Deeplearning4j: Observing High variance accuracy in DL4J
I converted a logistic regression problem from keras to dl4j. I have 10000 data sets out of which 8000 sets used for training.
Here is the data set:
https://github.com/rahul-raj/Problem-Solving/blob/master/Churn_Modelling.csv
Here is what I did in Keras:
1) Split the entire data set into vectors -> X_Train, X_Test, Y_Train, Y_Test where X correspond to input labels and Y correspond to output. First three labels : RowNumber, CustomerId & Surname are ignored.
2) Transform & scale them, then feed to neural network.
3) Find confusion matrix at the end.
Here is the python code:
https://github.com/rahul-raj/Problem-Solving/blob/master/ANN.py
Ignore lines 71 to 79 -> code for exporting keras model.
My DL4J code looks like this:
https://github.com/rahul-raj/Problem-Solving/blob/master/DeepLearning4j.java
I just tried to make it exactly the same implementation as Keras. Only the difference is that I used datasets instead of INDArray (data pre-processing) , because otherwise I can't make use of TransformProcessRecordReader in the code.
But I guess that doesn't make an issue here. When I use imported model from keras, I was able to see confusion matrix same as in keras.
https://github.com/rahul-raj/Problem-Solving/blob/master/Test.java
So, now I'm left with only one option, that is to import model from keras and use it on dl4j everytime. I would like to perform everything on dl4j itself. So, I'm trying to figure out why there's high variance in the accuracy compared to the same code in Keras? Correct me if you spot discrepancies in the code. Thank you!
@AlexDBlack
 rahul-raj
rahul-raj
All 36 comments
Here's sample execution seen from console:
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 950 is 0.7447306315104166
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 960 is 0.7397637261284722
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 970 is 0.747509765625
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 980 is 0.7393998209635416
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 990 is 0.7453626166449653
args = [
========================Evaluation Metrics========================
# of classes: 2
Accuracy: 0.7700
Precision: 0.5235
Recall: 0.5093
F1 Score: 0.1221
Precision, recall & F1: macro-averaged (equally weighted avg. of 2 classes)
=========================Confusion Matrix=========================
0 1
-----------
1508 102 | 0 = 0
358 32 | 1 = 1
Confusion matrix format: Actual (rowClass) predicted as (columnClass) N times
Another execution ->
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 850 is 0.8710540093315973
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 860 is 0.858331298828125
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 870 is 0.8572982449001736
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 880 is 0.8707122124565972
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 890 is 0.8648240831163194
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 900 is 0.8671436903211805
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 910 is 0.8576726616753472
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 920 is 0.8707830810546875
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 930 is 0.8825572374131945
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 940 is 0.8763357204861111
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 950 is 0.8622337510850695
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 960 is 0.8728404405381944
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 970 is 0.8978228759765625
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 980 is 0.8639754231770833
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 990 is 0.8822585720486111
args = [
========================Evaluation Metrics========================
# of classes: 2
Accuracy: 0.2205
Precision: 0.5583
Recall: 0.5110
F1 Score: 0.3306
Precision, recall & F1: macro-averaged (equally weighted avg. of 2 classes)
=========================Confusion Matrix=========================
0 1
-----------
56 1554 | 0 = 0
5 385 | 1 = 1
Confusion matrix format: Actual (rowClass) predicted as (columnClass) N times
==================================================================]
OK, finally got to looking at this, apologies for the delay.
Comparing your implementations:
DL4J: https://github.com/rahul-raj/Problem-Solving/blob/master/DeepLearning4j.java
Keras: https://github.com/rahul-raj/Problem-Solving/blob/master/ANN.py
Some differences and issues I've seen:
- Keras config doesn't have dropout, DL4J config does
- DL4J config is set to an inappropriate value: dropout(0.1) means 10% probability of retaining the activations (90% set to 0), which is way too high - https://deeplearning4j.org/doc/org/deeplearning4j/nn/conf/layers/Layer.Builder.html#dropOut-double-
- Your use of Evaluation class is incorrect - just pass in the raw probabilities, don't do the thresholding before passing to Evaluation class
Also I can't speak to your KFoldIterator - does that use the same batch size as your Keras implementation?
Finally, you are not setting a learning rate. In this case, the default of 1e-3 is used (same as Keras), but still not good IMO to rely on the defaults (better to be explicit).
Anyway, maybe fix those issues and let me know if the training performance is more in line with the Keras implementation.
 AlexDBlack
on 29 May 2018
AlexDBlack
on 29 May 2018
Thank you for Alex for the analysis and valuable observations. Here are my comments on the issues mentioned:
Keras config doesn't have dropout, DL4J config does ->
Adding the dropout code on keras gives a small rise to the accuracy, and can be ignored. So, I removed that from Keras code. The difference in accuracy in both the cases are less.
DL4J config is set to an inappropriate value: dropout(0.1) means 10% probability of retaining the activations (90% set to 0), which is way too high https://deeplearning4j.org/doc/org/deeplearning4j/nn/conf/layers/Layer.Builder.html#dropOut-double- ->
I just took it in the reverse order. Now I edited this to 0.9.
Your use of Evaluation class is incorrect - just pass in the raw probabilities, don't do the thresholding before passing to Evaluation class ->
I think you're referring to this line of code:
output = output.cond(new AbsValueGreaterThan(0.50));
I commented this line now
The purpose was to do the exact same operation as in Keras.
```
y_pred = classifier.predict(X_test)
y_pred = (y_pred > 0.5)
```
Also I can't speak to your KFoldIterator - does that use the same batch size as your Keras implementation?
->
Do you mean to say batchSize to be defined for each fold? If yes, can you guide me how to do that?
I dont see a parameterized cosntructor either that does this job.
Otherwise, As you could observe in the corresponding Keras code:
classifier = KerasClassifier(build_fn=buildANN, batch_size=10, epochs=100)
accuracy = cross_val_score(estimator=classifier, X=X_train, y=y_train, cv=10, n_jobs=1)
I mentioned k value as 10 in Keras and default value for k in DL4J is 10 too.
And I mentioned earlier, there are no options to pass batchSize with KFoldIterator
batchSize in Keras is 10 (for each fold)`
Finally, you are not setting a learning rate. In this case, the default of 1e-3 is used (same as Keras), but still not good IMO to rely on the defaults (better to be explicit). ->
Acknowledging that default rate might not be good to use. We can try and experiment various learning rates to find out one that gives more accuracy. I would try passing values like this:
.updater(new Adam(0.0002D))
But then, I'm seeing high variant accuracy for the same learning rate. So, may be we can rectify high variance and then get back to this point. I will also try using regularization.
Correct me if any of my above assumptions are wrong. I'm still observing high variance after the above changes applied. Highly appreciate you're checking this at your busy hours. Thank you!
rahul-raj
on 29 May 2018
The KFoldIterator is rather simple, it takes only a dataset and splits it into k pieces. Given the problem you're describing in your issue, I'd suggest that you simply skip using it all together
From what I can see here, the biggest difference is probably the kfold iterator use now, because you get 9 updates (default split with kfold iterator: k = 10, as one is held out for evaluation) with a batchsize of 800 instead of 800 updates with a batchsize of 10.
 treo
on 29 May 2018
treo
on 29 May 2018
I removed the KFoldIterator and my training code look like this now:
for(int i=0;i<100;i++){
multiLayerNetwork.fit(trainSet);
}
Result is pretty much the same, still high variance :(
rahul-raj
on 29 May 2018
@AlexDBlack
I tried out few stuff and got below observation/questions, hope it will help out further analysis.
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
I was thinking this is same as.updater(new Adam()).
Wanted to know whether both having different purpose.
I saw both are used at one place here: Feed-Forward Network
So whether I need to have both in my neural network configuration?Heard that
KFoldwill reduce high variation. But as treo mentioned earlier, if updates are more for a lowerbatchSize, what's the significance of usingKFoldat all?I think the actual issue is around displaying "Evaluation Metrics" & "Confusion Matrix". Here are results from multiple executions:
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 0 is 0.678351806640625
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 10 is 0.67851513671875
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 20 is 0.6789616088867187
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 30 is 0.6787621459960937
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 40 is 0.6787064208984375
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 50 is 0.6786689453125
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 60 is 0.6787816162109375
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 70 is 0.6785487060546875
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 80 is 0.6785655517578125
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 90 is 0.6783565063476562
========================Evaluation Metrics========================
# of classes: 2
Accuracy: 0.6985
Precision: 0.4999
Recall: 0.4999
F1 Score: 0.1840
Precision, recall & F1: macro-averaged (equally weighted avg. of 2 classes)
=========================Confusion Matrix=========================
0 1
-----------
1329 281 | 0 = 0
322 68 | 1 = 1
md5-9922d44b3dbea7619c3c716df21916f0
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 0 is 0.6688465576171875
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 10 is 0.668610595703125
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 20 is 0.6685675048828125
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 30 is 0.6686512451171875
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 40 is 0.66853857421875
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 50 is 0.6682931518554688
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 60 is 0.668674560546875
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 70 is 0.668659423828125
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 80 is 0.6685916748046875
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 90 is 0.668487548828125
md5-cb14ace4b5b7d8c953df543de6abe86e
========================Evaluation Metrics========================
# of classes: 2
Accuracy: 0.7870
Precision: 0.4915
Recall: 0.4985
F1 Score: 0.0448
Precision, recall & F1: macro-averaged (equally weighted avg. of 2 classes)
=========================Confusion Matrix=========================
0 1
-----------
1564 46 | 0 = 0
380 10 | 1 = 1
md5-4c96f7d052b85d9ad939378edd134357
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 0 is 0.723574462890625
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 10 is 0.72368603515625
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 20 is 0.7235391235351563
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 30 is 0.7231525268554687
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 40 is 0.72343115234375
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 50 is 0.723321533203125
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 60 is 0.7235994873046875
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 70 is 0.7232736206054687
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 80 is 0.72303076171875
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 90 is 0.7229115600585938
md5-cb14ace4b5b7d8c953df543de6abe86e
========================Evaluation Metrics========================
# of classes: 2
Accuracy: 0.2255
Precision: 0.5422
Recall: 0.5102
F1 Score: 0.3297
Precision, recall & F1: macro-averaged (equally weighted avg. of 2 classes)
=========================Confusion Matrix=========================
0 1
-----------
70 1540 | 0 = 0
9 381 | 1 = 1
md5-4c96f7d052b85d9ad939378edd134357
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 0 is 0.6952838134765625
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 10 is 0.6954697265625
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 20 is 0.695283935546875
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 30 is 0.69511865234375
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 40 is 0.6952713012695313
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 50 is 0.694998046875
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 60 is 0.6952449951171875
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 70 is 0.6951326904296875
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 80 is 0.695539794921875
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 90 is 0.695051025390625
md5-cb14ace4b5b7d8c953df543de6abe86e
========================Evaluation Metrics========================
# of classes: 2
Accuracy: 0.4820
Precision: 0.4869
Recall: 0.4791
F1 Score: 0.2632
Precision, recall & F1: macro-averaged (equally weighted avg. of 2 classes)
=========================Confusion Matrix=========================
0 1
---------
779 831 | 0 = 0
205 185 | 1 = 1
You could observe that accuracy is almost getting stable (around 69% accuracy), but "Evaluation Metrics" & "Confusion Matrix" found to be incorrect(suspect to be). There may be something wrong in my evaluation part. But I see I did exactly the same as in Keras. Scores displayed on iterator are way too different from what is displayed as Accuracy in evaluation metrics.
rahul-raj
on 29 May 2018
Multiple Points here:
Score at iteration...doesn't report accuracy. It reports the average value of the loss function.- Your training regiment is totally wrong here. What you are doing right now results in just 100 updates with a batchsize of 8000!
Take a step back and read your code again. What you are doing is that you create an iterator that produces proper batches of 10 examples each. Then you collect all of those batches and merge them into a single one. You then split it again into two data sets, i.e. two batches, one containing 8000 examples and the other one containing 2000 examples. Then you pass just that one single batch of 8000 examples for training, and iterate a 100 times over it.
You could use DataSetIteratorSplitter, pass your iterator to it, and then get a test and train iterator from it. Just notice that this isn't something that you should use in production. But using splitTestAndTrain, like you are using it right now isn't any better in that regard.
treo
on 29 May 2018
@treo
Thanks for pointing out that.
Done below changes as you mentioned:
DataSetIterator iterator = new RecordReaderDataSetIterator(transformProcessRecordReader,batchSize,labelIndex,numClasses);
DataSetIteratorSplitter splitter = new DataSetIteratorSplitter(iterator,10000,0.8); //10000 total no.of examples (train + test)
model.fit(splitter.getTrainIterator(),100);
And my execution now look like this:
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 99200 is 9.209391784667968
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 99300 is 6.966828918457031
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 99400 is 5.937229919433594
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 99500 is 6.906944274902344
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 99600 is 4.96789665222168
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 99700 is 8.198497009277343
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 99800 is 6.97906494140625
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 99900 is 9.218247222900391
But now trying to figure out how would I pass this test iterator to evaluation class so that I could print evaluation metrics and confusion matrix.
I'm getting exception while I was trying to do something like this:
Evaluation evaluation = new Evaluation(1);
INDArray output = model.output(splitter.getTestIterator()); // Exception in thread "main" org.nd4j.linalg.exception.ND4JIllegalStateException: Can't concatenate 0 arrays
The full stacktrace for your exception would be more helpful here. But anyway, since you now have an iterator that you can pass around, you should probably use model.evaluate(splitter.getTestIterator()), it will provide you with an Evaluation instance from which you'd just output the stats.
treo
on 30 May 2018
@treo ,
Here's the full stacktrace:
Exception in thread "main" org.nd4j.linalg.exception.ND4JIllegalStateException: Can't concatenate 0 arrays
at org.nd4j.linalg.cpu.nativecpu.CpuNDArrayFactory.concat(CpuNDArrayFactory.java:660)
at org.nd4j.linalg.factory.Nd4j.concat(Nd4j.java:5925)
at org.deeplearning4j.nn.multilayer.MultiLayerNetwork.output(MultiLayerNetwork.java:2147)
at org.deeplearning4j.nn.multilayer.MultiLayerNetwork.output(MultiLayerNetwork.java:2157)
at DeepLearning4j.main(DeepLearning4j.java:82)
I will update the code as mentioned and post the results here. Thank you!
rahul-raj
on 30 May 2018
@treo ,
Added as below:
Evaluation evaluation = model.evaluate(splitter.getTestIterator());
System.out.println("args = " + evaluation.stats() + "");
Also added feature scaling which was missed earlier:
DataNormalization dataNormalization = new NormalizerStandardize();
dataNormalization.fit(iterator);
iterator.setPreProcessor(dataNormalization);
The execution results now look like this:
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 99200 is 0.5638524055480957
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 99300 is 0.5266752719879151
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 99400 is 0.42476391792297363
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 99500 is 0.5790013790130615
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 99600 is 0.4326747417449951
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 99700 is 0.4242351531982422
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 99800 is 0.4967750072479248
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 99900 is 0.2998473644256592
And, at the end, I'm getting different exception, here is the full stacktrace:
Exception in thread "main" java.lang.UnsupportedOperationException
at org.deeplearning4j.datasets.iterator.DataSetIteratorSplitter$2.getLabels(DataSetIteratorSplitter.java:188)
at org.deeplearning4j.nn.multilayer.MultiLayerNetwork.evaluate(MultiLayerNetwork.java:3181)
at org.deeplearning4j.nn.multilayer.MultiLayerNetwork.evaluate(MultiLayerNetwork.java:3102)
at org.deeplearning4j.nn.multilayer.MultiLayerNetwork.evaluate(MultiLayerNetwork.java:2958)
at DeepLearning4j.main(DeepLearning4j.java:81)
I'm getting this exception even though I specified label index and number of labels on the iterator before creating DataSetIteratorSplitter.
Link to the source -> https://github.com/rahul-raj/Problem-Solving/blob/master/DeepLearning4j.java
rahul-raj
on 30 May 2018
That is one of the reasons why the Splitter isn't supposed to be used outside of testing. But anyway:
You can easily pass the labels from the original iterator:
model.evaluate(splitter.getTestIterator(), iterator.getLabels())
treo
on 1 Jun 2018
@treo ,
model.evaluate(splitter.getTestIterator(), iterator.getLabels())
I added the same. Still getting the above mentioned error :(
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 9000 is 0.6697486400604248
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 9100 is 0.6548803329467774
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 9200 is 0.6415010452270508
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 9300 is 0.6035097599029541
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 9400 is 0.612823486328125
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 9500 is 0.6508085250854492
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 9600 is 0.5970096588134766
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 9700 is 0.5776329040527344
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 9800 is 0.6143147468566894
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 9900 is 0.5779543876647949
Exception in thread "main" java.lang.UnsupportedOperationException
at org.deeplearning4j.datasets.iterator.DataSetIteratorSplitter$2.getLabels(DataSetIteratorSplitter.java:188)
at org.deeplearning4j.nn.multilayer.MultiLayerNetwork.evaluate(MultiLayerNetwork.java:3181)
at org.deeplearning4j.nn.multilayer.MultiLayerNetwork.evaluate(MultiLayerNetwork.java:3102)
at DeepLearning4j.main(DeepLearning4j.java:87)
Well, that means that you don't have any named labels originally.
But you can still use that method, you just have to provide labels yourself, e.g.
model.evaluate(splitter.getTestIterator(), Arrays.asList("1"))
treo
on 1 Jun 2018
@treo ,
Can't we specify input label index (say 11, 0->10) here rather than adding a list of them manually?
In fact, I have added the labels manually into the schema + label indexes mentioned while creating dataset iterator.
When I was using the below code, testSet.getLabels() return an array of output labels from test set:
evaluation.eval(testSet.getLabels(),output);
How will I retrieve and pass this test array into model.evaluate() here? That's where I'm stuck :(
rahul-raj
on 1 Jun 2018
The point here is that those are label names, not actual labels that you specify. So if your original dataset iterator had those, you wouldn't have seen that exception in the first place.
What you are doing here, is exactly the same as what you did previously when you used Evaluation(1). If you want to use that instead, you can continue doing so: model.doEvaluation(splitter.getTestIterator(), evaluation) (with evaluation being defined as you did it earlier) should result in pretty much the same thing.
treo
on 1 Jun 2018
@treo ,
But then we used datasetsplitter and passed them directly to model instead of having datasets.
I checked if there's a away to set labels there, but couldnt find any.
And another question is why setting labels wasnt a requirement in my previous code that dealt with only datasets.
I'm a bit confused here how to get the same accuracy in my dl4j code as in my Keras code without importing the model.
Trying to make the same implementation in dl4j as in Keras.
rahul-raj
on 1 Jun 2018
I could just drop the proper code on you and be done with it, but then you will still be confused.
What you have to understand is that dl4j has disentangled the data pipeline from training the model. That means that you can't just pass all of your data off to model.fit. Usually we expect you to divide your data before even loading it, but to skip this step, you are using the DataSetIteratorSplitter.
When you go on to run evaluation, you might as well pass all your data in at once, but you've got an iterator, so instead you can pass in an iterator. But as it doesn't have label names, you've got to either provide them yourself, or you have to let it generate them (which in turn is 0,1,2, etc... ).
When you use model.evaluate(iter), it will try to get labels from the iterator. As DataSetIteratorSplitter is meant for testing, it doesn't support the .getLabels call. So we tried in to pass in the labels from your main data iterator, but it didn't have any as well. As you only have two labels (0, 1), I suggested that you simply enumerate them manually. But, apparently you didn't want to do that. So instead I've shown you how you can let the Evaluation class generate those labels themselves, and then pass that one on to your model, so the evaluation can be done properly.
So, please step back and take some time to properly understand what is happening at each line of your code. Both in your Keras implementation and in your DL4J implementation. Do not treat it as a Black Box and do not give up. Even if you decide that you just want to continue on using Keras because you don't like how DL4J does things, you will have a better understanding if how the steps work in isolation.
treo
on 1 Jun 2018
@treo,
Thanks for your detailed explanation.
Actually, I have tried this one when you suggested passing labels as list:
Evaluation evaluation = model.evaluate(splitter.getTestIterator(),Arrays.asList("0","1"));
System.out.println("args = " + evaluation.stats() + "");
And I got this output:
========================Evaluation Metrics========================
# of classes: 2
Accuracy: 0.0000
Precision: 0.0000
Recall: 0.0000
F1 Score: NaN
Precision, recall & F1: reported for positive class (class 1 - "1") only
Warning: 2 classes were never predicted by the model and were excluded from average precision
Classes excluded from average precision: [0, 1]
Warning: 2 classes were never predicted by the model and were excluded from average recall
Classes excluded from average recall: [0, 1]
=========================Confusion Matrix=========================
0 1
-----
0 0 | 0 = 0
0 0 | 1 = 1
Confusion matrix format: Actual (rowClass) predicted as (columnClass) N times
==================================================================
That's where I got confused what exactly is missing here :(
rahul-raj
on 1 Jun 2018
This looks very much like it didn't get any test examples what so ever, as the confusion matrix is empty. Can you update your dl4j code to be the exact same code as you where using here?
Along with your iteration count going to 99900 (actually 100000, but it starts at 0, and outputs only every 100 iterations), this looks like there is either some misuse of the iterator, or the Splitter has some problems.
treo
on 1 Jun 2018
@treo ,
Latest code updated as in my local:
https://github.com/rahul-raj/Problem-Solving/blob/master/DeepLearning4j.java
I added this:
model.setListeners(new ScoreIterationListener(100)); , may be thats why it print the outputs only every 100 iterations.
rahul-raj
on 1 Jun 2018
Yes, that is why it is printing every 100 iterations, but that isn't the main point. The main Point is that apparently the train iterator gets all 10000 examples instead of getting just 8000 examples and leaving 2000 examples for testing. So at this point I'll have to take a closer look at what causes this weird behavior.
treo
on 1 Jun 2018
@treo
In the meantime I will also check this on my local. Thank you!
rahul-raj
on 1 Jun 2018
It looks like the problem there is very simple: DataSetIteratorSplitter requires the number of batches the underlying iterator has, not the total number of examples, ever though the constructor parameter is called totalExamples. So if you set it to 1000 ( = 10000 Examples / 10 Examples per Batch), it will work correctly.
treo
on 2 Jun 2018
@treo
Thanks a lot, that was truly amazing :)
I just ran the code and here are the results and observations:
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 79000 is 0.5136202812194824
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 79100 is 0.5961973190307617
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 79200 is 1.0605329513549804
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 79300 is 0.6056034564971924
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 79400 is 0.7506316661834717
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 79500 is 0.4980428218841553
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 79600 is 0.5240177154541016
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 79700 is 0.6336871147155761
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 79800 is 0.49535531997680665
[main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 79900 is 0.45655322074890137
args =
========================Evaluation Metrics========================
# of classes: 2
Accuracy: 0.8050
Precision: 0.8050
Recall: 0.5000
F1 Score: 0.0000
Precision, recall & F1: reported for positive class (class 1 - "1") only
Warning: 1 class was never predicted by the model and was excluded from average precision
Classes excluded from average precision: [1]
=========================Confusion Matrix=========================
0 1
-----------
1610 0 | 0 = 0
390 0 | 1 = 1
Confusion matrix format: Actual (rowClass) predicted as (columnClass) N times
==================================================================
So, now it iterates through exactly 80000 times as expected. I get an accuracy of 80.50 % consistently for various learning rates (0.01, 0.001, 0.0001 etc) now. If we change the learning rate that we pass to adam, does it have effect on the accuracy? What I think is "yes", but in that case I should see some changes in the accuracy (either increase/decrease) here right? I'm getting 80.50% for all the learning rates I passed to adam. Sorry, If I'm bumping you too much, but this just got into my mind.
rahul-raj
on 2 Jun 2018
At this point you are just looking at a plain old tuning problem. One thing that you definitely should do is add a seed to your configuration, to make the initialization random, but fixed. If you don't you will see differences between two runs simply because you ran it an additional time.
Your situation here is now that you are seeing an overfitting case: The network learns that everything is class 0.
treo
on 2 Jun 2018
@treo
Tried changing dropouts, seed, learningrate, number of epochs, l1 / l2 regularization etc as well.
But the overfitting is still there. At-least one of the above mentioned parameters have an impact on over-fitting, but situation isn't changing even if I tried with different values :(
rahul-raj
on 2 Jun 2018
Do you have the same overfitting with keras? If not, do as I said in an earlier comment: Step back, and try to find out what parameters you have in keras (since some are implicit, it may be a good idea to export the model and take a look at the json file's contents). Then try to set the exactly same parameters in DL4J.
treo
on 2 Jun 2018
@treo ,
Here is what I could see on my json model from Keras:
{
"class_name":"Sequential",
"config":[
{
"class_name":"Dense",
"config":{
"name":"dense_31",
"trainable":true,
"batch_input_shape":[
null,
11
],
"dtype":"float32",
"units":6,
"activation":"relu",
"use_bias":true,
"kernel_initializer":{
"class_name":"RandomUniform",
"config":{
"minval":-0.05,
"maxval":0.05,
"seed":null
}
},
"bias_initializer":{
"class_name":"Zeros",
"config":{
}
},
"kernel_regularizer":null,
"bias_regularizer":null,
"activity_regularizer":null,
"kernel_constraint":null,
"bias_constraint":null
}
},
{
"class_name":"Dense",
"config":{
"name":"dense_32",
"trainable":true,
"units":6,
"activation":"relu",
"use_bias":true,
"kernel_initializer":{
"class_name":"RandomUniform",
"config":{
"minval":-0.05,
"maxval":0.05,
"seed":null
}
},
"bias_initializer":{
"class_name":"Zeros",
"config":{
}
},
"kernel_regularizer":null,
"bias_regularizer":null,
"activity_regularizer":null,
"kernel_constraint":null,
"bias_constraint":null
}
},
{
"class_name":"Dense",
"config":{
"name":"dense_33",
"trainable":true,
"units":1,
"activation":"sigmoid",
"use_bias":true,
"kernel_initializer":{
"class_name":"RandomUniform",
"config":{
"minval":-0.05,
"maxval":0.05,
"seed":null
}
},
"bias_initializer":{
"class_name":"Zeros",
"config":{
}
},
"kernel_regularizer":null,
"bias_regularizer":null,
"activity_regularizer":null,
"kernel_constraint":null,
"bias_constraint":null
}
}
],
"keras_version":"2.1.5",
"backend":"tensorflow"
}
There's a min-max range for the weights, but other than that nothing specific. I had this model imported for a previous issue tracker here. The only difference in dl4j code is that we are not setting min-max range for weights, but indeed specifying random uniformity here: weightInit(WeightInit.UNIFORM).
So, I just tried changing it to:
.weightInit(WeightInit.DISTRIBUTION).dist(new UniformDistribution(-0.05,0.05))
However over-fitting is still there :(
Updated source code:
https://github.com/rahul-raj/Deeplearning4J/blob/master/src/main/java/DeepLearning4j.java
rahul-raj
on 2 Jun 2018
One thing that I've noticed is that you are using a very low learning rate and that as the data isn't balanced, it does have a tendency to favor the majority class. By increasing the batch size (note you'll also have to decrease the Spliterator Batch count in that case, or simply set it to 10000 / batchSize), that effect can be somewhat countered, but to get really good results you'd need some more changes to architecture and hyperparameters (see also https://deeplearning4j.org/visualization).
Can you share what kind of accuracy, F1 and if possible also MCC you're getting with your keras model?
treo
on 5 Jun 2018
@treo
In Keras, I'm observing below set of accuracy on 10-fold training set:
0.835
0.83375
0.835
0.82375
0.8475
0.85
0.835
0.83
0.81875
0.8425
I get similar accuracy everytime when I run Keras code.
And here's the score obtained after passing test set through the model:
Error: 0.4064310743808746 (Observed that this error rate lesser than or equal to training error rate which is the expected behavior)
Score: 0.8385
And here's the confusion matrix from Keras:
0 1
0 1560 35
1 288 117
Currently on a restricted network, so couldn't take snapshots for above.
I tried changing the splitter batch size and reduced the total batch count accordingly. But no luck. In fact, a lot of permutations and combinations tried, however outcome was same.
https://github.com/rahul-raj/Deeplearning4J/blob/master/src/main/java/DeepLearning4j.java
I will run DeepLearning4j UI on my local and will post the snap soon. Hopefully we can figure out from there.
rahul-raj
on 6 Jun 2018
@treo,
Here are the links to UI snapshots:
https://i.imgur.com/Rnha0S9.jpg
Sorry about the links instead of direct attachments.
Currently on restricted network and snaps taken using mob.
rahul-raj
on 7 Jun 2018
@treo
Here we go, UI snapshots from a training instance:
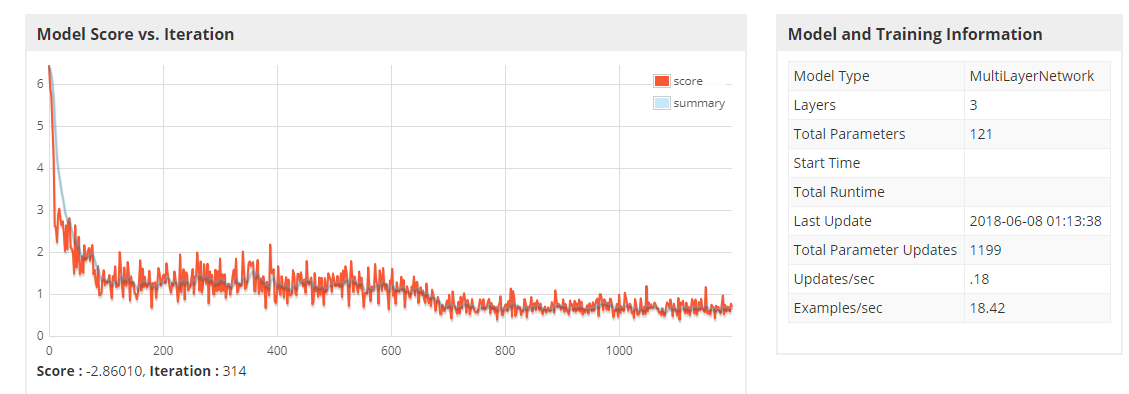

However observing some exception messages on console:
https://gist.github.com/rahul-raj/c9a25a0488ed2be83750fb9fbc3408dc
code:
https://github.com/rahul-raj/Deeplearning4J/blob/master/src/main/java/DeepLearning4j.java
rahul-raj
on 7 Jun 2018
@treo, @AlexDBlack
Found that I was not normalizing the data and may be because of that I was getting ZeroDirection gradient.
Changed the source code accordingly and the error is gone now. Ultimately changed the code in my other issue (5445) as well.
However, despite of all permutations and combinations of changing learning rate, weight distribution, batch sizes, split iterator batches etc, still observing the over-fitting. Checked Keras models for assigned weights and values and set in code accordingly. It didnt change the outcome either. There was not much config added to Keras, it was very basic and simple model. At this point, I'm stuck. I see that implementation looks same for both keras and DL4J, but not getting any clue from UI either.
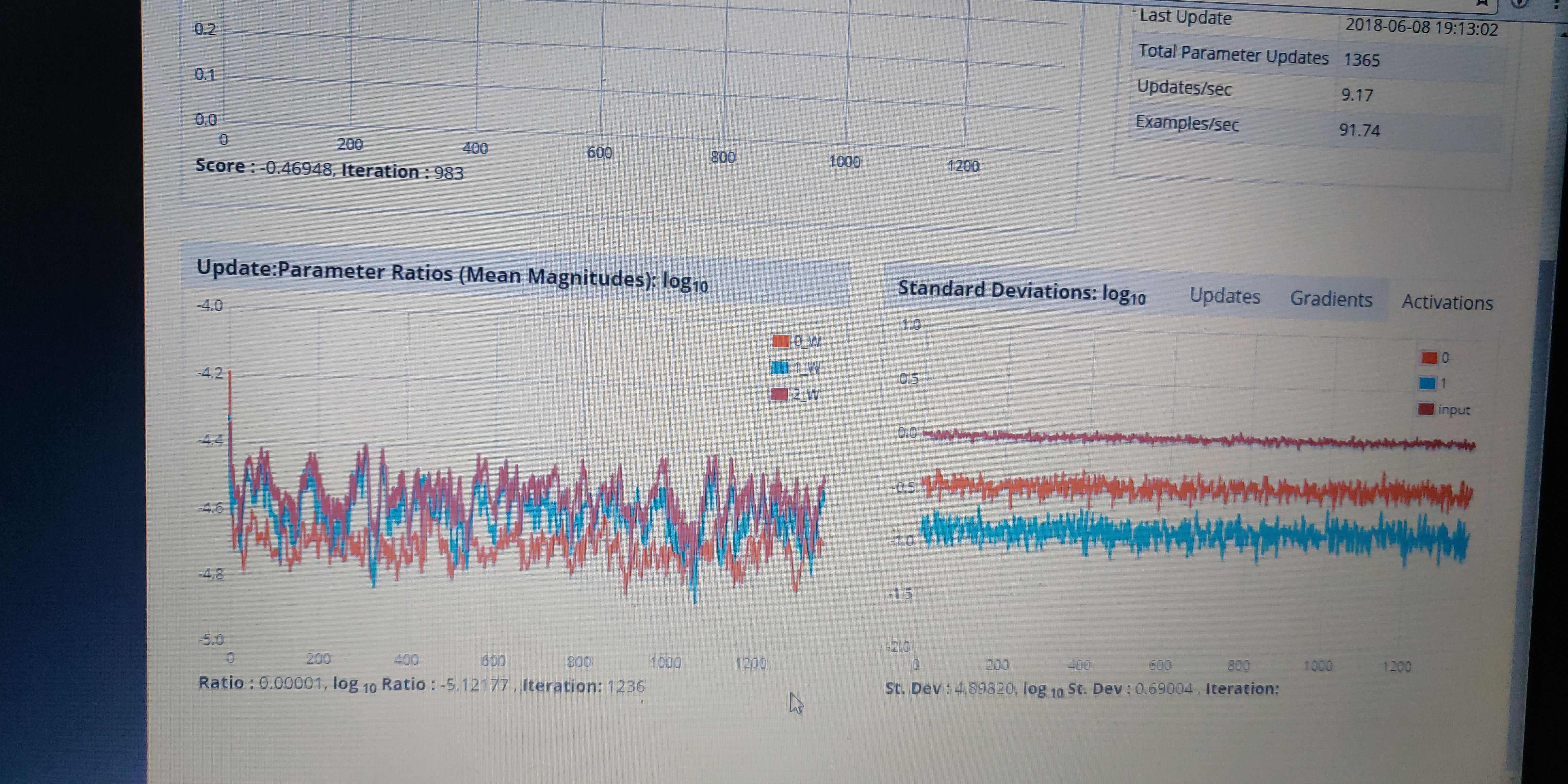
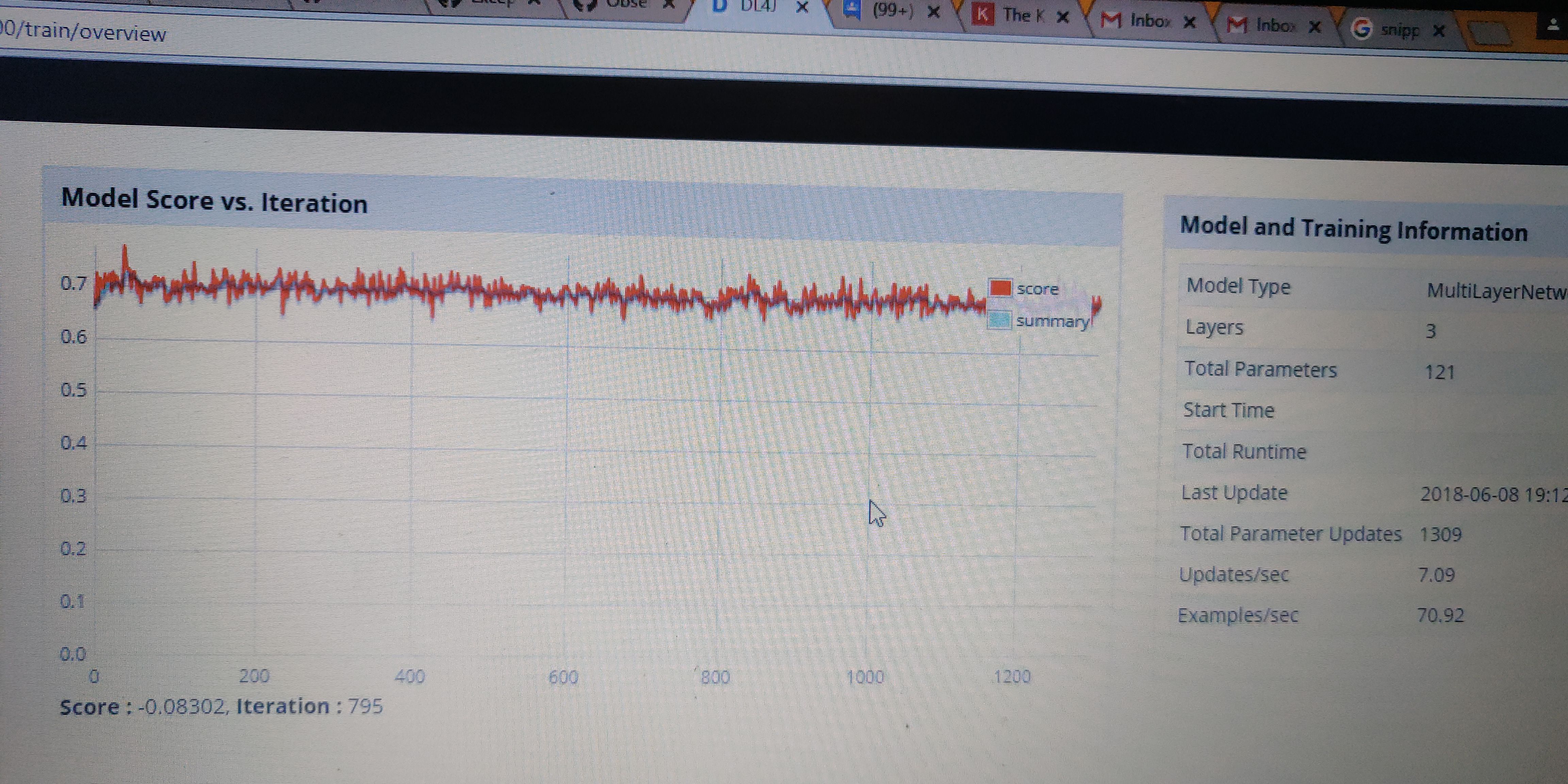
rahul-raj
on 8 Jun 2018
@treo @AlexDBlack
Done plenty of testing after yesterday's discussion. Here are the things which I have tried out:
1) Softmax with 2 inputs, LossMCXENT loss func -> Thanks to @treo for pointing out this. Softmax was certainly the last option in my mind, but data imbalance was the actual culprit here.
2) Changing learning rates alone -> Observed better results in higher LR in the order of 1e-2 for my use case. As soon as the output activation is changed and loss function is applied, changes in learning rate had big influence on results. I was observing an accuracy increase of 5-6%.
3) Different updaters with different learning rates -> adam, rmsprop, nesterovs (sgd with momentum) -> After a quick search, found that sgd with momentum would be best option and slight increase of accuracy is noticed while testing.
4) L2 regularization -> Optimal rate found to be 0.0005) for my use case.
5) Added another dense layer with 8 neurons. -> Not much of gain if layers are increased. But I just added one more deep layer.
6) Increase epochs and dropouts together. -> Increasing epochs from 100 to 2000 (with batchsize 10, totalBatches=1000) resulted in 1.6 million iterations. Further increase of Dropouts doesn't really helped out even though it's a lot of iterations. Just referred a forum post from Jeremy (fast.ai) where he suggests larger epochs with more dropouts (upto 0.7).
7) Increase/decrease epochs and learning rate together. ->
No noticeable changes here.
At the end, after all such permutations and combinations of trials, received an avg.accuracy of 85.5% throughout testing and seems consistent though (observed range: 84.8-86.3)
F1 score observed to be between 48-56%
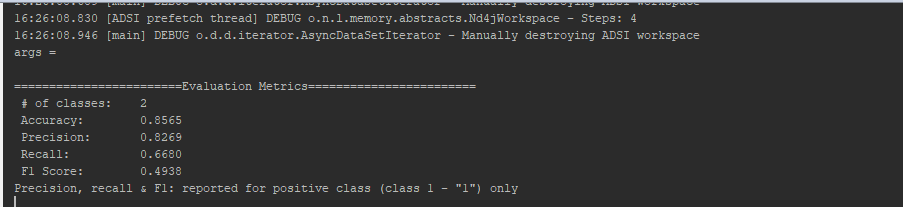

I'm closing this since the high variance has been stopped and observing a good accuracy overall.
Correct me if any of my above mentioned procedures are incorrect or if doesn't have any significance.
Accordingly, I will continue to try optimizing things, although it might be the case where I need more train data to get more accuracy. I hope you don't mind posting questions/comments here later if any. Thanks everyone!
rahul-raj
on 10 Jun 2018
This thread has been automatically locked since there has not been any recent activity after it was closed. Please open a new issue for related bugs.
![lock[bot] picture](https://avatars1.githubusercontent.com/in/6672?v=4&s=40) lock[bot]
on 21 Sep 2018
lock[bot]
on 21 Sep 2018
Related issues
 zzyxzz
·
5Comments
AlexDBlack
·
5Comments
zzyxzz
·
5Comments
AlexDBlack
·
5Comments
 atuzhykov
·
4Comments
atuzhykov
·
4Comments
 maxgfr
·
4Comments
maxgfr
·
4Comments
 jesuino
·
5Comments
jesuino
·
5Comments