbmm --alphabet alphabet.txt --lm lm.binary --trie trie --audio audio -t && date
Fri Sep 21 15:56:08 CEST 2018
TensorFlow: b'v1.6.0-18-g50214731ea'
DeepSpeech: unknown
2018-09-21 15:56:09.018391: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Running on directory audio
> audio/2830-3980-0043.wav
experience proves this
cpu_time_overall=2.56890
> audio/4507-16021-0012.wav
why should one halt on the way
cpu_time_overall=3.17809
> audio/8455-210777-0068.wav
your power is sufficient i saind
cpu_time_overall=3.02384
Fri Sep 21 15:56:22 CEST 2018
So it looks like the setup time is slow, but the processing itself is "okay". To me it still does not like it is using all available system resources. It is too slow for real world scenarios.
I am not sure if your binaries work, as they might be linked against too old libraries. I will try.
Edit: Which one should I try? The pip package or which of the downloads?
NicoHood
on 21 Sep 2018
@NicoHood Thanks for those figures, it gives a better understanding. Now, those look a bit slow, but that's closer to what we would expect. Now, it'd be interesting if you could share your expectations as "real world scenarios" and "using all available system resources".
Regarding the libraries, for a quick test, if you worry about sox, you should be able to use newer sox (or sox3) named as libsox.so.2, it's ugly but in our case it should work good enough for testing.
lissyx
on 21 Sep 2018
@NicoHood Just pick the native_client.tar.xz linux CPU build, it should bundle everything except libsox, and you can copy and rename it next to the binary.
lissyx
on 21 Sep 2018
My real world scenario is:
I use snowboy to detect a hotword and record the sound said afterwards. Then I process it with deepspeech to turn the lights on. A Processing of 10 seconds means 10 additional seconds to wait until the light turns on, excluding the light API delay. That is too slow.
Use all available system resources simply means all CPU cores. My CPU is mostly idle, as in the screenshot above. Only a single core is used.
NicoHood
on 21 Sep 2018
@NicoHood In such kind of setup, you would have the model already loaded except if you want to call the binary each time, depending on the infrastructure you are working on. One would need to precisely profile to understand ...
lissyx
on 21 Sep 2018
With the native client from you, and libsox3 as you explained:
[arch@talloniv models]$ date && ../../native_client.amd64.cpu.linux/deepspeech --model output_graph.pb --alphabet alphabet.txt --lm lm.binary --trie trie --audio audio -t && date
Fri Sep 21 16:15:31 CEST 2018
TensorFlow: v1.6.0-18-g5021473
DeepSpeech: v0.2.0-0-g009f9b6
Warning: reading entire model file into memory. Transform model file into an mmapped graph to reduce heap usage.
2018-09-21 16:15:31.392159: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Running on directory audio
> audio/2830-3980-0043.wav
experience proves this
cpu_time_overall=2.84021
> audio/4507-16021-0012.wav
why should one halt on the way
cpu_time_overall=3.04365
> audio/8455-210777-0068.wav
your power is sufficient i said
cpu_time_overall=2.96763
Fri Sep 21 16:15:44 CEST 2018
Seems to be no difference
NicoHood
on 21 Sep 2018
@NicoHood Can you check on your side what results you get when you remove language model and trie file?
alexandre@serveur:~/tmp/deepspeech-0.2/bin-cpu$ ./deepspeech --model ~/tmp/deepspeech-0.2/models/output_graph.pbmm --alphabet ~/tmp/deepspeech-0.2/models/alphabet.txt --audio ~/tmp/deepspeech-0.2/audio/ -t 2>&1 | ts
sept. 21 16:20:16 TensorFlow: v1.6.0-18-g5021473
sept. 21 16:20:16 DeepSpeech: v0.2.0-0-g009f9b6
sept. 21 16:20:16 2018-09-21 16:20:16.514772: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
sept. 21 16:20:19 Running on directory /home/alexandre/tmp/deepspeech-0.2/audio/
sept. 21 16:20:19 > /home/alexandre/tmp/deepspeech-0.2/audio//2830-3980-0043.wav
sept. 21 16:20:19 experience proves this
sept. 21 16:20:19 cpu_time_overall=2.29845
sept. 21 16:20:19 > /home/alexandre/tmp/deepspeech-0.2/audio//4507-16021-0012.wav
sept. 21 16:20:19 why should one hall t on the way
sept. 21 16:20:19 cpu_time_overall=2.14240
sept. 21 16:20:19 > /home/alexandre/tmp/deepspeech-0.2/audio//8455-210777-0068.wav
sept. 21 16:20:19 your power is sufficient i said
sept. 21 16:20:19 cpu_time_overall=2.00424
alexandre@serveur:~/tmp/deepspeech-0.2/bin-cpu$ ./deepspeech --model ~/tmp/deepspeech-0.2/models/output_graph.pbmm --alphabet ~/tmp/deepspeech-0.2/models/alphabet.txt --lm ~/tmp/deepspeech-0.2/models/lm.binary --trie ~/tmp/deepspeech-0.2/models/trie --audio ~/tmp/deepspeech-0.2/audio/ -t 2>&1 | ts
sept. 21 16:20:32 TensorFlow: v1.6.0-18-g5021473
sept. 21 16:20:32 DeepSpeech: v0.2.0-0-g009f9b6
sept. 21 16:20:32 2018-09-21 16:20:32.660034: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
sept. 21 16:20:41 Running on directory /home/alexandre/tmp/deepspeech-0.2/audio/
sept. 21 16:20:41 > /home/alexandre/tmp/deepspeech-0.2/audio//2830-3980-0043.wav
sept. 21 16:20:41 experience proves this
sept. 21 16:20:41 cpu_time_overall=2.45134
sept. 21 16:20:41 > /home/alexandre/tmp/deepspeech-0.2/audio//4507-16021-0012.wav
sept. 21 16:20:41 why should one halt on the way
sept. 21 16:20:41 cpu_time_overall=2.26664
sept. 21 16:20:41 > /home/alexandre/tmp/deepspeech-0.2/audio//8455-210777-0068.wav
sept. 21 16:20:41 your power is sufficient i said
sept. 21 16:20:41 cpu_time_overall=2.12604
alexandre@serveur:~/tmp/deepspeech-0.2/bin-cpu$
@NicoHood In particular, please note the times between the versions and the time displayed at Running, there might be something bogus we do with the LM.
lissyx
on 21 Sep 2018
It is faster, but the output/result is not as precise:
$ date && ../../native_client.amd64.cpu.linux/deepspeech --model output_graph.pb --alphabet alphabet.txt --audio audio -t && date
Fri Sep 21 16:31:23 CEST 2018
TensorFlow: v1.6.0-18-g5021473
DeepSpeech: v0.2.0-0-g009f9b6
Warning: reading entire model file into memory. Transform model file into an mmapped graph to reduce heap usage.
2018-09-21 16:31:23.560578: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Running on directory audio
> audio/2830-3980-0043.wav
experience proves this
cpu_time_overall=2.50360
> audio/4507-16021-0012.wav
why should one hall t on the way
cpu_time_overall=2.63785
> audio/8455-210777-0068.wav
your power is sufficient i said
cpu_time_overall=2.53663
Fri Sep 21 16:31:29 CEST 2018
@NicoHood Thanks! That's progressing! Do you mind doing the same with the stderr redirection and piping everything into ts, just to get a better granularity? And give a try to the pbmm, even though I don't think it's going to have a huge impact now.
lissyx
on 21 Sep 2018
what is ts? Do you mean with debug symbols?
NicoHood
on 21 Sep 2018
It's a small binary that is able to timestand anything piped on its stdin. On debian, it's packaged in moreutils :)
lissyx
on 21 Sep 2018
$ ../../native_client.amd64.cpu.linux/deepspeech --model output_graph.pb --alphabet alphabet.txt --audio audio -t 2>&1 | ts
Sep 21 16:49:04 TensorFlow: v1.6.0-18-g5021473
Sep 21 16:49:04 DeepSpeech: v0.2.0-0-g009f9b6
Sep 21 16:49:04 Warning: reading entire model file into memory. Transform model file into an mmapped graph to reduce heap usage.
Sep 21 16:49:04 2018-09-21 16:49:04.361310: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Sep 21 16:49:10 Running on directory audio
Sep 21 16:49:10 > audio/2830-3980-0043.wav
Sep 21 16:49:10 experience proves this
Sep 21 16:49:10 cpu_time_overall=2.53627
Sep 21 16:49:10 > audio/4507-16021-0012.wav
Sep 21 16:49:10 why should one hall t on the way
Sep 21 16:49:10 cpu_time_overall=2.63391
Sep 21 16:49:10 > audio/8455-210777-0068.wav
Sep 21 16:49:10 your power is sufficient i said
Sep 21 16:49:10 cpu_time_overall=2.52646
Edit: This does not represent the actual timings. ts seems to work wrong.
NicoHood
on 21 Sep 2018
@NicoHood Thanks, and with the --lm and --trie ? And .pbmm file?
lissyx
on 21 Sep 2018
[arch@talloniv models]$ ../../native_client.amd64.cpu.linux/deepspeech --model output_graph.pb --alphabet alphabet.txt --lm lm.binary --trie trie --audio audio -t 2>&1 | ts
Sep 21 17:02:15 TensorFlow: v1.6.0-18-g5021473
Sep 21 17:02:15 DeepSpeech: v0.2.0-0-g009f9b6
Sep 21 17:02:15 Warning: reading entire model file into memory. Transform model file into an mmapped graph to reduce heap usage.
Sep 21 17:02:15 2018-09-21 17:02:15.824619: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Sep 21 17:02:28 Running on directory audio
Sep 21 17:02:28 > audio/2830-3980-0043.wav
Sep 21 17:02:28 experience proves this
Sep 21 17:02:28 cpu_time_overall=2.72783
Sep 21 17:02:28 > audio/4507-16021-0012.wav
Sep 21 17:02:28 why should one halt on the way
Sep 21 17:02:28 cpu_time_overall=2.86356
Sep 21 17:02:28 > audio/8455-210777-0068.wav
Sep 21 17:02:28 your power is sufficient i said
Sep 21 17:02:28 cpu_time_overall=2.73401
[arch@talloniv models]$ ../../native_client.amd64.cpu.linux/deepspeech --model output_graph.pbmm --alphabet alphabet.txt --lm lm.binary --trie trie --audio audio -t 2>&1 | ts
Sep 21 17:02:35 TensorFlow: v1.6.0-18-g5021473
Sep 21 17:02:35 DeepSpeech: v0.2.0-0-g009f9b6
Sep 21 17:02:35 2018-09-21 17:02:35.428183: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Sep 21 17:02:47 Running on directory audio
Sep 21 17:02:47 > audio/2830-3980-0043.wav
Sep 21 17:02:47 experience proves this
Sep 21 17:02:47 cpu_time_overall=2.28447
Sep 21 17:02:47 > audio/4507-16021-0012.wav
Sep 21 17:02:47 why should one halt on the way
Sep 21 17:02:47 cpu_time_overall=2.95592
Sep 21 17:02:47 > audio/8455-210777-0068.wav
Sep 21 17:02:47 your power is sufficient i said
Sep 21 17:02:47 cpu_time_overall=2.79138
[arch@talloniv models]$ ../../native_client.amd64.cpu.linux/deepspeech --model output_graph.pbmm --alphabet alphabet.txt --audio audio -t 2>&1 | ts
Sep 21 17:02:54 TensorFlow: v1.6.0-18-g5021473
Sep 21 17:02:54 DeepSpeech: v0.2.0-0-g009f9b6
Sep 21 17:02:54 2018-09-21 17:02:54.610379: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Sep 21 17:02:59 Running on directory audio
Sep 21 17:02:59 > audio/2830-3980-0043.wav
Sep 21 17:02:59 experience proves this
Sep 21 17:02:59 cpu_time_overall=2.08439
Sep 21 17:02:59 > audio/4507-16021-0012.wav
Sep 21 17:02:59 why should one hall t on the way
Sep 21 17:02:59 cpu_time_overall=2.63788
Sep 21 17:02:59 > audio/8455-210777-0068.wav
Sep 21 17:02:59 your power is sufficient i said
Sep 21 17:02:59 cpu_time_overall=2.52035
@NicoHood Thanks, so that's what I'm seeing, and it's not good. So far, I doubt it has anything to do with threading and TensorFlow, but we should look into that :)
lissyx
on 21 Sep 2018
@NicoHood So, the increased loading time comes from how we read the trie file and given it's size increase with newer model.
lissyx
on 28 Sep 2018
@lissyx I have no knowledge about that. Is there something that I can use to try out any fix?
AtosNicoS
on 28 Sep 2018
@AtosNicoS Nope, it's just to keep you uptodate that we are looking into that
lissyx
on 28 Sep 2018
@AtosNicoS Looks like just changing the way we read and write the TRIE file helps good enough: https://github.com/mozilla/DeepSpeech/pull/1610#issuecomment-425956145 and https://github.com/mozilla/DeepSpeech/pull/1610#issuecomment-425956269
The PR also features a trie_load simple binary that just performs the trie loading, running that on the old file format is about 4.5sec, and with the new, it's around 1.5sec.
lissyx
on 1 Oct 2018
Are there any plans for the 2.1 release? Also where can I find the language models for other languages, such as german? I've seen data is being collected on the website.
NicoHood
on 22 Oct 2018
@NicoHood What kind of plan do you look for ? For the other languages, there's not enough data being collected yet from Common Voice.
lissyx
on 22 Oct 2018
As you can see here, 0.3.0 is close https://github.com/mozilla/DeepSpeech/projects
lissyx
on 22 Oct 2018
Per the other ticket linked just above, libdeepspeech and deepspeech-models are now in the AUR. The packages created from this discussion are useful but are out-of-date and should be bumped by their maintainer(s). @NicoHood I think you own at least one of those??
 9define
on 19 May 2019
9define
on 19 May 2019
Yes I own the package, but I did not check it for a long time. I am happy to disown the package or add another co-maintainer.
NicoHood
on 20 May 2019
Per the other ticket linked just above,
libdeepspeechanddeepspeech-modelsare now in the AUR. The packages created from this discussion are useful but are out-of-date and should be bumped by their maintainer(s). @NicoHood I think you own at least one of those??
Could you update to 0.5.1 ? The 0.5.0 is bogus
lissyx
on 19 Jul 2019
@lissyx Done.
9define
on 20 Jul 2019
@9define May you please claim https://aur.archlinux.org/packages/deepspeech/ ? It doesn't build since a long time.
 chazanov
on 21 Jul 2019
chazanov
on 21 Jul 2019
@chazanov While it would be nice to get that working, I am unable to claim that package at this time due to a lack of time. @NicoHood ping re that upkeep, it's been awhile...
9define
on 21 Jul 2019
@9define what is your username on AUR? gobennyb?
NicoHood
on 30 Jul 2019
@NicoHood yes, but please do not add me to packages without first consulting me. As I mentioned, I am unable (and unwilling) to [co-]maintain that package at this time, so please work on that yourself/abandon it/look for other help.
9define
on 31 Jul 2019
Oh, I overlooked that part, sorry. I disowned the package.
NicoHood
on 31 Jul 2019
I think the issue can be closed now that the AUR package has been updated
 xantares
on 13 May 2020
xantares
on 13 May 2020
Related issues
lissyx
·
33Comments
 MuruganR96
·
28Comments
MuruganR96
·
28Comments
 MalikMahnoor
·
79Comments
MalikMahnoor
·
79Comments
 MaxPowerWasTaken
·
40Comments
MaxPowerWasTaken
·
40Comments
 verloka
·
23Comments
verloka
·
23Comments